
『小説家になろう』全作品分析レポート ~ジャンルについて~

今回はジャンルの割合比較を行う。
『小説家になろう』というとファンタジーのイメージがあるが、実際はどうであるのか。
あらすじを分析する前にジャンルの割合比較を行い、他分析への影響を考察できるようにする。
【目次】
・はじめに
・目的
・分析方法
・先行研究について
・ジャンルの割合比較 ◀ 今回はココ
・あらすじ文字数・頻出単語比較
・『恋愛』ジャンル分析
・『ファンタジー』・『文芸』・『SF』ジャンル分析
・『総合』分析・『あらすじ』文字数分析
・小説内会話率の比較
・投稿年度から見るトレンド比較
・結論
・参考サイト
今回の目次は以下のようになっている。
【ジャンルの割合比較】
あらすじの分析を行う上で、各グループにおけるジャンルの構成割合を確認する。以下にグループ分けの基準を再掲する。メモなどで手元に書き留めていただけると、以降見やすくなるかもしれない。
何度も言うがこのグループ分けは作品の質に直接関係するものでは無い。
グループ1:100,000 pt以上
グループ2:100,000 pt未満、50,000 pt以上
グループ3:50,000 pt未満、10,000 pt以上
グループ4:10,000 pt未満、5,000 pt以上
グループ5:5,000 pt未満、500 pt以上
グループ6:500 pt未満
まずジャンルごとのグループ分布を確認する。上から順にグループ6、グループ5となる。

これが小説家になろうの闇であるというのか。
以下のようにグループ6とグループ5を除くと、まだ全体的な傾向が掴みやすくなった。
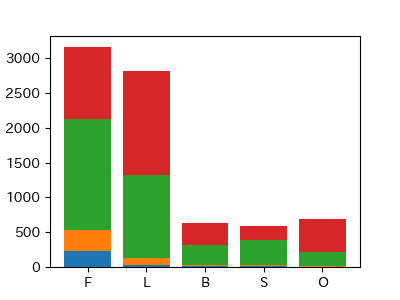
基本的にファンタジーあるいは恋愛のジャンルが人気であることが分かる。
全体のジャンル分布は下図のようになった。作品数は約72万作品である。

これでは『小説家になろう』ではなく『エッセイストになろう』ではないか。そんな風に思われるかもしれないが、安心してほしい。
ジャンルOの約四分の三が『ノンジャンル』だ。
これは2016年のジャンル再編成にて、既存作品がノンジャンルとされたことに起因すると考えられる。
しかしノンジャンルを除いたとしても、10万作品程がエッセイやその他ジャンルなどで投稿されている。これは『ファンタジー』や『文芸』に匹敵する数である。
恋愛に比べて文芸が多くなっているが、これは『ファンタジー』ジャンルでの競合を避けるために『アクション(文芸)』や『ヒューマンドラマ(文芸)』などに投稿するためであると考えられる。
グループ1のジャンル分布
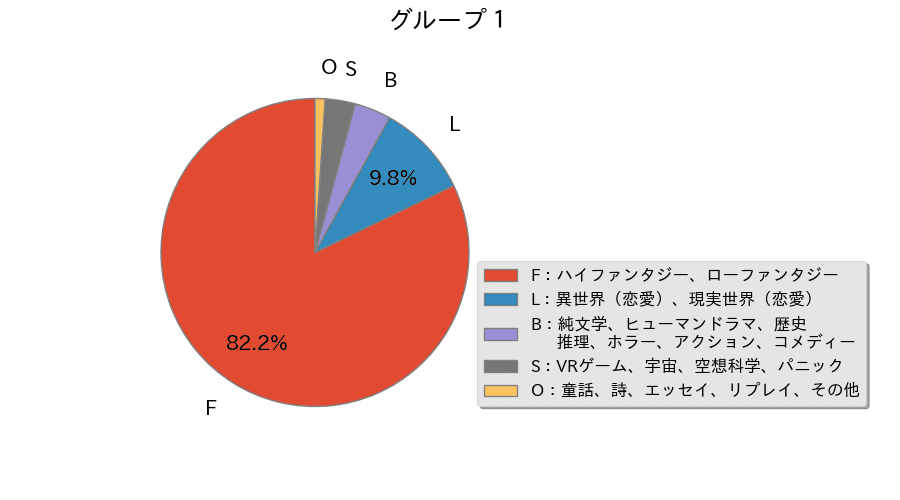
グループ1のジャンル分布は上図のようになった。
グループ1の作品数は286作品であり、『小説家になろう』における代表的な作品であることを踏まえると主流はやはり『ファンタジー』ジャンルであることが分かる。
『文芸』では『淡海乃海 水面が揺れる時』などの歴史モノが入る他、コメディーやアクションで異世界モノ……これはファンタジーでは? といったものが入ってくる。ライトノベル的作品かライト文芸的作品かという観点で文芸ジャンルに入っているのかもしれない。
『恋愛』は3作品以外が異世界(恋愛)であり、ファンタジーを読む感覚のものが人気のようである。
グループ2のジャンル分布

グループ2のジャンル分布は上図のようになった。
『ファンタジー』が主流であることに変わりはないものの、『恋愛』が大きく割合を伸ばし、『文芸』、『SF』も割合を増やしている。
作品数は457作品と、一般に知れ渡っているかは微妙だが『小説家になろう』における代表的な作品と言えるだろう。
『SF』ジャンルでのメジャーな作品と言えばVRゲーム関連が思い浮かぶが、実際のところVRゲーム作品は全体で5,000作品程しかなく、絶対数の少なさが分布に影響を及ぼしていると考えられる。
VRゲーム作品が少ない理由としては、商業作品にてかなり有名なものがあり二番煎じ感が否めない事、無双するにしろスローライフするにしろ異世界モノとの差別化が難しい事が考えられる。
『僕と彼女と実弾兵器(アンティーク)』のような『宇宙』ジャンルの本格SFもいくつかこのグループに入ってくる。
グループ3のジャンル分布

グループ3のジャンル分布は上図のようになった。
『恋愛』ジャンルが『ファンタジー』ジャンルに迫っていき、全体的に他ジャンルも割合を増やしている。
作品数は3,645作品と多く、日間ランキングに何度か載ったことのある作品など、ある程度『小説家になろう』で読んできた人であれば見覚えがある作品がちらほらと出始める。
大手レーベルでないものが多いが、書籍化しているものも多く見られた。
エッセイからも『読み専が紹介する『なろうお気に入り作品』』や小説の書き方指南系が入ってくるようになり、テンプレから外れた作品も目立ち始めるグループとなっている。『SF』ジャンルの相対的な割合からも、グループ3の多様性が伺えるだろう。
また、日間ランキングに何度も載っているような連載が始まったばかりの人気作も多く見られる。
グループ4のジャンル分布
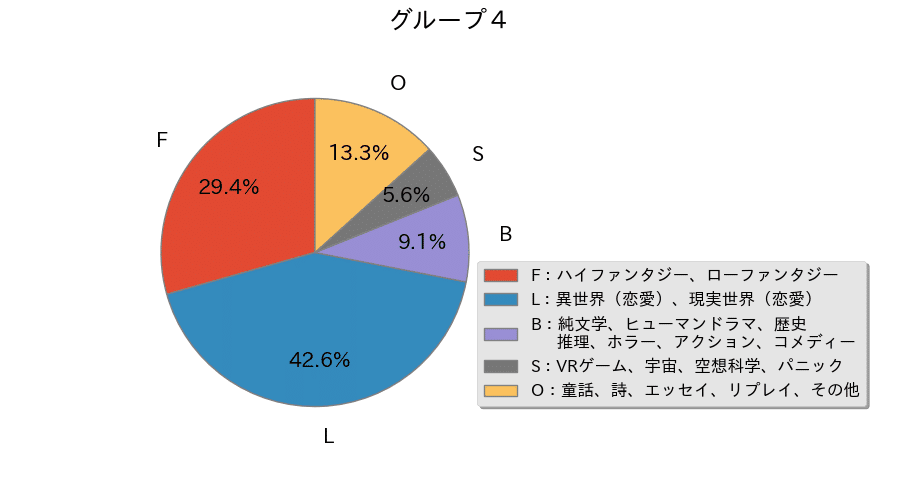
『恋愛』ジャンルが『ファンタジー』ジャンルよりも多くなり、Oに位置するジャンルが大きく割合を増やしている。全作品数は3,510作品と、ポイント範囲が狭くなるにも関わらず多くの作品が位置している。
5,000 pt以上ということで日間ランキングなどで一時的に注目された、あるいは本当に注目され始めたばかりという小説が多く、短編も多くこのグループに属している。
ここまで、『恋愛』ジャンルは『ファンタジー』と比較して低いポイントのグループに位置しているが、これは主に男性向け女性向けで読者が分かれるからだと考えられる。
『ファンタジー』に比べて『恋愛』は対象の性別がかなりくっきりと分かれることが多く、読者の減少があるのではないか、ということである。
実際その部分をクリアした、男女共に読めるような『恋愛』ではなく『ファンタジー』や『悪役系』などの要素をメインに据えた作品が人気であると言えるだろう。これに関しては仮説の域を出ないので次回以降に引き継ぐ。
グループ5・6のジャンル分布


グループ5でも『恋愛』ジャンルと『ファンタジー』ジャンルの逆転が起こっていることが分かる。
グループ5は24,972作品、グループ6は683,388作品である。
グループ5と6の違いとして、継続して投稿されているか、というものは大きいと考えられる。
グループ5の作品には完結済みや10万字を超えるものも多く、傾向としては『ランキングにはあまり載らないが、徐々にファンがついている』ものになる。
『小説家になろう』はサーバー負荷の観点から投稿済み小説の削除が推奨されていない。
そのため、思いついたから投稿してみたけど、そこまで反応貰えないし飽きたからやめよう……といって埋もれていく作品がグループ6の大半を占めていると考えられる。
したがってグループ5はグループ4に比較的似た構成となり、逆に過去の埋もれた作品(つまりノンジャンルの作品)が多く残っているグループ6ではジャンルOの作品が多くなり、また新規参入の多い『ファンタジー』ジャンルの作品も多くなっていると考えられる。
グループ6での『文芸』が多くなっていることについても、『ファンタジー』ジャンルと同じように新規参入が多いジャンルであるからだと考えられる。
下図(再掲)で分かるように、全体的な作品数としては『文芸』ジャンルは『ファンタジー』ジャンルよりも多くなっているためだ。

今回のプロットに使用した、作品数と大ジャンルのデータを以下に示す。

まとめ
グループ1やグループ2は『ファンタジー』で占められており、グループ4やグループ5では『恋愛』が『ファンタジー』よりも多くなる現象が起きている。
また、『文芸』はある程度安定した推移を見せており、グループ6でその割合を多く伸ばしている。
『SF』は基本的に作品数がかなり少なく、グループ3にある程度集まっている。
上記の結果を受け、下記の仮説を立てた上で『あらすじ』の分析を行う。
・『なろうテンプレ』に沿わない個性ある作品はグループ3で停滞する
・書籍化は基本的にグループ3以上が大半を占める
・グループ1、2はジャンルを問わず『ファンタジー』色が強く出る
・グループ3、4、5の『恋愛』ジャンルでは恋愛色が強くなる
【以下蛇足】
個人的に『ファンタジー』ジャンルの競合を避けるために他ジャンルで投稿するってあまり意味が無いなと感じていて、それする位なら恋愛色やVRMMO要素などを組み込んで恋愛あるいはSFで投稿した方がいいと思うんですよね。
また、これは分析データの無い所感なんですけども『恋愛』ジャンルって短くてもがっつり評価が入っていくと感じていて、流行の影響を受けやすいし流行が流れやすいジャンルなんじゃないかと思っています。
グループ3に抜けることを考えると流行りを組み込みつつ次の流行りそうな要素を入れた『恋愛』で出すのが一番なのでは? と。口で言うのはともかく書くのは無茶苦茶大変そうですが笑
そういえば次回についてですが、あらすじを解析するプログラム、4日間ずっと起動させ続けてもまだ三分の二が終わったくらいなんですよね……しかも表で出力されるだけなのでそこからの分析は人力という……
コードの書き方が悪いですし高速化できそうだとは思ったんですが、面倒でそのまま走らせ続けてしまっています笑
もしよかったらコピペでやってみてください笑
import os
import sys
import glob
import pandas as pd
import MeCab
from collections import Counter
from openpyxl import Workbook
os.chdir('C~~~~~~~~~~~~~~~~~~~')
def story_check():
All_files = []
All_nov_num = []
for f in glob.glob('six*.csv'):
p = os.path.split(f)[1]
All_files.append(os.path.splitext(p)[0])
for name in All_files:
print(name)
ana_file = name + '.csv'
All_nov_num.append(name)
print('Now loading...')
os.chdir(~~~~~~~~~~~~~~~~~~)
if os.path.isfile(ana_file) != True:
print('Check your filename!!')
sys.exit()
anadf = pd.read_csv(ana_file)
pop_word_dict = {}
nov_num = len(anadf)
All_nov_num.append(nov_num)
print('start')
print(str(nov_num) + '作品分析中')
count = 0
for i in range(nov_num):
stories = anadf.at[i,'story']
mecab = MeCab.Tagger ("-Ochasen")
node = mecab.parseToNode(stories)
app_word = []
while node:
if node.feature.split(",")[0] == "名詞":
word = node.surface
app_word.append(word)
elif node.feature.split(",")[0] =="動詞":
word = node.surface
app_word.append(word)
elif node.feature.split(",")[0] == "形容詞":
word = node.surface
app_word.append(word)
elif node.feature.split(",")[0] == "形容動詞":
word = node.surface
app_word.append(word)
elif node.feature.split(",")[0] == "接続詞":
word = node.surface
app_word.append(word)
#elif node.feature.split(",")[0] == "記号":
# word = node.surface
# app_word.append(word)
else:pass
node = node.next
count += 1
print(str(count) + '/' + str(nov_num) + '...')
set(app_word)
app_word_dict = dict.fromkeys(app_word,1)
pop_word_dict = dict(Counter(pop_word_dict) + Counter(app_word_dict))
pop_word_dict2 = pop_word_dict.copy()
for k,v in pop_word_dict2.items():
pop_word_dict[k] = round((pop_word_dict[k]) * 100 / nov_num, 2)
round(pop_word_dict[k],5)
if pop_word_dict[k] < 5:
del(pop_word_dict[k])
pop_word = list(pop_word_dict.items())
pop_word.sort(key=lambda x: x[1], reverse = True)
for i in range(len(pop_word)):
print(pop_word[i])
os.chdir(~~~~~~~~~~~~~)
wb = Workbook()
ws = wb.active
for i in pop_word:
ws.append(i)
wb.save(name + '_pop_word.xlsx')
print(All_nov_num)
story_check()
print('end')ちなみに出力はこんな感じで出ます。
