
SDXL系の画像生成プロンプトについて

みなさん、こんにちは。SDXL系のモデルも沢山出そろってきましたが、私が使っているSDXL生成テクニック(自論)についてご紹介します。
え? 全部読むのめんどくさいって? なら忙しい人の為に要点だけ。
1 生成サイズは短辺を1024とする。 例(1024:1536)
2 Hires.fix・Refinerは使わない。
3 試しにネガティブプロンプトのクオリティを空にしてみて
4 2つ目のテキストエンコーダー自然言語で情景描写。
生成サイズについて
SDXL_baseは1024×1024で学習されており、それを最小のサイズとして生成することをお勧めします。
しかし、学習効率の観点から768×768で学習されてるモデルもあるため、768×1024のサイズ等で生成しても一定のクオリティで出力することができます。
しかし、SDXL_baseが内包する実力を発揮させるのであれば、1024×1536などで生成することをオススメします。
また、短辺が1024であるためそれだけで高いクオリティの画像が出力されます。闇雲にHires.fix・Refinerを使うのはやめましょう。
ネガティブブロントについて
最近でこそ、SDXLにもしっかりと学習が進んだモデルがあり、下図のようにネガティブプロンプトを空にしても一定のクオリティで出力されるモデルも多数存在します。
その為、ネガティブに側にネガティブクオリティを入れる必要があるのかどうかは、自分が使おうとしているモデルがネガティブプロンプトが必要かどうか一度試してください。
必要もないのにネガティブプロンプトにクオリティタグを入れると要素が重複して過学習のような画像が出力されてしまいます。


【(worst quality, low quality:1.1) unaestheticXLv31,large breasts,】
2つのテキストエンコーダーについて
SDXLには、2つのテキストエンコーダーが存在します。
OpenCLIP-ViT/GとCLIP-ViT/Lです。
Gが自然言語特化モデルで Lが1.5時代の単語特化モデルとなっています。
ComfyUIなどを用いればそれぞれのテキストエンコーダーにプロンプトを引き渡せますが、そこまでする必要はありません。
WebUI1111を用いる際に注意するのは、通常のカンマ区切りのプロンプトを用いてクオリティタブやキャラクター情報を書き込んで、光や背景などの情景を自然言語でシッカリと書きこんでやることです。
(重要なポイント 自然言語の部分にも女性が立っているや座っているなど人物情報を含まないと背景画像だけになる場合があります)
しかし、日本人の我々がいきなり、英語の自然言語でシッカリ書けといわれても困りますね。
そこで、ChatGPT等といったサービスをうまく活用しましょう。

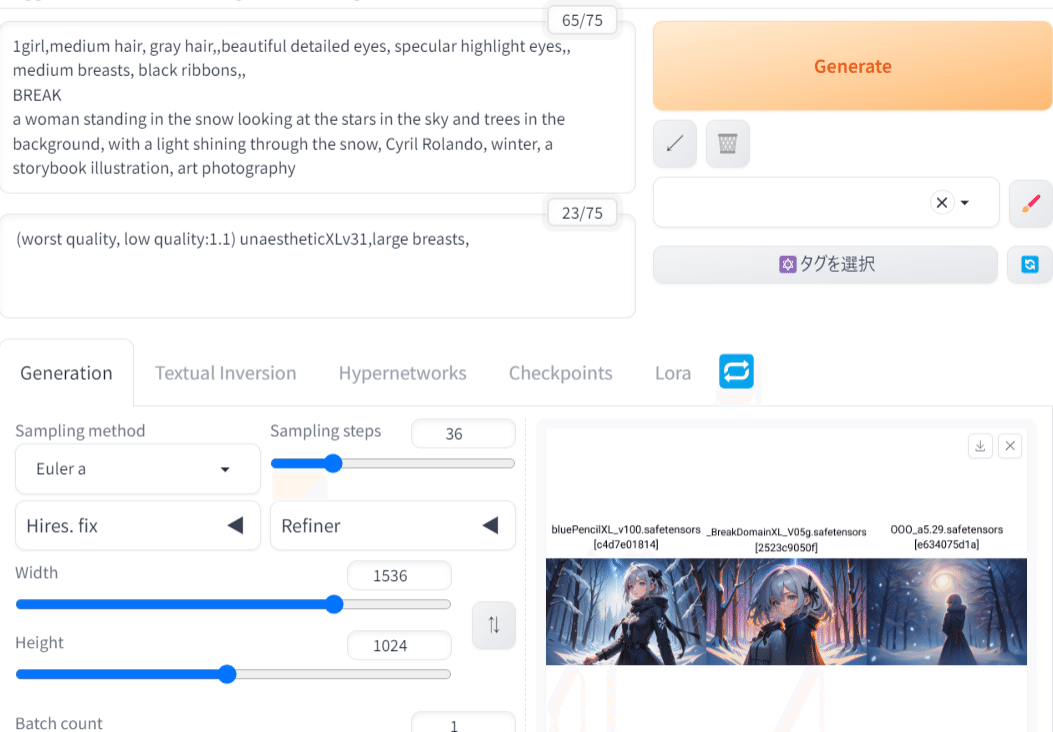
こちらの画像は以下のプロンプトで生成しています。後段の自然言語の部分については、ChatGPTを用いて生成したものです。


ChatGPTは有料のサービスですので、使えないという人もいることでしょう。その場合はBing Image CreatorとInterrogate CLIPを活用しましょう。

こちらの画像の生成手順は、次のとおりです。


最後に
SDXLでは表現できないものも沢山ありますが、SDXLでしか表現できないものもあります。気が向いたら、たまにはSDXLを触ってみるのもいかがでしょうか?