Local-LLM+LongLLMLingua, RAG series 3/n

RAGシリーズ3回目。
今回はLlamaindexでLongLLMLinguaを用いたRAGです。
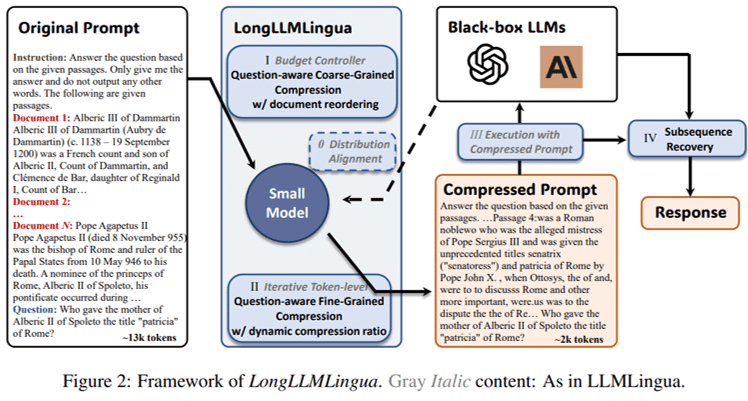
通常のRAGではpromptが長くなりがちで、計算コストが嵩む(ChatGPTなどを使用する場合は費用が嵩む)、性能が低下する(ex.:“Lost in the middle”)、などの課題が生じます。それらの課題を、適切にpromptを圧縮するLLMLinguaとRerankingなどを組み合わせることで克服する手法です。
0. 環境
OS:Windows
CPU:Intel(R) Core i9-13900KF
RAM:128GB
GPU:RTX 4090
1. text読込
今回はLongLLMLinguaの論文を用いました。
from llama_index.node_parser import SimpleNodeParser
from llama_index import SimpleDirectoryReader
path = r".\nlp\LongLLMLingua"
documents = SimpleDirectoryReader(path).load_data()
node_parser = SimpleNodeParser.from_defaults(chunk_size=256)
base_nodes = node_parser.get_nodes_from_documents(documents)2. LLMとembeddingのモデル指定
今回はLLMにZephyr-7B-βを4bit量子化し、embeddingにはBAAI/bge-small-en-v1.5を使用しました。
import torch
from transformers import BitsAndBytesConfig
from llama_index.llms import HuggingFaceLLM
from llama_index import ServiceContext
from llama_index.embeddings import resolve_embed_model
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
llm = HuggingFaceLLM(
model_name="HuggingFaceH4/zephyr-7b-beta",
tokenizer_name="HuggingFaceH4/zephyr-7b-beta",
context_window=2048,
max_new_tokens=512,
model_kwargs={"quantization_config": quantization_config},
generate_kwargs={"temperature": 0.1, "top_k": 50, "top_p": 0.95},
device_map="auto",
)
embed_model = resolve_embed_model("local:BAAI/bge-small-en-v1.5")
service_context = ServiceContext.from_defaults(
llm=llm, embed_model=embed_model, chunk_size=256
)3. index, retrieverの設定
from llama_index import VectorStoreIndex, ServiceContext
base_index = VectorStoreIndex(base_nodes, service_context=service_context)
base_retriever = base_index.as_retriever(similarity_top_k=5)4. LongLLMLinguaポストプロセスの設定
LlamaindexのLongLLMLinguaPostprocessorでLongLLMLinguaを実装することができます。
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.response_synthesizers import CompactAndRefine
from llama_index.indices.postprocessor import LongLLMLinguaPostprocessor
node_postprocessor = LongLLMLinguaPostprocessor(
instruction_str="Given the context, please answer the final question",
target_token=300,
rank_method="longllmlingua",
additional_compress_kwargs={
"condition_compare": True,
"condition_in_question": "after",
"context_budget": "+100",
"reorder_context": "sort",
"dynamic_context_compression_ratio": 0.3,
},
)5. 方法1. Step-by-Step
質問は下記のLongLLMLinguaの利点について聞いてみます。
question = "What are the advantages of LongLLMLingua?"retrieverの設定
retrieved_nodes = base_retriever.retrieve(question)
synthesizer = CompactAndRefine()
from llama_index.indices.query.schema import QueryBundle
new_retrieved_nodes = node_postprocessor.postprocess_nodes(
retrieved_nodes, query_bundle=QueryBundle(query_str=question)
)圧縮前後の比較
original_contexts = "\n\n".join([n.get_content() for n in retrieved_nodes])
compressed_contexts = "\n\n".join([n.get_content() for n in new_retrieved_nodes])
original_tokens = node_postprocessor._llm_lingua.get_token_length(original_contexts)
compressed_tokens = node_postprocessor._llm_lingua.get_token_length(compressed_contexts)
print(compressed_contexts)
print()
print("Original Tokens:", original_tokens)
print("Compressed Tokens:", compressed_tokens)
print("Comressed Ratio:", f"{original_tokens/(compressed_tokens + 1e-5):.2f}x")Original Tokens: 2586
Compressed Tokens: 330
Comressed Ratio: 7.84x
今回は引用する文章が短いので効果は限定的ですが、それでも1/8程度に圧縮されています。
LongLLMLinguaで圧縮されたpromptで質疑
response = synthesizer.synthesize(question, new_retrieved_nodes)
print(str(response))LongLLMLingua offers several advantages. It can achieve higher performance compared to prompts, while also reducing the latency of the end-to-end system. Additionally, LongLLMLingua compressed prompts can achieve these benefits with much fewer costs. It can also provide a performance boost of up to 17.1% over the original prompt with approximately 4 times fewer tokens as input to GPT-3.5-Turbo. Furthermore, LongLLMLingua can result in cost savings of $28.5 and $27.4 per 1,000 samples from the LongBench and ZeroScrolls benchmarks, respectively.
翻訳
LongLLMLingua にはいくつかの利点がある。プロンプトに比べて高いパフォーマンスを達成でき、またエンドツーエンドシステムの待ち時間を短縮できる。さらに、LongLLMLingua圧縮プロンプトは、より少ないコストでこれらの利点を達成することができます。また、GPT-3.5-Turboへの入力として、約4倍少ないトークンで、オリジナルのプロンプトと比較して最大17.1%の性能向上を実現できます。さらに、LongLLMLinguaは、LongBenchおよびZeroScrollsベンチマークで、それぞれ1,000サンプルあたり28.5ドルおよび27.4ドルのコスト削減につながります。
1/8に圧縮したpromptでも適切な回答が得られています。
計算コストで言えば1/60程度になるため、申し分ない結果のように感じます。引用する文章が長ければ長いほど、計算コストの恩恵も大きく、また回答精度も通常のRAGに対して優位性があるようなので、非常に優秀な手法のように思います。
6. 方法2. End-to-End
上記同様
retriever_query_engine = RetrieverQueryEngine.from_args(
base_retriever, node_postprocessors=[node_postprocessor]
)
response = retriever_query_engine.query(question)
print(str(response))LongLLMLingua offers several advantages. It can achieve higher performance compared to prompts, while also reducing the latency of the end-to-end system. Additionally, LongLLMLingua compressed prompts can achieve these benefits with much fewer costs. It can also provide a performance boost of up to 17.1% over the original prompt with approximately 4 times fewer tokens as input to GPT-3.5-Turbo. Furthermore, LongLLMLingua can result in cost savings of $28.5 and $27.4 per 1,000 samples from the LongBench and ZeroScrolls benchmarks, respectively.
LongLLMLingua にはいくつかの利点がある。プロンプトに比べて高いパフォーマンスを達成でき、またエンドツーエンドシステムの待ち時間を短縮できる。さらに、LongLLMLingua圧縮プロンプトは、より少ないコストでこれらの利点を達成することができます。また、GPT-3.5-Turboへの入力として、約4倍少ないトークンで、オリジナルのプロンプトと比較して最大17.1%の性能向上を実現できます。さらに、LongLLMLinguaは、LongBenchおよびZeroScrollsベンチマークで、それぞれ1,000サンプルあたり28.5ドルおよび27.4ドルのコスト削減につながります。
先ほどと同じ回答が得られました。
7. 比較例:通常のRAG
query_engine_base = RetrieverQueryEngine.from_args(
base_retriever, service_context=service_context
)
base_response = query_engine_base.query(question)
print(str(base_response))1. Higher performance: LongLLMLingua has demonstrated significant improvements in performance on three benchmarks, including NaturalQuestions, LongBench, and ZeroScrolls, with compressed prompts achieving higher performance at much lower costs compared to original prompts.
2. Lower cost: LongLLMLingua can provide cost savings of $28.5 and $27.4 per 1,000 samples from the LongBench and ZeroScrolls benchmarks, respectively, by compressing prompts.
3. Shorter latency: LongLLMLingua can significantly reduce end-to-end latency by 1.4x-3.8x when compressing prompts of approximately 10,000 tokens at compression rates of 2x-10x.
1. より高いパフォーマンス: LongLLMLinguaは、NaturalQuestions、LongBench、ZeroScrollsを含む3つのベンチマークにおいて、圧縮されたプロンプトが元のプロンプトに比べてはるかに低いコストで高いパフォーマンスを達成し、パフォーマンスの大幅な向上を実証しました。
2. 低コスト: LongLLMLinguaは、プロンプトを圧縮することで、LongBenchおよびZeroScrollsベンチマークから、それぞれ1,000サンプルあたり28.5ドルおよび27.4ドルのコスト削減が可能です。
3. 待ち時間の短縮: LongLLMLinguaは、約10,000トークンのプロンプトを2倍から10倍の圧縮率で圧縮した場合、エンドツーエンドの待ち時間を1.4倍から3.8倍と大幅に短縮することができます。
やはりLongLLMLinguaに対して計算時間は非常にかかったものの、優秀な回答です。
7. 参考
https://github.com/microsoft/LLMLingua/blob/main/examples/RAGLlamaIndex.ipynb