
ECサイトの売上は「クラスタリングと機械学習」で伸ばせるというお話

惠子は悩んでいた。
どれだけ悩んでも答えは出なかった。
ため息ばかりついて一向に仕事は前に進まない。
惠子の悩みをまとめると、以下になる
・女性向けの化粧品をオンラインで販売
・売上が横ばい続き。もっと商品のファンを増やし、売上を伸ばしたい!!
・どの商品を買うと、このサイトのファンになってくれるかを分析したいが、迷子になっている
そんなとき、救世主が現れた。
データ分析統括マネージャーの里見だった。
「とりあえず、どんなデータがあるか教えて」と里見は言った。
惠子はすぐにデータ概要を説明した。
• 顧客情報(user_list.csv)
• 顧客id
• 累積購入回数(決済ベース)
• 累積購入金額
→顧客が過去何回、合計いくら購入したのか、のデータ
• 6月の購買履歴(payment_log_202506.csv)
• 顧客id
• 購入日
• 購入商品名
• 購入金額
→顧客が6月中、いつ、何をいくら買ったのか、のデータ
「具体的に見せてくれる?」と里見が言ったので、惠子はpythonを用いてデータを見せた。
import pandas as pd
# データ読み込み
df_u = pd.read_csv("user_list.csv")
df_p = pd.read_csv("payment_log_202506.csv")
display(df_u.head())
display(df_p.head())
「これならクラスタリングが使える」
里見はデータを見て、何度も頷いた。
「クラスタリング?」と惠子は首をかしげる。
「これを見て」と里見はパソコンを開く

「顧客を3つのクラスター(=固まり)に分類しているのが分かるだろ」
「本当ですね。何だが見やすくなった」
「今回はサイトのファンを作ることが目的だから、『ミドルユーザーを一人でも多く、ヘビーユーザーに変える』ことが目標になる」
「なるほど」
「そのために、まずは今のデータから顧客のクラスタリングを行う」
「よろしくお願いします!」
クラスタリングを行うための、前処理を以下に示す。
import scipy.stats
# 顧客を6月購入者に絞るため、顧客情報と購買ログと結合
## 6月購入者を抽出
df_p6 = df_p[['user_id']].drop_duplicates()
df_up = pd.merge(df_u,df_p6,how='inner',on='user_id')
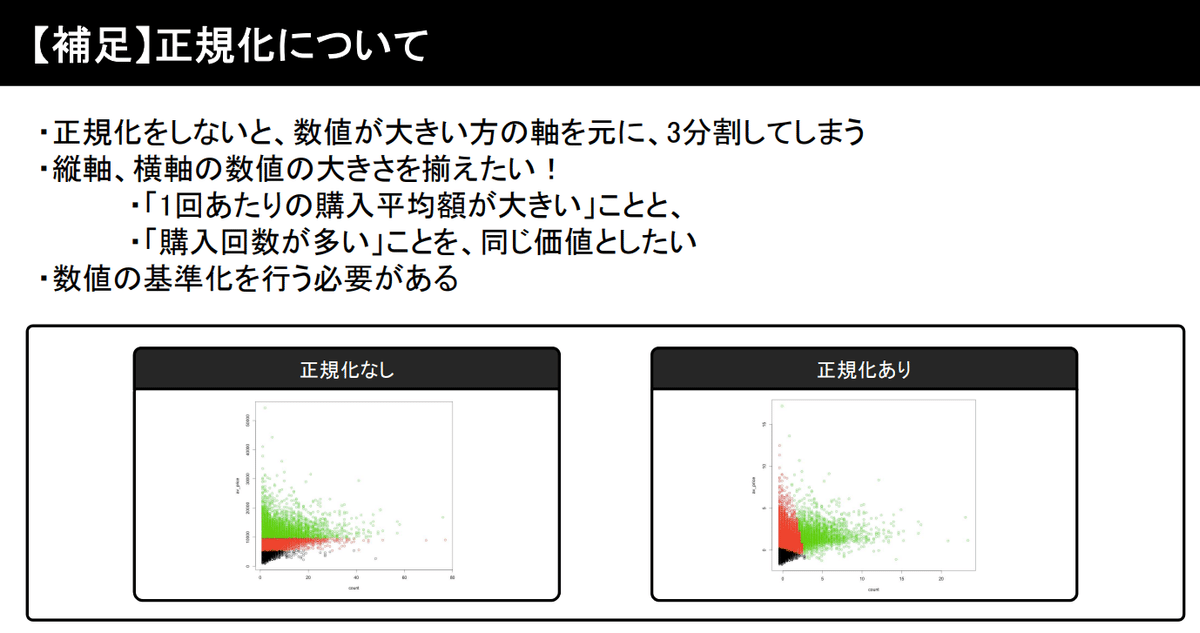
#「1回あたりの購入単価」列作成
df_up['av_price'] = df_up['total_price'] / df_up['count']
# 正規化
## count列、av_price列の基準を揃える->正確にクラスタリングするために必要
## 平均0・分散1に正規化(標準化)
df_up['av_price_stan'] = scipy.stats.zscore(df_up['av_price'])
df_up['count_stan'] = scipy.stats.zscore(df_up['count'])
display(df_up)
続いて、実際にクラスタリングを行う。
ここではk-meansと呼ばれるアルゴリズムを用いる
from sklearn.cluster import KMeans
from matplotlib import pyplot as plt
# クラスタリング
kmeans = KMeans(n_clusters=3, max_iter=30, init="random")
## n_clusters: クラスタの数 max_iter: 学習のループ回数 init: 平均の初期値の決め方
df_up['cluster'] = kmeans.fit_predict(df_up[['av_price_stan','count_stan']])
# グラフで可視化
## 色指定
colors = {0:'red',1:'blue',2:'green'}
df_up['color'] = df_up['cluster'].apply(lambda x:colors[x])
## 項目指定
x = df_up['count']
y = df_up['av_price']
label = df_up['cluster']
color = df_up['color']
## 図示
plt.scatter(x,y,color=color,label=label,alpha=0.5,marker="o",s=15)
plt.xlabel('count')
plt.ylabel('av_price')
plt.show()
# クラスター人数を把握
df_up.groupby(['cluster','color'])['user_id'].agg('count').reset_index()\
.rename(columns={'user_id':'count_user_id'})

「今回だと、青がヘビーユーザー、緑がミドルユーザーですね」
「ミドル(緑)をヘビー(青)に変えるために、機械学習を用いる」
「おお!ついにですね、待ってました!」
分析に用いているcsvファイルとpythonコードはページ最後に記載しております。
ここから先は
この記事が気に入ったらチップで応援してみませんか?