
かつてない精度での3Dコンテンツ自動生成、フェイスブックが研究成果を公開

Facebookは自社のブログにて3Dコンテンツの生成やオクルージョンに関する研究成果を公開しました。
この研究成果は米ワシントン州で開催されるカンファレンス「CVPR(Computer Vision and Pattern Recognition)」にて発表される予定のものです。
Facebookは「2D画像に表示される3Dオブジェクトの制作についての新たな手法提案なども含まれており、特にVR、ARのコンテンツ制作における障壁を除外するのに役立つ論文となっている」と述べています。
SynSin 空間の様子を推測し、見えない部分を自動生成する

「SynSin」は最先端のモデルであり、単一のRGB画像を取得して、3Dスキャンを使用せず、異なる視点から同じシーンの新しい画像を生成する画期的な技術です。元の画像から様々な角度の空間の様子を推測し、新しい画像を作り上げています。360°動画や、3D写真の完成度向上への貢献が期待されます。
2Dから3Dへの再構成

3Dイメージの生成に、もう1つの新たな技術があります。この技術では人物の2D写真や動画から、3Dデータを再構成します。顔の特徴や表情はもちろん、指先の繊細な動きや衣類のひだなど、複雑なディテールも追加処理なしで3Dに変換します。

この技術は、1枚の画像から人物の3Dオブジェクトを生成する「PIFu」の手法がベースとなっています。第1レベルのネットワークでは、PIFu法と同様に低解像度の入力画像を利用することで人間の大域的な3次元構造を考慮しています。第2のネットワークでは、より解像度の高い1Kの入力画像を取り込み、詳細なディテールを解析しています。
細部にわたり、高品質な3D再構成は、よりリアルなVR体験の提供や、重要なアプリケーションの強化に役立つことが期待されます。
「あなたがここにいればいいのに」
文脈を意識したヒューマンジェネレーション。これは、1枚の写真からシーンのインタラクションの質と意味的な文脈を維持したまま、その場にいない人物を合成する技術です。
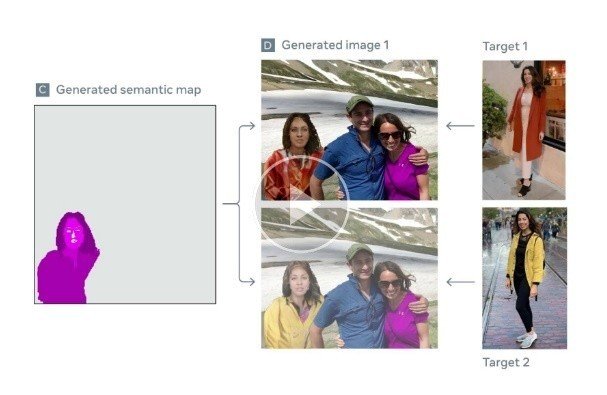
この手法ではまず、合成する先の画像を構成するデータを取得します。次に、合成したい形で人物のデータを生成します。合成先の画像構成に、その場にはいない人物の画像を取り込み、違和感のない新しいイメージを作ります。同技術を用いると人の髪や衣服など、パーツごとの入れ替えも可能です。
近年、遠隔地でのイベントや場所を超えたインタラクションへの関心が高まっていることから、この技術はビデオツールを使用する際に、人々がより自然に「同じ場所にいる」と感じやすくなったり、新しいAR体験を想像することができるかもしれません。