Local-LLM+Knowledge Graph+RAG, RAG series 2/n

RAG(検索拡張生成) システムシリーズ2回目。
今回はLlamaindexでKnowledge Graph(KG)を用いたRAGです。
KGは似た用語でKnowledge Base(KB), Concept Graph(CG)などがありますが、ざっくりと知識をグラフにしたものです。その利点はデータの管理が楽で、新しい知識を追加し続けることができ、情報のソース等のメタデータも取り込むことが可能であることだと思います。
一つの文献を情報源に用いるのではなく、様々なソース(論文、特許、ニュース)から得られる知識を一つのKGに追加していくことで、複数の情報源に基づいた会話が可能になります。さらにはその知識は定期的にアップデート可能で、会話で用いた情報のソースも説明可能、と優秀なツールです。
0. 環境
OS:Windows
CPU:Intel(R) Core i9-13900KF
RAM:128GB
GPU:RTX 4090
1. text読込
今回はLlamaindexのpaul_graham_essayのデータを用いました。
from llama_index import SimpleDirectoryReader
Reader = SimpleDirectoryReader(input_dir=path) #pathは任意に設定
documents = Reader.load_data() 2. LLMのモデル指定
今回もZephyr-7B-βを使用しました。
import torch
from llama_index.llms import HuggingFaceLLM
from llama_index import ServiceContext
llm = HuggingFaceLLM(
model_name="HuggingFaceH4/zephyr-7b-beta",
tokenizer_name="HuggingFaceH4/zephyr-7b-beta",
context_window=2048,
max_new_tokens=512,
model_kwargs={"torch_dtype": torch.bfloat16},
generate_kwargs={"temperature": 0.1, "do_sample":True,},
device_map="auto",
)
service_context = ServiceContext.from_defaults(llm=llm, chunk_size=256)3. REBELによる関係性抽出
textから各項目とその関係性の抽出に、今回はREBELを使用しました。
from transformers import pipeline
triplet_extractor = pipeline('text2text-generation', model='Babelscape/rebel-large', tokenizer='Babelscape/rebel-large')
def extract_triplets(input_text):
text = triplet_extractor.tokenizer.batch_decode([triplet_extractor(input_text, return_tensors=True, return_text=False)[0]["generated_token_ids"]])[0]
triplets = []
relation, subject, relation, object_ = '', '', '', ''
text = text.strip()
current = 'x'
for token in text.replace("<s>", "").replace("<pad>", "").replace("</s>", "").split():
if token == "<triplet>":
current = 't'
if relation != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(),'tail': object_.strip()})
relation = ''
subject = ''
elif token == "<subj>":
current = 's'
if relation != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(),'tail': object_.strip()})
object_ = ''
elif token == "<obj>":
current = 'o'
relation = ''
else:
if current == 't':
subject += ' ' + token
elif current == 's':
object_ += ' ' + token
elif current == 'o':
relation += ' ' + token
if subject != '' and relation != '' and object_ != '':
triplets.append((subject.strip(), relation.strip(), object_.strip()))
return triplets4. LlamaindexのKnowledgeGraphIndex
LlamaindexのKnowledgeGraphIndexに上記で設定したextract_tripletsを渡してQAに用いるindexを作成します。Llamaindex、ほんと便利。
from llama_index import KnowledgeGraphIndex
index = KnowledgeGraphIndex.from_documents(
documents,
kg_triplet_extract_fn=extract_triplets,
service_context=service_context,
)5. QA
response = index.as_query_engine().query("Tell mi about YC?")
print(response)YC, also known as Y Combinator, is a startup accelerator program based in Mountain View, California. It provides seed funding, mentorship, and networking opportunities to early-stage startups in exchange for equity. YC has helped launch numerous successful companies, including Airbnb, Dropbox, and Stripe. The program lasts for three months, during which time the startups receive guidance and resources to help them grow and prepare for further funding rounds. YC also hosts Demo Days, where the startups present their companies to a large audience of investors and potential partners.
小ネタ. 和訳
m2m100_1.2Bを使って日本語に翻訳します。
m2m100はサイズの割に本当に優秀な翻訳モデルですね。DeepLには劣りますが。
from transformers import pipeline, AutoModelForSeq2SeqLM, AutoTokenizer
import torch
translator = pipeline('translation', 'facebook/m2m100_1.2B', src_lang='en', tgt_lang="ja",
torch_dtype=torch.bfloat16, device_map="auto")
ja_response = translator(response.response, max_length=400)
print(ja_response[0]['translation_text'])YCは、Y Combinatorとも呼ばれ、カリフォルニア州マウンテンビューに拠点を置くスタートアップアクセラレータープログラムで、初期段階のスタートアップに資産と引き換えに種子資金、メンターシップ、ネットワークの機会を提供しています。YCはAirbnb、Dropbox、Stripeを含む数多くの成功した企業を立ち上げてきました。このプログラムは3ヶ月間、スタートアップが成長し、さらなる資金調達の準備を支援するためのガイドラインとリソースを受け取ります。YCはまた、スタートアップが投資家や潜在的なパートナーの広い観客に企業を紹介するデモデーデーを開催しています。
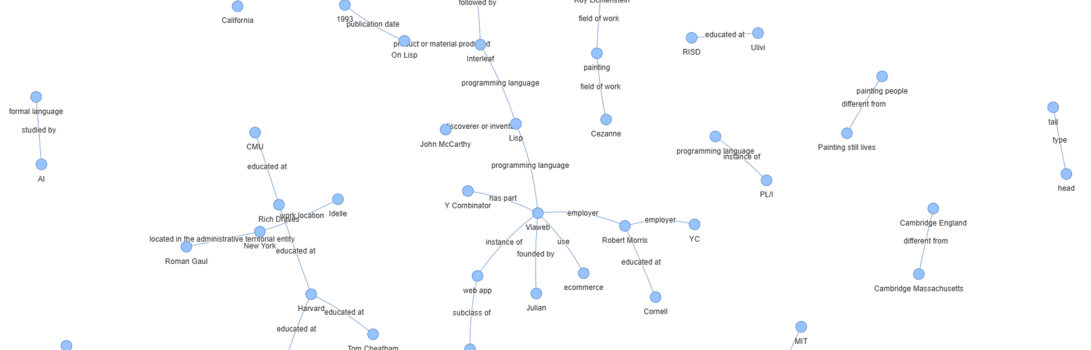
6. Visualise
一応、KGを可視化です。
from pyvis.network import Network
g = index.get_networkx_graph()
net = Network()
net.from_nx(g)
net.show("KG.html")