
#消費者物価指数 #e-Stat #R #GoogleColab #ChatGPT

Rに書き換え
消費者物価指数を品目ごとに調べたい。
ChatGPTに聞きながら作成したPythonのコードを、ChatGPTにRのコードに書き換えてもらいました。
Macで発生する文字化け対応など一部修正しましたが、ほとんどChatGPTに教えてもらったコードを使っています。
基準品目の番号をカンマで区切って選択してください: 57,58,59,60,61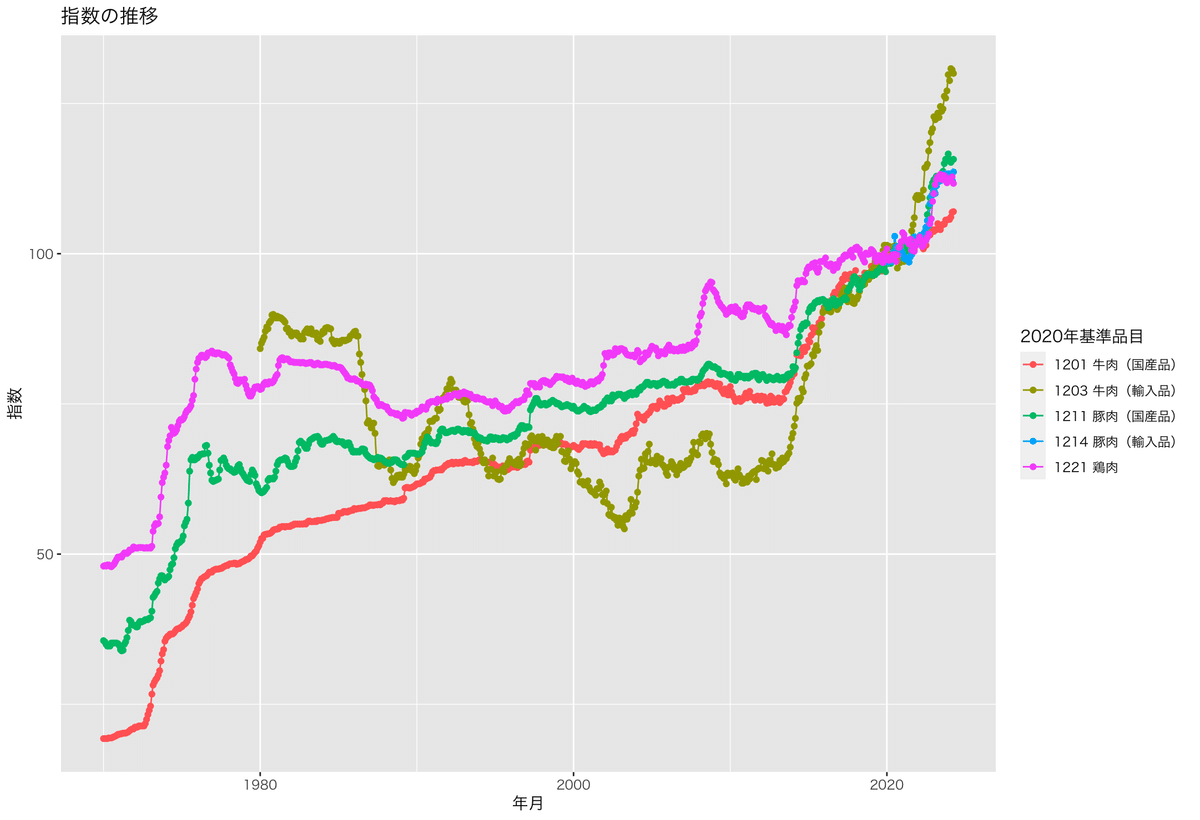
そのRコード
# 必要なパッケージをインストールして読み込む
install.packages("tidyverse")
library(tidyverse)
# CSVデータのURL
csv_url <- 'http://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData?cdTab=1&cdArea=00000&cdTimeFrom=1970000101&appId=f53ecf607bd3688c8d146c2a7ca894fe78cc7aa1&lang=J&statsDataId=0003427113§ionHeaderFlg=2&replaceSpChars=0'
# CSVデータを読み込む
data <- read_csv(csv_url)
# データの前処理
data2 <- data %>%
mutate(value = as.numeric(value), # 'value' 列を数値に変換
`時間軸(年・月)` = as.Date(paste0(`時間軸(年・月)`, "01日"), format = "%Y年%m月%d")) %>% # '時間軸(年・月)' 列を日付型に変換
drop_na(value, `時間軸(年・月)`) # 欠損値を含む行を削除
# ユーザーに選択肢を提示
# unique_items[i] はベクトルのi番目
unique_items <- unique(data$`2020年基準品目`)
cat("選択可能な基準品目:\n")
for (i in seq_along(unique_items)) {
cat(i, ": ", unique_items[i], "\n")
}
# 選択された基準品目に基づいてデータをフィルタリング
# readline 関数を使用して、ユーザーからの入力を取得
selected_indices<- readline(prompt = "基準品目の番号をカンマで区切って選択してください: ")
#"142,143,145"
selected_indices <- strsplit(selected_indices, ",")[[1]]
#[1] "142" "143" "145"
selected_indices <- as.integer(selected_indices) # 文字列から整数に変換
#142 143 145
selected_items <- unique_items[selected_indices]
#[1] "1571 いちご" "1581 バナナ" "1572 さくらんぼ"
# グラフを描画
library(ggplot2)
# 選択された基準品目に基づいてデータをフィルタリング
filtered_data <- data2 %>% filter(`2020年基準品目` %in% selected_items)
# グラフを描画
ggplot(data = filtered_data, aes(x = `時間軸(年・月)`, y = value, color = `2020年基準品目`)) +
geom_line() +
geom_point() +
labs(title = "指数の推移", x = "年月", y = "指数") +
theme_minimal() +
theme_gray (base_family = "HiraKakuPro-W3") # 文字化け対策