
知識の限界を突破!「RAFT」によるドメイン特化型AIの可能性

バークレー校からの最新の研究発表によると、大規模言語モデル(LLM)の新たなトレーニング手法「RAFT」が、ドメイン特化型の問題解決に革命をもたらす可能性があることが示されました。この技術は、特定の専門知識が必要な分野において、より精密で効率的な応答生成を可能にすることを目的としています。
論文、コード
RAFT's code and demo are open-sourced:
概要
RAFT(Retrieval Augmented Fine Tuning)は、特定のドメインに特化した大規模言語モデル(LLM)の訓練を改善するための新しいアプローチです。この手法は、ドメイン固有の質問応答タスクにおいて、適切な文書を利用して正確な回答を生成するモデルの能力を高めることを目的としています。
特徴とメカニズム
リトリバル拡張生成(RAG): RAFTは、質問に対して関連する文書を抽出し、その情報を基に回答を生成するRAG技術を活用します。特に、RAFTは関連性の低い文書(ディストラクター)を無視し、質問に対する回答生成に必要なドキュメント(オラクルドキュメント)のみを活用するように訓練されます。
ファインチューニングの進化: 伝統的なファインチューニングと比較して、RAFTはモデルが特定のドキュメント集合から情報を抽出する過程を最適化することで、ドメイン固有の文脈においても高いパフォーマンスを発揮します。

実験とデータセット
使用データセット: PubMed、HotpotQA、Gorillaなどのドメイン固有データセットが利用され、これらのデータセットを通じてRAFTの有効性が検証されました。
実験結果: RAFTは従来のファインチューニングやRAGと組み合わせたアプローチに比べて、一貫して高いパフォーマンスを示しています。
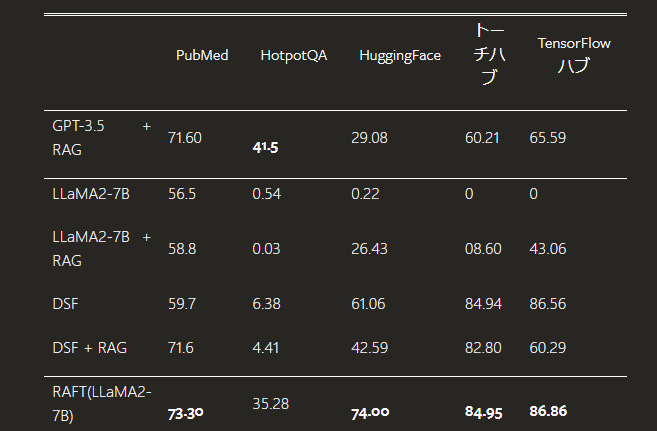
他の手法との比較
ドキュメントの効率的利用: RAFTは質問に最も関連する情報のみを抽出するよう訓練されるため、不要な情報を排除し効率的な回答生成が可能です。
チェーンオブソートの応用: RAFTでは、生成した回答において論理的推理プロセス(チェーンオブソート)を用いることで、より詳細かつ正確な答えを導くことができます。
活用の可能性
専門的質問応答システム: 医療、法律、技術サポートなど、専門知識が求められる分野において、RAFTを利用することで高度な質問応答システムを構築できます。
企業向けソリューション: 企業内の大量の文書データを活用することで、情報抽出や意思決定支援の精度を向上させることが可能です。
適用例とその効果
教育分野の応用: RAFTは学術的な資料や研究論文からの情報抽出にも利用でき、研究者や学生が情報をより効率的に取得する手助けをします。
カスタマーサポートの強化: 顧客からの具体的な質問に対して、関連する製品マニュアルやFAQから正確な情報を提供することで、カスタマーサポートの効率と品質を大幅に向上させることが可能です。
結論
ドメイン特化型の問題解決において、RAFTは単に技術的な革新以上の意味を持ちます。この手法は、ビジネスにおける意思決定支援や戦略的問題解決の効率を大幅に向上させる可能性を秘めています。特に、高度な専門知識を要する産業において、RAFTによる言語モデルの精度と効率の向上は、競争優位性を確立するための鍵となるでしょう。将来的には、この手法が組織の知識基盤を強化し、革新的なソリューションの創出を促進することが期待されます。AIの進化において、RAFTは新たなマイルストーンとなる可能性が高いです。