
言語モデルの性能向上:メタの多トークン予測の利点とは?

メタによる最近の研究「Better & Faster Large Language Models via Multi-token Prediction」では、多トークン予測を用いることで、大規模言語モデルの性能と効率が大幅に向上することが示されました。この技術は、AIの未来において重要な進歩を意味しています。
論文:
多トークン予測の技術的詳細
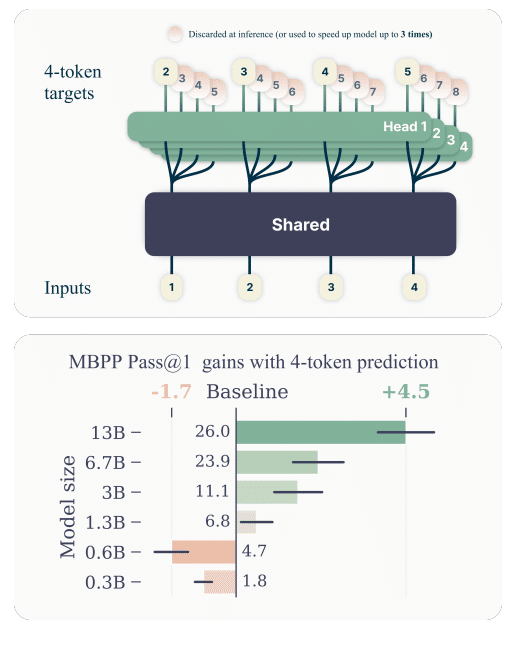
基本構造: 共有トランスフォーマーのトランクから、観察されたコンテキストに基づいて潜在表現が作成されます。この表現はその後、n個の独立した出力ヘッドに供給され、それぞれが次のnトークンを並行して予測します。
損失関数の分解: 提案された多トークン予測では、クロスエントロピー損失を各将来のトークンに対して条件付きで分解し、それぞれのトークン予測が独立して行われるように設計されています。
メモリと推論効率の革新
メモリ使用の最適化: 各出力ヘッドの順伝播と逆伝播が順次計算されることにより、全トークンのロジットと勾配を同時に記憶する必要がなくなり、メモリピーク使用量を大幅に削減します。
推論時の高速化: 追加の出力ヘッドを使用することで、ブロックワイズの並列デコーディングやメデューサのようなツリー注意機構を利用し、バッチ処理が大きい場合でも推論速度を最大3倍に向上させることが可能です。
実験と成果
大規模モデルでの有効性: 多トークン予測は特に大規模なモデルでその効果を発揮し、13BパラメータのモデルがHumanEvalとMBPPのベンチマークで従来のモデルよりも12%と17%多くの問題を解決しています。
ファインチューニングと応用: コードコンテストデータセットにおける多トークン予測モデルのファインチューニングは、従来の次トークンモデルのファインチューニングを上回っています。多トークン事前学習後の次トークンファインチューニングが、学習済み表現のリッチさを最大限活用するための最適な戦略とされています。
結論
メタの多トークン予測の研究は、言語モデルの設計と実装において重要なマイルストーンを表しています。この技術は、モデルのトレーニングと推論の両段階において効率性と効果性を同時に向上させるという、AI研究における長年の課題に対する有望な解決策を提供します。特に、大規模な言語モデルにおける推論速度の向上は、リアルタイムアプリケーションへの応用可能性を大きく広げるものです。さらに、多トークン予測はトレーニング中の教師強制と推論時の自己回帰生成との間の分布の不一致を緩和する可能性があり、これによりより一貫性のあるモデル挙動となる可能性が示唆されています。この技術的進歩は、将来のAIシステム設計のための新たな基盤を築く可能性を持っています。
この記事が気に入ったらサポートをしてみませんか?