【Python】MP3から読み上げのテキスト書き出しメモ【Faster Whisper】

音声ファイルからのテキスト抽出
Faster Whisper
参考:PythonでFaster Whisperを使ってYoutube動画を簡単に文字起こしする方法
他にもさまざまなライブラリがテキスト抽出を可能にしているが、今回はこれを使う。
前提:Pythonインストール済み。VSCode使用。
***CUDAを使うので、NVIDIA製のGPUが必須
使用するライブラリ:Faster Whisper
pip install faster_whisperfrom faster_whisper import WhisperModel # WhisperModelを使うための準備
model = WhisperModel("large-v3", device="cuda", compute_type="float16")
AUDIO_FILE_NAME = "Speaking role of Samus Aran Prime.mp3"
segments, info = model.transcribe(
AUDIO_FILE_NAME,
beam_size=5,
vad_filter=True,
without_timestamps=True)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))


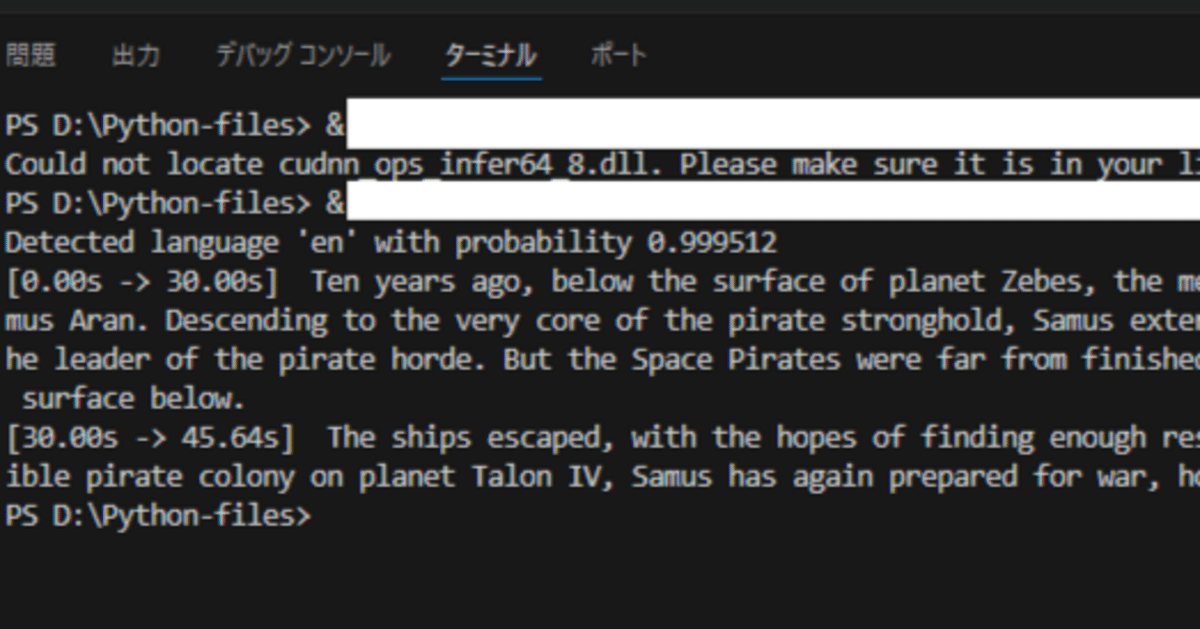
上記の例のように、今回使うFaster WhisperもCUDAとcuDNNというものが必要なのだがそのバージョンがCUDAとcuDNNとで対応してないといけない。
ダウンロードする。アカウントを作るしかないのでNvideaアカウントを作る。
CUDAはexe形式を進めてインストールして再起動。(展開先のファイルパスを覚えること)

cuDNNはZIPファイルなので展開し、中のbinフォルダをコピーする。

CUDAをインストールした先、binフォルダに先ほどコピーしたcuDNNのbinフォルダを置く。

これでエラー内容の、該当ファイルが存在しません!配置してください!が解消されるので再度pythonプログラムを実行する。
今回使用する音声ファイル:メトロイドプライムの没データ。サムス・アランの冒頭読み上げナレーション音声。
テキストが載っているので実際にどのくらいの精度で音声が抽出出来ているかわかる。


ここからテキストファイルに出力する場合は、参考サイトのようにTEXT_FILE_NAMEを定義して.txtに書き出す。
***一部の音声がテキストに抽出されていないが、囁き声や不明瞭な発音だと正しく抽出されない。今回だとマザーブレインの部分。