いつでも手軽に呼び出せる専門家_Local-LLM+RAG活用事例

下記で紹介したLlamaindexのRecursive Retriever + Node Referencesを用いたRAG活用事例です。
専門知識を気軽に活用したくても、大抵、専門知識を持った人材(以下、専門家)は高価で気軽に使えず、課題も多いと思います。
具体的には下記などがあります。
希少で活用頻度が低い
高価で予算が必要
レスポンスが悪い(コミュニケーションに時間を要す)
コミュニケーション難度が高い(質疑の歩留まりが悪い)
能力が不明瞭
発言のエビデンスが不明
発言の情報の精度が不明(うろ覚え、思い付きと熟考された案の区別がつかない)
ここで、必要な専門知識が論文や特許になっているような、所謂「研究者」の場合、LLM+RAGで代替可能な場面も多いのではないでしょうか。
今回はそういった場面で役に立つかもしれない、そんな活用事例です。
0. 環境
OS:Windows
CPU:Intel(R) Core i9-13900KF
RAM:128GB
GPU:RTX 4090
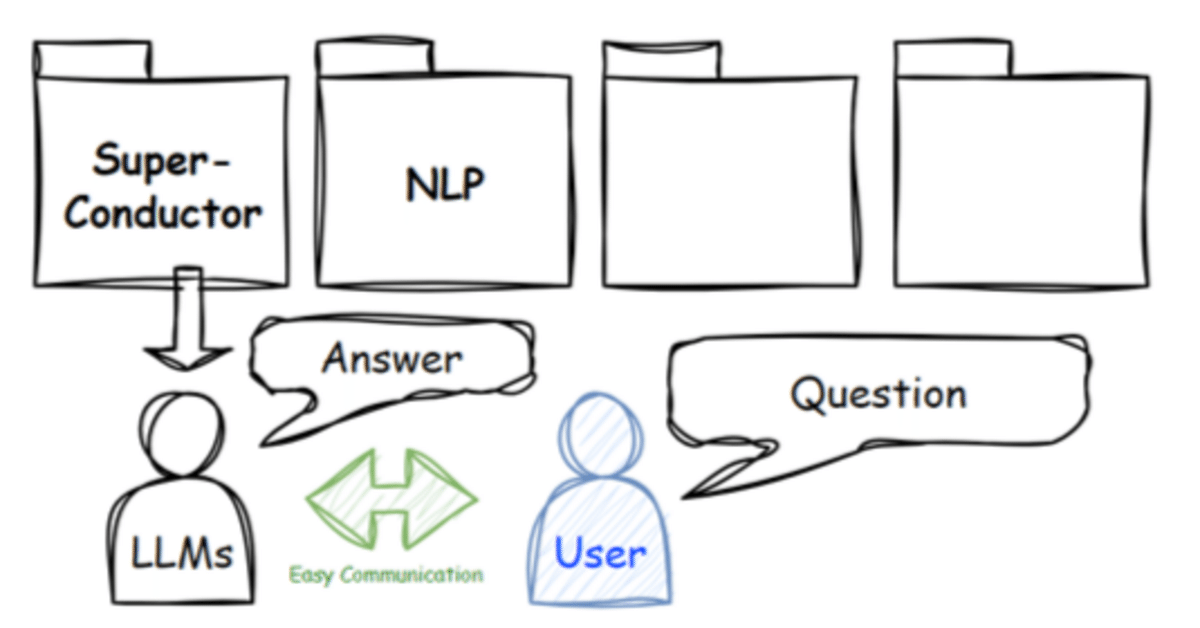
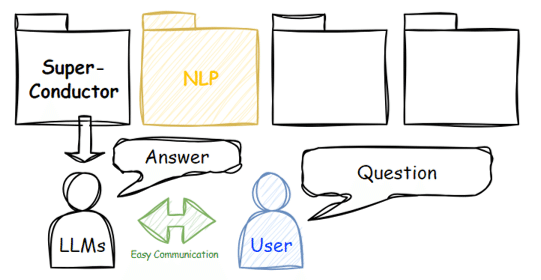
1. イメージ
今回の活用イメージは下図のように、求める専門知識(論文、特許)をジャンル毎にフォルダに入れておき、その専門知識に基づいた回答をLLMから取得します。
Userは任意にジャンル(フォルダ)を指定することができ、状況に合わせて選択します。今回はこの知識量が比較的コンパクトな状況を想定し、簡単に構築します。
人に対するLLMの利点は下記の通りです。
大抵のLLMモデルは多くの人より言葉遣いが上手で、わかりやすく、大抵の場合は前向きで、好き嫌いもありません。さらにはその性格もある程度調整可能です。いつでもあなたに協力的です。
2. 知識の収集
今回はarXivで取得したPDFをフォルダに格納しました。
検索した単語は"Superconductor"と”NLP"です。それぞれ別のフォルダに入れます。

3. PDF ⇒ index
フォルダに入っているPDFファイルのtext情報をindexにします。
embeddingに用いたモデルはBAAI/bge-small-en-v1.5、LLMのモデルはHuggingFaceH4/zephyr-7b-betaです。
コード一式は下記の通りです。内容は冒頭の記事のままです。
# フォルダのパス
path = r".\Superconductor"
# データの読み込み
from llama_index.node_parser import SimpleNodeParser
from llama_index import SimpleDirectoryReader,
documents = SimpleDirectoryReader(path).load_data()
node_parser = SimpleNodeParser.from_defaults(chunk_size=512)
base_nodes = node_parser.get_nodes_from_documents(documents)
# LLMモデルの指定
import torch
from llama_index.llms import HuggingFaceLLM
from llama_index import ServiceContext
llm = HuggingFaceLLM(
model_name="HuggingFaceH4/zephyr-7b-beta",
tokenizer_name="HuggingFaceH4/zephyr-7b-beta",
model_kwargs={"torch_dtype": torch.bfloat16},
generate_kwargs={"temperature": 0.1, "do_sample":True,},
device_map="auto",
)
service_context = ServiceContext.from_defaults(llm=llm, chunk_size=512)
from llama_index.embeddings import resolve_embed_model
embed_model = resolve_embed_model("local:BAAI/bge-small-en-v1.5")
service_context = ServiceContext.from_defaults(
llm=llm, embed_model=embed_model,
)
from llama_index import VectorStoreIndex, ServiceContext
base_index = VectorStoreIndex(base_nodes, service_context=service_context)
from llama_index.schema import IndexNode
from llama_index.retrievers import RecursiveRetriever
from llama_index.query_engine import RetrieverQueryEngine
sub_chunk_sizes = [128, 256]
sub_node_parsers = [
SimpleNodeParser.from_defaults(chunk_size=c) for c in sub_chunk_sizes
]
all_nodes = []
for base_node in base_nodes:
for n in sub_node_parsers:
sub_nodes = n.get_nodes_from_documents([base_node])
sub_inodes = [
IndexNode.from_text_node(sn, base_node.node_id) for sn in sub_nodes
]
all_nodes.extend(sub_inodes)
original_node = IndexNode.from_text_node(base_node, base_node.node_id)
all_nodes.append(original_node)
all_nodes_dict = {n.node_id: n for n in all_nodes}
vector_index_chunk = VectorStoreIndex(
all_nodes, service_context=service_context
)4. indexの保存
vector_index_chunk.storage_context.persist(f"{path}/vector_index_chunk")5. indexの読み込み
from llama_index import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir=f"{path}/vector_index_chunk")
vector_index_chunk = load_index_from_storage(storage_context, service_context=service_context)6. 質疑
クエリエンジンの設定
vector_retriever_chunk = vector_index_chunk.as_retriever(similarity_top_k=5)
retriever_chunk = RecursiveRetriever(
"vector",
retriever_dict={"vector": vector_retriever_chunk},
node_dict=all_nodes_dict,
verbose=True,
)
query_engine_chunk = RetrieverQueryEngine.from_args(
retriever_chunk, service_context=service_context
)超伝導のindexに対し、LaThH6が超電導を発現するか聞いてみます。
question1 = "What are the conditions under which LaThH6 develops superconductivity?"
response = query_engine_chunk.query(question1)
print(str(response))Based on the information provided, it is not explicitly stated whether LaThH6 develops superconductivity under high pressure. The text mentions that the stability and superconductivity of La xThyHz have been investigated under high pressure using first-principles calculations combined with evolutionary algorithms for structure search. The hydrogen-rich phases such as I4/mmm -La 3ThH 40, R¯3m-LaThH 20, and I4/mmm -LaTh 3H40 are found to be stabilized below 200 GPa and exhibit potential high-temperature superconductivity. However, the specific conditions under which LaThH6 develops superconductivity are not mentioned. Therefore, it is uncertain whether LaThH6 exhibits superconductivity under high pressure.
"LaThH6"の単語でしか聞いていないにもかかわらず、組成比が異なった状態に関しても回答してくれる点はポイント高いです。LLMが出現する前には想像もできませんでした。
2D トポロジカル系のハミルトニアンモデルの例を聞いてみます。
question2 = "Can you give some examples of Hamiltonian models for 2-dimensional topological systems?"
response2 = query_engine_chunk.query(question2)
print(str(response2))Yes, the paper discusses several Hamiltonian models for 2-dimensional topological systems, including the 2D Chern insulator, the 2D Kitaev topological superconductor, and the Checkerboard lattice hosting topological flat bands. These models are used to compute the boundary Green's functions using the Faddeev-LeVerrier algorithm, and the spectral properties at edges of these models exhibiting topological features like chiral edge states are studied.
保存した論文群に基づいて答えてくれています。
回答に用いたソースもすぐに明示可能なことも大きな強みです。
Node ID: 71b72414-2355-4185-9c2b-5dab07d0b9f9
Similarity: 0.8193906467620017
Text: In Sec. IV, we use some relevant model Hamiltonians for 2D topological systems as examples to compute steadily the FLA, first in a purely analytic probl…(以下略)
次にNLPのindexに対し、ChatGPTの金融関係の推論能力に関する研究内容を聞いてみます。
question3 = "What is the nature of ChatGPT's research on financial reasoning capabilities?"
response3 = query_engine_chunk.query(question3)
print(str(response3))ChatGPT's research on financial reasoning capabilities is an evaluation of its financial analysis skills using mock exam questions from the Chartered Financial Analyst (CFA) Program. The study assesses ChatGPT's performance in Zero-Shot (ZS), Chain-of-Thought (CoT), and Few-Shot (FS) scenarios. The research aims to estimate whether ChatGPT would have a chance at passing the CFA exams and outlines insights into potential strategies and improvements to enhance the applicability of LLMs in finance. The study is part of a comprehensive evaluation of both ChatGPT and GPT-4 on financial reasoning problems.
7. まとめ
手軽に専門知識を入れ替えて会話ができました。
ただこの方法では100本を超えるような文献を参照させることは現実的ではありません。より多くの情報量を扱う場合は工夫が必要かもしれません(例えばKGなど)。
希少性が低く、安価で、レスポンスも早くスマートで、エビデンスも明瞭で、能力や回答精度も比較的数値化しやすいLLMは理想の人材になるかもしれません。夢が広がりますね。