
LoRAファインチューニングでLLMの性能が劇的に変わる!その初期化戦略とは?

LLM(大規模言語モデル)のファインチューニングがうまくいかない、または最適なパフォーマンスを引き出せていないと感じたことはありませんか?今、LoRA(Low-Rank Adaptation)を使ったファインチューニングにおいて、初期化方法がカギを握ることが明らかになりました。これを理解すれば、少ないパラメータでより高いパフォーマンスを実現できるかもしれません!
カリフォルニア大学バークレー校の研究チームが行った最新の調査では、LoRAの初期化方法が、学習の効率や最適な学習率に大きな影響を与えることが判明しました。この記事では、ファインチューニングを最大限に活用するためのLoRAの初期化戦略について、徹底的に解説します。これを読めば、あなたも明日からLLMのパフォーマンスを飛躍的に向上させることができるでしょう。
論文:https://arxiv.org/abs/2406.08447
LoRAとは?ファインチューニングの新しいスタンダード
LoRAは、事前学習されたLLMを効率的にファインチューニングするための方法です。従来の方法ではモデル全体を再トレーニングするため、膨大な計算リソースが必要でしたが、LoRAではパラメータの一部だけを微調整することで、より少ないリソースで高い性能を引き出すことが可能です。
具体的には、LoRAは低ランク行列であるAとBという2つの行列をトレーニングします。これにより、LLMの重みを次のように表現します。
[ W' = W_0 + \Delta W = W_0 + BA ]
つまり、もともとの事前学習済みのモデルに対して、新たにトレーニングされた重みが追加されるという仕組みです。
初期化戦略の違いがパフォーマンスに与える影響
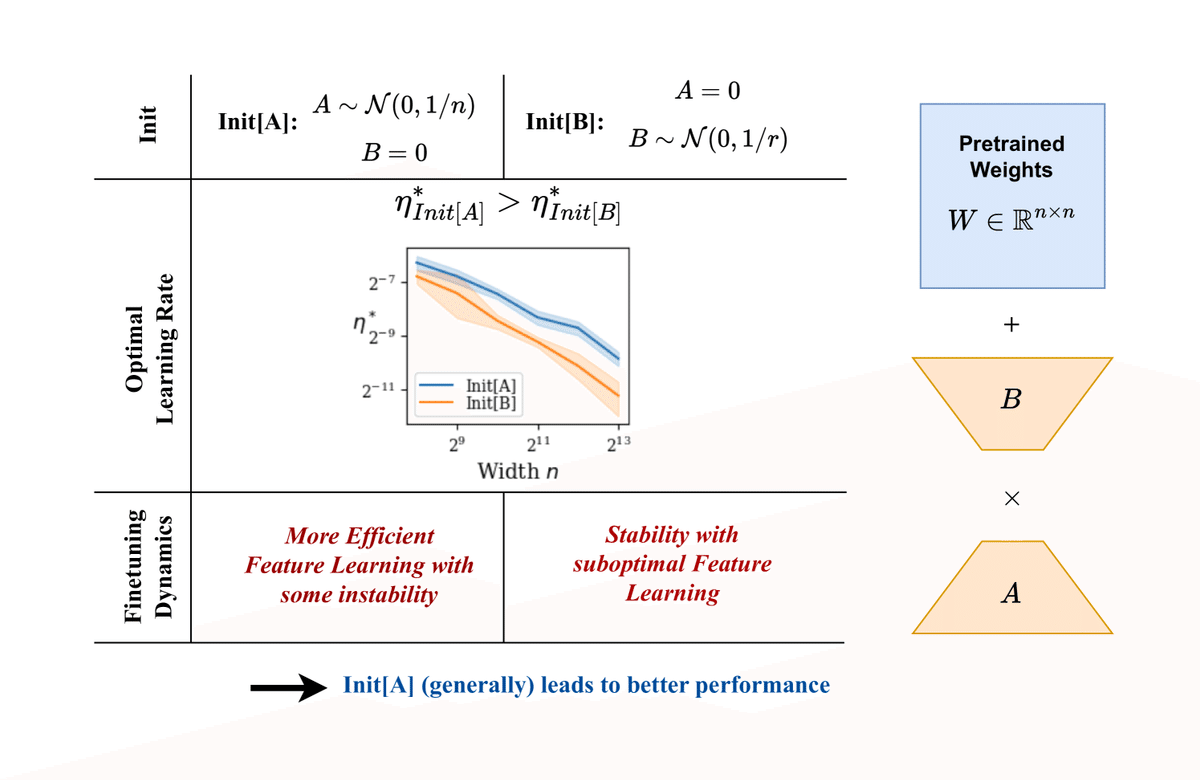
LoRAを使ったファインチューニングにおいて、初期化が非常に重要です。以下の2つの方法が一般的に使用されますが、それぞれが異なる結果をもたらします。
Init[A]: 行列Aをランダムに初期化し、Bをゼロに設定する(標準設定)。
Init[B]: 行列Bをランダムに初期化し、Aをゼロに設定する。
一見すると、どちらも似たような設定に見えますが、実際には学習の進み方や最適な学習率に大きな差が出ることが分かっています。
Init[A]が優位な理由
カリフォルニア大学バークレー校の研究では、行列Aをランダムに、行列Bをゼロに初期化する**Init[A]**が、より高いパフォーマンスを発揮することが証明されました。これには、いくつかの理由があります。
Init[A]は高い学習率が使える:Init[A]の場合、モデルの学習率をより高く設定しても、安定した学習を行うことができます。これにより、モデルがより早く効率的に収束します。
特徴学習の効率が向上する:Init[A]では、一時的に行列Aが大きな値を取る「内部不安定性」が発生しますが、これがむしろモデルに新たなパターンや特徴を効率的に学習させる要因となります。
実験での裏付け:LLMが劇的に改善
実際に行われた実験では、RoBERTaやLlamaといった大規模言語モデル(LLM)を使用して、GLUEやWikiText-2といったタスクでファインチューニングを行いました。その結果、Init[A]が常にInit[B]を上回るパフォーマンスを発揮し、より高い学習率でも安定して学習できることが確認されました。
これにより、LLMのファインチューニングを行う際には、Init[A]を選択することで、より少ない計算リソースで高い成果を得られる可能性が高いことが分かりました。
結論:
LoRAを使ったファインチューニングにおいて、初期化方法はモデルの性能に大きな影響を与える非常に重要な要素です。特に、行列Aをランダムに初期化し、行列Bをゼロに設定する**Init[A]**の方が、より高い学習率を使えるため、効率的な特徴学習が可能になります。
これからLLMを使ったプロジェクトに取り組む際には、ぜひこの初期化戦略を意識してみてください。あなたのモデルのパフォーマンスは大きく向上し、少ないリソースで最大の効果を得られることでしょう。