
混合専門家モデル(MoE):トランスフォーマーの効率とスマートな進化

混合専門家モデル(Mixture-of-Experts、MoE)は、大脳に似たネットワーク、特にトランスフォーマーモデルに最適化された、革新的な神経ネットワーク設計です。MoEは、データが流れる際にそれを動的に処理する多数の「専門家」や小型のスマートモデルを内包しています。この記事では、@sophiamyangのツイートを参考にMoEの仕組み、主要な構成要素、そしてなぜこれがデータ処理において非常に効果的なのかを探ります。
What is Mixture-of-Experts (MoE)?
— Sophia Yang, Ph.D. (@sophiamyang) December 9, 2023
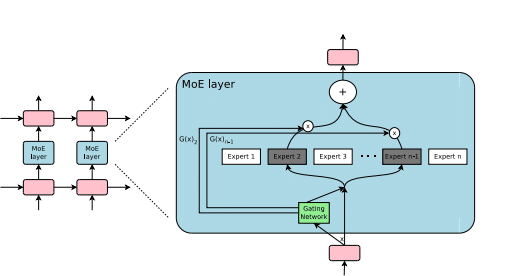
MoE is a neural network architecture design that integrates layers of experts/models within the Transformer block. As data flows through the MoE layers, each input token is dynamically routed to a subset of the experts for computation. This… pic.twitter.com/AnYeITgHVi
MoEの仕組み
専門家ネットワーク:MoEには、特定のタスクに特化した小型のスマートモデルやマルチレイヤーパーセプトロン(MLP)、複雑な大型言語モデル(LLM)など、多数の「専門家」が含まれています。
動的なデータルーティング:データが流れる際には、それぞれのデータトークンが動的に特定の専門家群にルーティングされます。このプロセスは、データの特定の部分やタスクを処理するために専門家を特化させることで、計算効率を高めます。

MoEの主要な構成要素
専門家:MoEレイヤーは、多数の専門家で構成されており、これらは小型のMLPやMistral 7Bのような複雑なLLMであることがあります。
ルーター:どの入力トークンがどの専門家に割り当てられるかを決定するルーターがあります。ルーターは、softmaxゲーティング機能を用いて専門家やトークンをモデル化し、最適な専門家を選択します。

MoEの利点
専門化による効率的なタスク処理:各専門家は異なるタスクやデータの異なる部分を扱うことに特化しています。
推論コストの増加なしに学習可能なパラメータの追加:LLMに追加の学習可能なパラメータを加えることができます。
スパース行列の効率的な計算:MoEは、スパース行列の計算において高い効率を実現します。
GPUの並列処理能力の活用:専門家レイヤーは並列に計算され、GPUの並列処理能力を効果的に活用します。
モデルのスケーラビリティとトレーニング時間の短縮:MoEは、より低い計算コストでモデルを効率的にスケールアップし、トレーニング時間を短縮し、より良い結果をもたらします。
総括
簡単に言うと、MoEは工場の専門家チームのようなものです。各「工員」は特定の作業に非常に長けており、タスクが来ると、その分野の専門家に直接渡されます。これにより、工場(または神経ネットワーク)全体がより良く、速く、賢く動作し、さらなるスペースやエネルギーを必要とせずに効率化を実現します。MoEは、データ処理と神経ネットワーク設計の未来において重要な役割を果たす革新的なアプローチであり、その効果は計り知れないものです。
参考:
『Sparsely-Gated Mixture-of-Experts Layer』(2017) https://t.co/laOv9xoLvJ
『GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding』(2020) https://t.co/fUhqA8CVIH
『MegaBlocks: Efficient Sparse Training with Mixture-of-Experts』(2022) https://t.co/POrZJW9BtO
『Mixture-of-Experts Meets Instruction Tuning』(2023) https://t.co/fcnbNSO0HV