
AzureからGPTを使ってみる|LangGraphを使ってself-RAGをする

精度の高いRAGを実現する方法としてCRAGをやってみましたが、今回はまた別の方法、self-RAGを試してみます。
self-RAGの構造
LangGraphを利用してself-RAGを実装すると以下のような構造になります。
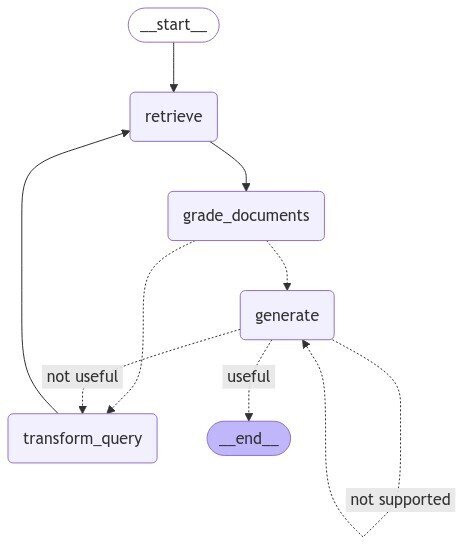
・retrieveノードで、回答に必要な情報を設定したドキュメントから取得します。
・grade_documentsノードで、取得したドキュメントでquestionに対して適正に回答できるかを評価します。ここで、十分だと判断されたらそのまま回答を生成するgenerateノードへ分岐します。十分でないと判断された場合は、transform_queryへ分岐します。
・transform_queryノードは、最初に与えられたquestionをRAGに適した形にre-writeするノードです。再生成されたquestionから再びReterieveノードでドキュメントを取得します。
・generateノードで、web検索と最初にドキュメントから取得した情報を使って、final answerを生成します。
生成された回答をさらに検証して、質問に対して回答が適正であると判断されれば終了、ハルシネーションを含むと判断されれば、再びgenerateノードへ、回答が質問を適切に解決できないと判断されればretrieveノードへ誘導されます。
*注意点として、こういった巡回型のグラフを構成すると質問によっては、無限ループすることがあります。今回は実装しませんが、stateに何回ループしたらループを抜け出すというロジックを入れた方が安全です。
self-RAGの実装
ということで、公式のチュートリアルを参考に(ほぼそのまま)実際のコードを書いてみたいと思います。
今回使用したライブラリーは以下になります。
#langchain -chroma=0.1.4
#langchain -core=0.3.15
#langchain -community=0.3.7
#langchain -text-splitters=0.3.0
#langgraph =0.2.50
#langchain =0.3.7
#langchain -openai=0.2.6
LLM、embeddingの定義
from langchain_openai import AzureOpenAIEmbeddings
from langchain_openai import AzureChatOpenAI
from dotenv import load_dotenv
import os
# OpenAI APIキーの設定
dotenv_path = ".env"
load_dotenv(dotenv_path)
os.environ["AZURE_OPENAI_API_KEY"] = os.getenv("AZURE_OPENAI_API_KEY")
os.environ["AZURE_OPENAI_ENDPOINT"] = os.getenv("AZURE_OPENAI_ENDPOINT")
os.environ["AZURE_OPENAI_API_VERSION"] = os.getenv("AZURE_OPENAI_API_VERSION")
llm = AzureChatOpenAI(
api_version=os.getenv("AZURE_OPENAI_API_VERSION"),
azure_deployment="gpt-4o-mini",# azure_deployment = "deployment_name"
verbose=True
)
embed = AzureOpenAIEmbeddings(
model = 'text-embedding-ada-002',
)独自データの設定(いつも通りjojoについてのドキュメントを使用します。)
from langchain_text_splitters import MarkdownHeaderTextSplitter
from langchain_community.vectorstores import Chroma
# Load example document
with open("jojo.md") as f:
state_of_the_union = f.read()
# Markdown見出しで文章を分割します
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
("####", "Header 4"),
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on,
strip_headers = False #コンテンツび分割されるヘッダーを含めるかどうか
)
md_header_splits = markdown_splitter.split_text(state_of_the_union)
documents = md_header_splits
# VectorStoreの準備
vectorstore = Chroma.from_documents(
documents,
embedding=embed,
#collection_name="example_collection",
#persist_directory="./chroma_langchain_db", # Where to save data locally, remove if not neccesary
)
# Retrieverの準備
retriever = vectorstore.as_retriever()取得したドキュメントが質問に関連しているかを「yes」または「no」で評価するためのモデル
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
# Data model
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM with function call
structured_llm_grader = llm.with_structured_output(GradeDocuments)
#prompt 取得したドキュメントとユーザーの質問との関連性を評価
system = """You are a grader assessing relevance of a retrieved document to a user question. \n
It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
question = "agent memory"
docs = retriever.get_relevant_documents(question)
doc_txt = docs[1].page_content
print(retrieval_grader.invoke({"question": question, "document": doc_txt}))RAGの質問応答タスクのためのチェーン
### Generate
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
#prompt
prompt = hub.pull("rlm/rag-prompt")
#print(prompt)
#template="You are an assistant for question-answering tasks.
# Use the following pieces of retrieved context to answer the question.
# If you don't know the answer, just say that you don't know.
# Use three sentences maximum and keep the answer concise.\nQuestion: {question} \nContext: {context} \nAnswer:"
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)生成された回答が取得されたドキュメントに基づいているか(「幻覚」を含んでいないか)を判断するためのモデル
### Hallucination Grader
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: str = Field(
description="Answer is grounded in the facts, 'yes' or 'no'"
)
# LLM with function call
structured_llm_grader = llm.with_structured_output(GradeHallucinations)
# Prompt
system = """You are a grader assessing whether an LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 'yes' or 'no'. 'Yes' means that the answer is grounded in / supported by the set of facts."""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
]
)
hallucination_grader = hallucination_prompt | structured_llm_grader
hallucination_grader.invoke({"documents": docs, "generation": generation})回答が質問に適切かどうかを判断します。
### Answer Grader
#data model
# Data model
class GradeAnswer(BaseModel):
"""Binary score to assess answer addresses question."""
binary_score: str = Field(
description="Answer addresses the question, 'yes' or 'no'"
)
# LLM with function call
structured_llm_grader = llm.with_structured_output(GradeAnswer)
# Prompt
system = """You are a grader assessing whether an answer addresses / resolves a question \n
Give a binary score 'yes' or 'no'. Yes' means that the answer resolves the question."""
answer_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "User question: \n\n {question} \n\n LLM generation: {generation}"),
]
)
answer_grader = answer_prompt | structured_llm_grader
answer_grader.invoke({"question": question, "generation": generation})質問が適切にドキュメントを取得できるように、質問の再構成を行うモデル
### Question Re-writer
# Prompt
system = """You a question re-writer that converts an input question to a better version that is optimized \n
for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning."""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Here is the initial question: \n\n {question} \n Formulate an improved question.",
),
]
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"question": question})グラフ、ノード、エッジを定義していきます
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]### Nodes
from pprint import pprint
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.get_relevant_documents(question)
return {"documents": documents, "question": question}
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("---CHECK DOCUMENT RELEVANCE TO QUESTION---")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
continue
return {"documents": filtered_docs, "question": question}
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
return {"documents": documents, "question": better_question}
### Edges
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("---ASSESS GRADED DOCUMENTS---")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print(
"---DECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY---"
)
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.binary_score
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"graph build
from langgraph.graph import END, StateGraph, START
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
# Build graph
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()それでは、質問をしてみます。
question = "波紋と幽波紋(スタンド)の関係性を教えて"# Run
inputs = {"question": question}
for output in app.stream(inputs):
for key, value in output.items():
# Node
print(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
#print("\n---\n")
# Final generation
print(value["generation"])---RETRIEVE---
Node 'retrieve':
---CHECK DOCUMENT RELEVANCE TO QUESTION---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT RELEVANT---
---GRADE: DOCUMENT NOT RELEVANT---
---ASSESS GRADED DOCUMENTS---
---DECISION: GENERATE---
Node 'grade_documents':
---GENERATE---
---CHECK HALLUCINATIONS---
---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---
---GRADE GENERATION vs QUESTION---
---DECISION: GENERATION ADDRESSES QUESTION---
Node 'generate':
波紋と幽波紋(スタンド)は、どちらも「ジョジョの奇妙な冒険」における特殊能力ですが、波紋は呼吸法によって生命エネルギーを活性化させる技術であり、主にPart1とPart2で使用されます。一方、幽波紋(スタンド)は精神エネルギーを具現化した能力で、Part3以降の戦いの中心となります。波紋はスタンドに至るための手段とも考えられており、両者は同じ世界観の中で異なる役割を果たしています。