
Ferret:Appleの画期的な多モーダル大規模言語モデルの登場

2022年12月14日、Appleは「Ferret」という多モーダル大規模言語モデルを発表しました。このモデルは、画像の精確な識別と記述、さらには画像内の様々な要素の識別と定位能力を持っています。その革新的な特徴と幅広い応用可能性を詳しく解説します。
GitHub: Ferretの公式GitHubページ
Ferretの機能と特性
多モーダル理解
画像とテキストの統合: 画像(視覚情報)とテキスト(言語情報)を同時に処理し、複雑な関係を理解。
空間指代理解: 画像内の特定領域を識別し、その意味を理解。形状や大きさが異なる領域も識別可能。
複雑なテキスト記述の理解
多様な記述形式の対応: 具体的、抽象的な記述を問わず、幅広いテキスト記述を解釈。
開放語彙記述の精密定位: テキスト記述に基づき、画像内の対象物または領域を正確に特定し、マーク。
混合領域表現
革新的な表現方法: 離散座標(点や境界ボックスの位置)と連続特徴(領域の視覚内容)を組み合わせた表現。
空間感知の視覚サンプラー: 形状や稀薄性に基づいて視覚特徴を抽出、多様な形状の領域を処理。
多様な領域入力
点: 画像中の特定点の識別。
境界ボックス: 画像中の物体や特定領域を識別。
自由形状: 手描きの輪郭や不規則形状など、複雑な自由形状の処理。
論文: Ferretに関する詳細な論文
GRITデータセット
データセットの構成
1.1Mサンプルの包括性: 丰富な層次空間知識を含む、1.1Mのサンプル。
95Kの難易度高いサンプル: モデルの鮮明さと正確性向上のための特別に設計された挑戦的サンプル。
主要なパフォーマンス
Ferret-Bench評価
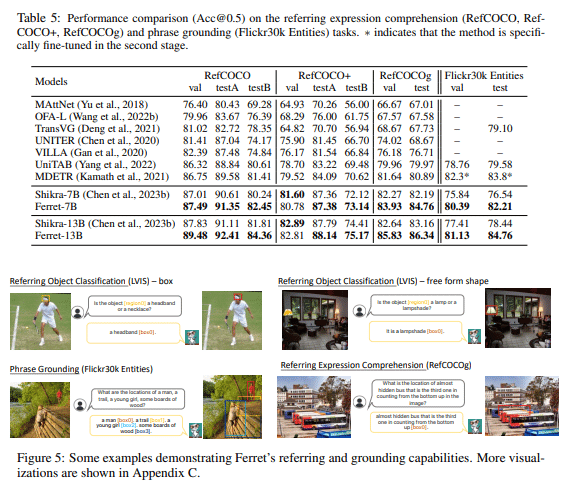
新しいタスクでの評価: 指称記述、指称推論、対話中の定位を含む新しいタスクにおいて、他の多モーダルモデルと比べ平均20.4%の向上。
オブジェクト幻覚の減少: 画像の詳細記述時に誤った内容や架空の内容を減少させる。
高度な空間・意味理解: 空間情報と意味をより正確に処理し、複雑なタスクで高いパフォーマンスを発揮。
結論
AppleのFerretは、画像とテキストの間の複雑な関係を理解し、様々な形状やサイズの要素を識別できる革新的な多モーダルモデルです。その高度な機能と汎用性により、多様な応用分野において新たな可能性を開きます。Ferretは、複雑な画像とテキストのインタラクションを処理する際、新しい水準を提供しています。このモデルは、特に画像検索、自動画像注釈、インタラクティブメディア探索などの分野で顕著な効果を発揮し得ると期待されています。Ferretの進歩は、AIの多モーダル理解能力の境界を押し広げ、新しい応用の道を切り開いています。
AppleによるFerretの開発は、多モーダルAI技術の進展における重要なマイルストーンです。この技術は、様々な業界において、より精度の高い情報解析やユーザー体験の向上に寄与することが期待されます。今後の発展と応用の可能性に注目が集まっています。