
情報の統合から生成まで:RAGによる言語モデルの革新

AI導入と利活用を担当するエンジニアや情報システム部門、ビジネス部門に朗報です。大規模言語モデル(LLMs)の機能を強化し、その精度と関連性を高めるための切り札、「Retrieval-Augmented Generation」(RAG)に関する詳細なサーベイ論文が公開されました。この画期的な技術は、外部情報を組み込むことで、より高度な応答能力を持つAIの実現を目指しています。RAGの設定や活用に関する貴重なヒントとなるこのサーベイは、AI技術の最前線を行く皆さんにとって、必読の内容となるでしょう。
GitHub:
論文:
https://arxiv.org/pdf/2312.10997.pdf
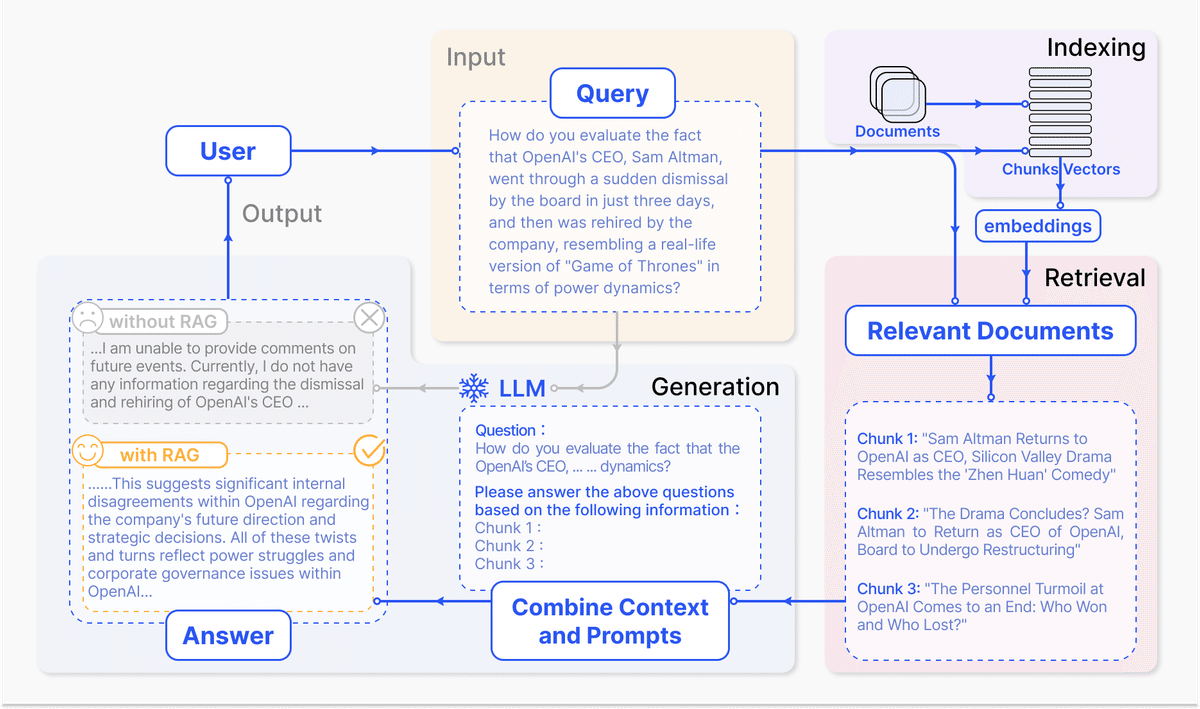
RAG概要
大規模言語モデル(LLMs)は、自然言語処理において顕著な成功を収めているが、ドメイン固有のクエリ処理や最新情報の取り扱いなどには限界がある。
RAG(Retrieval-Augmented Generation)は、外部データベースからの情報取得を組み合わせることで、これらの問題を解決するための有望なアプローチである。RAGの導入により、モデルの応答の正確性と関連性が向上し、継続的な知識更新が可能になる。
RAGの進化
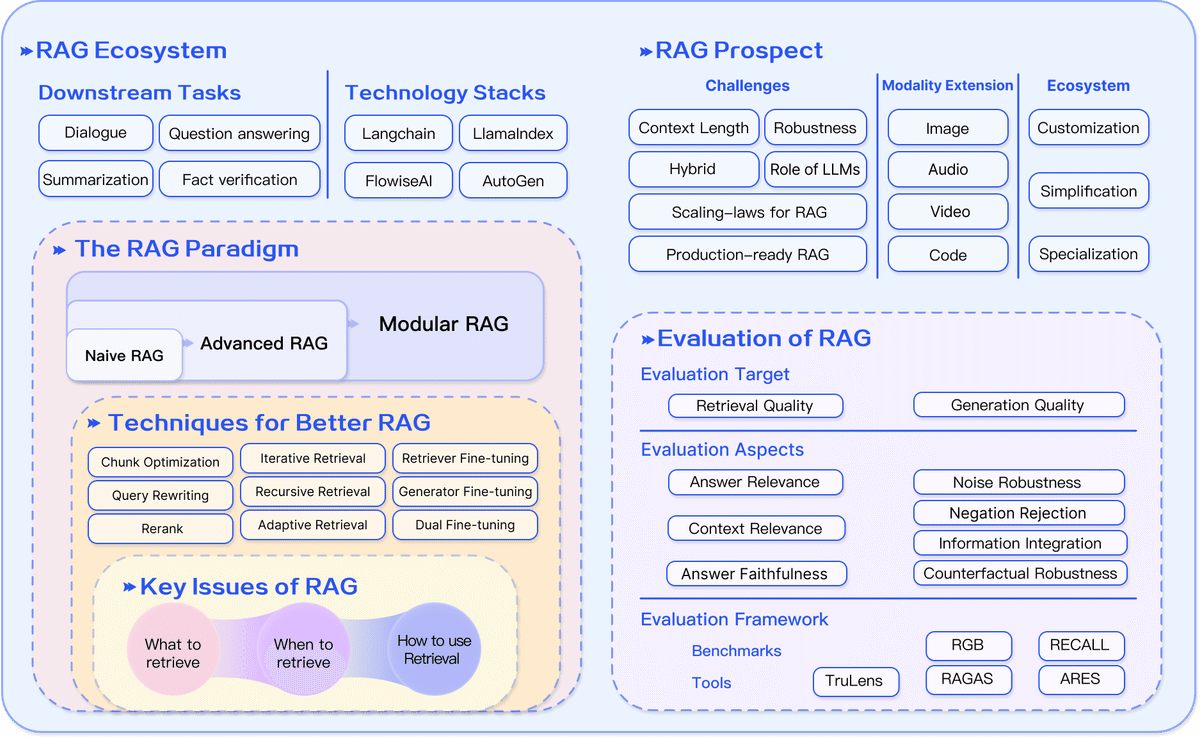
ナイーブRAGは、初期のRAG研究における基本的なフレームワークで、単純な情報取得と生成に焦点を当てていたが、正確性や柔軟性には制限があった。
アドバンスドRAGでは、より洗練された情報取得と文脈の整合性が可能になり、モデルのパフォーマンスが向上した。
モジュラーRAGは、さらなるカスタマイズと拡張性を提供し、特定の用途やドメインに合わせたモデルの調整が可能になった。


RAGのコアコンポーネント
レトリーバルの技術:文書の精度向上
レトリーバル技術は、関連する外部情報を効率的に取得するための手法です。このプロセスは、クエリに対して最も関連性の高い文書やデータを選択し、LLMsに供給することで、生成される応答の質を向上させます。進化するレトリーバル技術には、コンテキストの精度を高めるための様々なアプローチが含まれます。
ジェネレーターの役割:情報の合成と生成
ジェネレーターは、レトリーバルによって得られた情報をもとに、応答を生成するコンポーネントです。このプロセスでは、取得した情報を統合し、質の高い、一貫性のある、情報に基づいた回答を生成します。ジェネレーターの役割は、情報の精度と文脈の関連性を保ちながら、ユーザーのクエリに対して適切な応答を提供することです。
拡張技術:効率的な情報統合
RAGでは、レトリーバルとジェネレーターの間で情報が効率的に統合されることが重要です。この拡張技術は、異なる情報源から得られるデータを組み合わせ、LLMsの内部知識と外部データベースの情報を最大限に活用します。このプロセスにより、モデルはより包括的で正確な情報を提供することができます。
RAGの実装方法のカテゴライズ
何を取得するか
文段落、フレーズ、単語などの非構造化データ。
インデックス付き文書、トリプルデータ、サブグラフなどの構造化データ。
いつ取得するか
プレトレーニング、ファインチューニング、推論の各ステージで実施可能。
取得した内容の利用方法
最初の取得は一度きりだが、反復取得、再帰的取得、適応的取得などが登場。
RAGとファインチューニングの比較
RAGは特定のクエリに対するカスタマイズされた情報取得に適している。
FTは時間をかけて知識を内面化し、特定の構造、スタイル、フォーマットを模倣するのに適している。
FTはモデルのパフォーマンスと効率を向上させるが、新しい知識の統合や新しいケースへの迅速な反復には不向き。
RAGとFTは相互に補完的であり、併用することで最良の結果が得られる場合があります。

RAGの評価と今後の課題
RAGモデルの評価基準
RAGモデルの評価は、その性能を定量的に理解するために重要です。評価基準には、レトリーバルの精度、生成された応答の関連性と正確性、モデルのロバスト性などが含まれます。これらの基準は、モデルがどれだけ効果的に外部情報を取り込み、有用な応答を生成できるかを測定します。
RAGにおける未来の研究方向性
RAGの研究は、モデルの堅牢性、文脈長の取り扱い、拡張性、およびモジュール性の向上など、さまざまな方向性を探求しています。また、RAGをさらに発展させるためには、複数のデータソースやモーダル間の統合、リアルタイムでの知識ベースの更新など、新たな挑戦に取り組む必要があります。
マルチモーダル拡張とエコシステムの成長
RAGの応用範囲をテキストから画像、音声、ビデオなどのマルチモーダルなデータに拡張する研究が進行中です。これにより、RAGはさらに多様な情報源を活用し、異なるタイプのクエリに対応できるようになります。RAGのエコシステムの成長は、新しいアプリケーションやツールの開発を促進し、より幅広い分野での使用を可能にします。
応用範囲の拡大:RAGの応用は、質問応答システムだけに留まらず、推薦システム、情報抽出、レポート生成など、より多様なタスクに利用され始めています。
技術スタックの発展:LangchainやLlamaIndexのような既存ツールに加えて、特定のユースケースやシナリオに特化したRAGツールが市場に登場。使用の容易さを目指したシンプルなツールや、実稼働環境に特化した機能を持つツールなどが開発されています。

最後に
この研究は、LLMsが外部データベースからの情報を取り込むことで、ユーザーのクエリに対してより正確で関連性のある応答を提供できることを示しています。詳細な情報と研究の洞察を得るためには、GitHubリポジトリに直接アクセスすることが推奨されます。