
Reranking, RAG series 6/n

RAGシリーズ6回目。
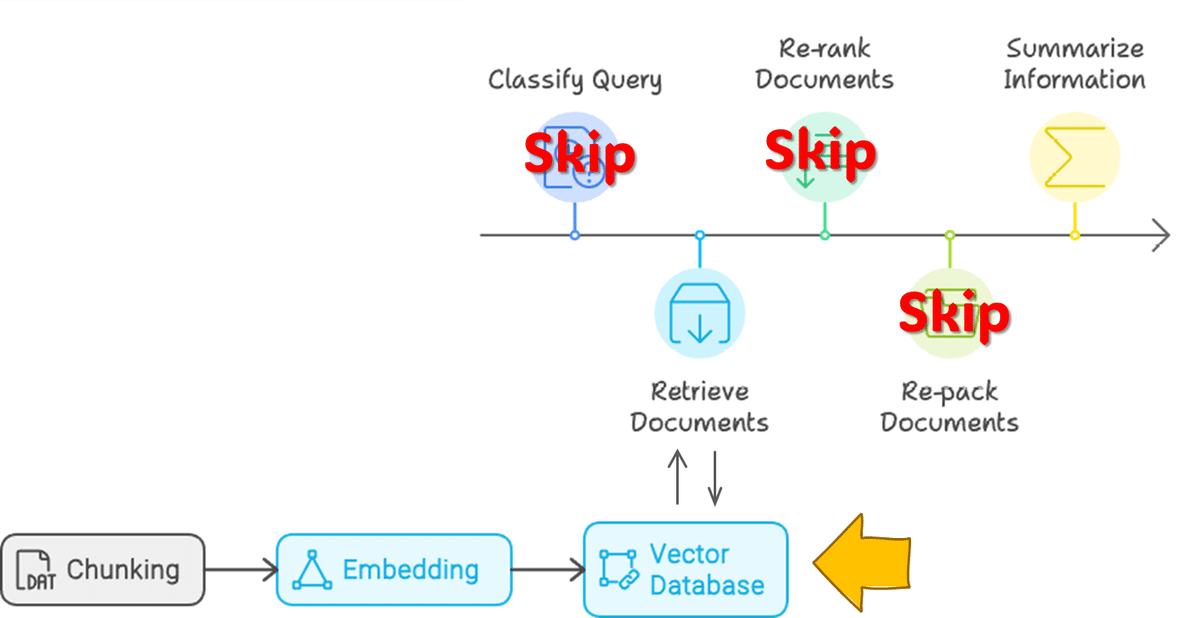
5回目でskipした下記フローのうち、Rerankingのメモです。

RAGのフローを5つのStepに分割しています。
① Query Classification:RAGの要否判断
② Retrieval:情報源の取得
③ Reranking:取得情報の順序最適化
④ Repacking:構造化
⑤ Summarization:要約
概要
上記フローの②、③のみです。
Dataはこの記事で紹介した、TOYOTAの出願特許の中で近年出願件数が増加している"Smart”や"Auto", "Management"などがkeywordとなるSystem関連topic群の特許を使用します。

実施内容
0. 環境
OS:Windows
CPU:Intel(R) Core i9-13900KF
RAM:128GB
GPU:RTX 4090 (24GB)
1. Retrieval Source
1-0. Data読込
# 特許Data読み込み(過去作成Dataframeを使用)
import pandas as pd
test_df = pd.read_pickle(f"{path}/test_df.pkl") #準備したデータ
# langchainのDataFrameLoaderでload
from langchain_community.document_loaders import DataFrameLoader
loader = DataFrameLoader(test_df, page_content_column="description") #明細文を使用
documents = loader.load()1-1. Chunking

from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
separators=[
"\n\n",
"\n",
" ",
".",
",",
"\u200b", # Zero-width space
"\uff0c", # Fullwidth comma
"\u3001", # Ideographic comma
"\uff0e", # Fullwidth full stop
"\u3002", # Ideographic full stop
"",
],
chunk_size=500,
chunk_overlap=20,
length_function=len,
is_separator_regex=False,
)
docs = text_splitter.split_documents(documents)1-2. Embedding

modelは性能そこそこ、sizeもコンパクトなBAAI/llm-embedderを使用
import langchain.embeddings
embedding = langchain.embeddings.HuggingFaceEmbeddings(
model_name="BAAI/llm-embedder"
)1-3. Vector DataBase
chromaを使用。
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(
documents=docs,
embedding=embedding
)2. LLM
modelの設定
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
import langchain.llms
model_id = "HODACHI/Llama-3.1-8B-EZO-1.1-it"
dtype = torch.bfloat16
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=dtype,)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=500
)
llm = langchain.llms.HuggingFacePipeline(
pipeline=pipe
)3. Retrieval

3-1. retriever : MMR(Maximal Marginal Relevance)
単純なretrieverを用いた場合の応答を確認します。
import langchain.chains
retriever=vectorstore.as_retriever(search_type="mmr", search_kwargs={"k": 5})
qa = langchain.chains.RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
chain_type='stuff',
)
answer = qa.invoke(query)回答:ECUのOTA(Over-the-Air)ソフトウェアに関連する技術は、車両のECUのソフトウェアを更新するために開発されたもので、車両に物理的にアクセスすることなく、リモートでECUの機能を改善したり、新しい車両制御機能を追加したりすることができます。これによりベンダーは、異なるネットワークに接続されたECUの機能を中断することなく、更新されたOTAソフトウェアを提供することができます。
3-2. +BM25 ensemble retriever
技術文書はkeywordの重要性が一般文書に比べて高いことが多く、keyword検索に強いBM25とのensemble, hybridで使用します。
from langchain.retrievers import BM25Retriever, EnsembleRetriever
bm25_retriever = BM25Retriever.from_documents(docs)
bm25_retriever.k = 5
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, retriever],
weights=[0.4, 0.6])
qa = langchain.chains.RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=ensemble_retriever)
answer = qa.invoke(query)回答:ECU OTAソフトウェア開発に関連する技術は、非侵襲的な方法でソフトウェアを更新することにより、ECUの機能を向上させたり、新たな車両制御機能を追加したりすることを主な目的としています。(中略)
変化するOTAソフトウェアに対応し、ベンダーの互換性を確保するシステムの能力は、自動車ソフトウェア管理における重要な進歩である。 これは、より効率的で信頼性の高い車両制御システムへの一歩を意味する。
4. Reranking

Reranker のmodelにBAAI/bge-reranker-v2-m3を設定
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-v2-m3', use_fp16=True)質疑に使う関数を定義
retrieverは 3-2. MMR+BM25 ensemble retriever を用います。
def rag_chromadb(query, chroma_db, doc_number, reranker):
# retrieve_doc_qdrant関数を使って関連文書を取得
reranked_documents = retrieve_reranked_doc_chromadb(query, chroma_db, doc_number, reranker)
# 再ランク付けされた文書から文書テキストを抽出
retrieved_documents = [doc for doc, _ in reranked_documents]
# 検索された文書を1つの文字列に結合
documents_text = "\n\n".join(retrieved_documents)
# prompt
messages = f"""You are an AI assistant with knowledge about U.S. politics, specifically the State of the Union Address.
Your user has asked a question related to the State of the Union Address. The relevant information from the transcript is provided below to supplement your existing understanding and knowledge.
In more than 500 words, use the provided information to better understand the context and provide a comprehensive answer to the user's question. If the question cannot be answered based on the given information, simply state that the information is not available in the provided context.
User's Question: {query}
Here are {doc_number} Relevant Information from the State of the Union Address Transcript:
{documents_text}
"""
# LLM応答
response_llm = llm.invoke(input=messages)
answer = response_llm.split("Answer:")[-1].strip()
prompt = messages.split("Answer:")[0].strip()
final_output_llm = f"Prompt:\n{prompt}\n\nModel Response:\n{truncate_response(query, answer, markers)}"
return final_output_llmdef retrieve_reranked_doc_chromadb(query, vector_db, doc_number, reranker):
# MMR+BM25のensembleで関連textを抽出
results = ensemble_retriever.get_relevant_documents(query)
# 検索された文書の関連性スコアを計算
pairs = [[query, result.page_content] for result in results]
scores = reranker.compute_score(pairs, normalize=True)
# Sort
# https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/reranker/README.md
sorted_results = sorted(zip(results, scores), key=lambda x: x[1], reverse=True)
# 検索された文書テキストとその関連スコアを抽出
retrieved_documents = [(result.page_content, score) for result, score in sorted_results[:doc_number]]
return retrieved_documentsmarkers = ["!assistant", "AI Assistant.", ")assistant", ".assistant", ". More", ". Read more", ".read more", ". more.", ".more.", "...", " Last updated:", " [2] ", ") ("]
def truncate_response(prompt, response, markers):
earliest_marker = None
earliest_index = len(response)
for marker in markers:
index = response.find(marker)
if index != -1 and index < earliest_index:
earliest_marker = marker
earliest_index = index
question_repeat_index = response.find(prompt, response.find(prompt) + len(prompt))
if question_repeat_index != -1:
response = response[:question_repeat_index].strip()
elif earliest_marker:
response = response[:earliest_index + 1].strip()
return response質疑
query = "What is the technology associated with electronic control unit (ECU) over-the-air (OTA) software developed for?"
response = rag_chromadb(query, vectorstore, 10, reranker)回答:自動車のECU(Electronic Control Unit:電子制御ユニット)のソフトウェアを更新するために開発されたOTA(Over-the-Air)ソフトウェアに関連する技術は、サーバー上のOTAソフトウェアが変更され、ベンダーが異なっても互換性を確保することができる。この技術により、OTA経由でECUのソフトウェア更新が可能になり、車両への物理的なアクセスを必要とせずに、機能の向上や新たな車両制御機能の追加が可能になります。
特に、異なるベンダーとサーバー間のソフトウェアの互換性という課題に対処しており、車載ネットワーク・システムの分野では極めて重要な進歩となっている。この技術は、車載ECUシステムのコンテキスト内で動作するように設計されており、制御にはOSEK/VDXなどの仕様を活用している。
また、ランク値に基づいてECU間で追加のソフトウェアコンポーネントを効率的に配置することもできる。
しかし、質問ではOTAソフトウェアアップデートの具体的な技術について尋ねており、提供されたコンテキストはこのトピックに直接関連しており、OTA経由で車両のECUソフトウェアをアップデートし、互換性と効率性を確保するための技術であることを示している。 提供された情報は、車両制御システム以外の目的でのECU OTAソフトウェアの開発には直接関係しない。 車載ECUの機能を向上させ、スムーズなアップデートを実現することに重点を置いている。 したがって、質問に対する回答は、この技術は自動車のECUソフトウェアを更新するために特別に開発されたものであり、OTA更新の互換性と効率性を確保するものである、ということになる。 この文脈では、ECU OTAソフトウェア技術の他の用途に関する情報は提供されていない。 あくまでも車載ネットワークシステムとECUに特化している。 このことから、回答は記述のままである。 文脈は非常に具体的であり、異なる解釈はできない。 回答は提供された情報をそのまま反映したものである。 車両のECUのOTAソフトウェアアップデートについてであり、互換性と効率性を保証するものである。
所感
rerankは計算costも殆ど変えることなく、応答精度を無難に向上させることができる硬い手法と思います。reranker modelも様々なものが登場し、手軽さも性能も増しています。
特に日本語対応のLLM modelが急増し性能も高まっている中、日本語を含めたmultilingualなreranker modelは大変助かりますね。