
この世に存在しない交響曲の楽曲解説をつくろう(形態素解析とマルコフ連鎖で)

はじめに
執筆者:あおじい
クラシックの演奏会で、必ずと言っていいほど配られるパンフレット。
その中で、楽団紹介や演者の経歴といった情報に混じって、演奏する楽曲を解説しているページがあるのを、皆さんも一度は見たことがあるのではないでしょうか。

あれって作る側になると分かるんですが……楽曲解説を書くのは超〜〜〜〜〜〜めんどくさいんです。
主題がどの楽器で回されているだとか、このフレーズは何をモチーフに作られているかだとか……とにかく緻密にスコアを読み解くところからスタートしなくてはいけません。作曲者を取り巻く状況や時代背景を紐付けないと、説明できない箇所もあるでしょう。
加えて、情報の裏取りや自己の解釈を交えた考察、日本語の校正まで必要です。全体の作業量は、膨れ上がってしまいます。
伝統を重んじるクラシック界隈とはいえ、これではIoTの手も借りたい気分です。
せめて、この世にはびこる楽曲解説によく出てくるワードをかき集めてくれて、ボキャブラリーの助けになるツールがあればな〜〜!!
てかいっそのこと、いい感じのことばを適当に組み合わせて、楽曲解説っぽい文章がいつの間にか勝手に出来上がってくれればいいのにな〜〜〜〜〜!!!!!!!!!!!!!

やること
Wikipediaの楽曲解説を解析しよう
単語のランキングを生成しよう
架空の楽曲解説を生成しよう
1. Wikipediaの楽曲解説を解析しよう
まずは、世界最大のインターネット情報リソースであるWikipediaから、いろんな交響曲の楽曲情報を取得しましょう。
例として、「交響曲第10番 (ショスタコーヴィチ)」のWikipediaページを開いてみます。すると、記事全体が次のようなセクション群で構成されていることが分かります。
概要
作曲の経緯
作品の解釈
初演
曲の構成
楽器編成
順番など細かい差異はあれど、他の交響曲のページも大体こんな感じです。楽曲解説に盛り込みたいセクションは、この中でも「曲の概要」とか「作曲の経緯」とか「楽章構成」とか、あたりではないでしょうか。

今回は、「曲の構成」のセクションからテキストを抽出することにします。調性とか形式とか主題とかを解説しているアレですね。
どこから記事を取る?
とはいえ、1記事だけを解析しても、情報がぜんぜん足りません。
Wikipediaという超ビッグな情報源を最大限に活かし、解析の対象を広げたいですね。
そこで、「交響曲の一覧」というWikipediaページの出番です。ここから内部リンクを辿れば、たいていは交響曲に関する個別記事に飛ぶことが出来るでしょう。
遷移先の中には、楽曲構成のセクションが設けられていないものや、ページそのものが作られていないもの(いわゆる赤リンク)なども含まれています。が、得られるデータの膨大さと比べれば些細な問題です。

そんなこんなで、交響曲505曲分の楽曲構成を抽出しました。
素のテキストなのに、1MBに近いサイズがあります。初代ゲームボーイのソフト容量くらいです。大変ワクワクしますね。
2. 単語のランキングを生成しよう
楽曲解説を書くときに、「おんなじ単語ばっかり使ってしまいがち」という悩みは、たびたび発生するものです。
例として、ショスタコーヴィチ「祝典序曲」を題材に、簡単な楽曲解説の冒頭を作ってみました。
初めにトランペットが明るくファンファーレを奏する。続いて、クラリネットが明るい第1主題を奏し、続いて弦楽器も明るく奏する。トランペットとスネアによる明るいリズムが奏され、全体が明るくなったとき、突然ホルンとチェロによる明るい第2主題が奏される。弦楽器により奏されるピチカートは明るい。……
最悪ですね!ゲシュタルト崩壊待ったなしです。
もちろん、この楽曲解説が全くの嘘というわけでもありません。
ただ、楽曲解説を作るからには、そこそこ面白い読み物として提供されたいものです。似たことばを別の言い回しにしたり、よりクリティカルな表現に変換するために、相応のボキャブラリーを求められることになります。
読書嫌いには辛い展開です。
「こんなときに、楽曲解説によく出てくるワードをかき集めてくれて、ボキャブラリーの助けになるツールがあればな〜〜!!」
そんなこんなで、分析しましたよ。
楽曲解説(505曲分)における頻出単語ランキング、品詞別TOP100を。

🏅【動詞】頻出単語ランキング🏅
🥇 第1位 🎉 現れる 🎉(411回)
🥈 第2位 🎉 始まる 🎉(298回)
🥉 第3位 🎉 続く 🎉(246回)
🏅 第4位 奏す(234回)
🏅 第5位 入る(220回)
[('現れる', 411), ('始まる', 298), ('続く', 246), ('奏す', 234), ('入る', 220), ('終わる', 217), ('繰り返す', 194), ('いく', 177), ('おる', 169), ('せる', 168), ('歌う', 166), ('くださる', 165), ('持つ', 145), ('奏でる', 140), ('用いる', 134), ('くる', 124), ('書く', 121), ('示す', 121), ('基づく', 117), ('戻る', 117), ('見る', 111), ('よる', 111), ('経る', 96), ('加わる', 90), ('出す', 88), ('使う', 87), ('扱う', 87), ('伴う', 84), ('閉じる', 82), ('奏する', 78), ('出る', 73), ('締めくくる', 69), ('乗る', 68), ('盛り上がる', 66), ('築く', 65), ('導く', 64), ('いう', 62), ('思う', 62), ('含む', 62), ('異なる', 61), ('進む', 60), ('静まる', 60), ('できる', 59), ('転じる', 58), ('ゆく', 55), ('つける', 53), ('とる', 52), ('見せる', 47), ('似る', 46), ('行う', 45), ('もつ', 44), ('変わる', 43), ('落ち着く', 41), ('受ける', 41), ('吹く', 40), ('はじまる', 40), ('変える', 38), ('結ぶ', 38), ('描く', 37), ('始める', 37), ('置く', 36), ('増す', 36), ('言う', 36), ('刻む', 35), ('つづく', 35), ('加える', 35), ('表す', 34), ('至る', 34), ('重ねる', 33), ('落とす', 33), ('挟む', 32), ('記す', 32), ('成る', 31), ('迎える', 31), ('受け継ぐ', 30), ('移る', 30), ('呼ぶ', 30), ('終える', 30), ('続ける', 30), ('採る', 29), ('引き継ぐ', 29), ('聞こえる', 28), ('述べる', 28), ('考える', 28), ('満ちる', 28), ('達する', 26), ('欠く', 26), ('消える', 26), ('聴く', 25), ('付ける', 25), ('帯びる', 25), ('与える', 24), ('響く', 24), ('上げる', 24), ('速める', 23), ('流れる', 23), ('絡む', 23), ('あり', 23), ('しまう', 22), ('果たす', 21)]
🏅【名詞】頻出単語ランキング🏅
🥇 第1位 🎉 主題 🎉(2,883回)
🥈 第2位 🎉 部 🎉(1,828回)
🥉 第3位 🎉 拍子 🎉(1,440回)
🏅 第4位 長調(1,217回)
🏅 第5位 形式(1,168回)
[('主題', 2883), ('部', 1828), ('拍子', 1440), ('長調', 1217), ('形式', 1168), ('分の', 1010), ('的', 982), ('曲', 789), ('ソナタ', 721), ('短調', 675), ('演奏', 661), ('再現', 619), ('旋律', 575), ('展開', 555), ('分', 539), ('動機', 527), ('提示', 525), ('よう', 496), ('ヴァイオリン', 493), ('音', 492), ('後', 443), ('変', 441), ('序奏', 424), ('Allegro', 418), ('交響', 411), ('譜', 407), ('例', 385), ('ホルン', 375), ('番', 371), ('コーダ', 362), ('時間', 348), ('弦楽器', 336), ('A', 336), ('風', 335), ('mw', 332), ('部分', 330), ('8', 327), ('弦', 327), ('音声', 322), ('トリオ', 321), ('ホ', 319), ('parser', 315), ('output', 315), ('ハ', 311), ('スケルツォ', 306), ('木管', 304), ('小節', 301), ('ニ', 297), ('音楽', 281), ('もの', 279), ('冒頭', 275), ('変奏', 265), ('主部', 264), ('5', 256), ('リズム', 253), ('6', 252), ('こと', 250), ('ロ', 249), ('メヌエット', 249), ('構成', 230), ('これ', 227), ('B', 218), ('アレグロ', 212), ('最後', 211), ('オーボエ', 210), ('楽器', 208), ('和音', 202), ('listen', 196), ('調', 191), ('クラリネット', 188), ('フルート', 184), ('チェロ', 181), ('中間', 177), ('フィナーレ', 175), ('ト長調', 171), ('静か', 166), ('イ長調', 162), ('使い', 162), ('再生', 162), ('ブラウザー', 161), ('サポート', 161), ('ファイル', 161), ('ダウンロード', 161), ('試し', 161), ('トランペット', 157), ('px', 156), ('アダージョ', 155), ('中', 154), ('独奏', 154), ('上', 154), ('Andante', 153), ('型', 149), ('登場', 147), ('ファゴット', 146), ('主要', 145), ('年', 145), ('ロンド', 144), ('ため', 144), ('作曲', 144), ('度', 144)]
(多少、Wikipedia特有の謎の語句が混ざっているのはご容赦を🤫)
🏅【形容詞】頻出単語ランキング🏅
🥇 第1位 🎉 短い 🎉(165回)
🥈 第2位 🎉 ない 🎉(149回)
🥉 第3位 🎉 長い 🎉(102回)
🏅 第4位 力強い(94回)
🏅 第5位 明るい(78回)
[('短い', 165), ('ない', 149), ('長い', 102), ('力強い', 94), ('明るい', 78), ('強い', 72), ('激しい', 70), ('速い', 57), ('美しい', 56), ('多い', 54), ('大きい', 53), ('新しい', 49), ('暗い', 41), ('高い', 33), ('珍しい', 29), ('輝かしい', 28), ('遅い', 24), ('重々しい', 23), ('緩い', 22), ('荒々しい', 22), ('近い', 18), ('優しい', 17), ('悲しい', 16), ('楽しい', 15), ('低い', 13), ('深い', 12), ('細かい', 12), ('めまぐるしい', 11), ('柔らかい', 11), ('無い', 10), ('華々しい', 10), ('重い', 10), ('忙しい', 10), ('弱い', 10), ('広い', 9), ('よい', 9), ('やすい', 8), ('小さい', 7), ('古い', 7), ('重苦しい', 7), ('薄い', 7), ('愛らしい', 7), ('少ない', 7), ('早い', 7), ('若い', 6), ('濃い', 6), ('弱々しい', 5), ('幅広い', 5), ('甘い', 5), ('鋭い', 4), ('慌ただしい', 4), ('騒々しい', 4), ('忙しない', 4), ('興味深い', 4), ('厚い', 4), ('恐ろしい', 4), ('難しい', 4), ('儚い', 3), ('軽い', 3), ('やさしい', 3), ('目まぐるしい', 3), ('せわしない', 3), ('悪い', 3), ('物憂い', 3), ('赤い', 3), ('厳しい', 3), ('刺々しい', 3), ('っぽい', 3), ('規則正しい', 3), ('著しい', 3), ('もの悲しい', 3), ('良い', 3), ('喜ばしい', 3), ('ほの暗い', 3), ('寂しい', 3), ('騒がしい', 2), ('勇ましい', 2), ('正しい', 2), ('いとしい', 2), ('素早い', 2), ('気高い', 2), ('狭い', 2), ('面白い', 2), ('ふさわしい', 2), ('遠い', 2), ('にくい', 2), ('しつこい', 2), ('瑞々しい', 2), ('荒っぽい', 2), ('凄まじい', 2), ('色濃い', 2), ('詳しい', 2), ('心地よい', 2), ('程よい', 2), ('甲高い', 2), ('淋しい', 2), ('温かい', 2), ('冷たい', 2), ('狂おしい', 2), ('相応しい', 1)]
🏅【副詞】頻出単語ランキング🏅
🥇 第1位 🎉 再び 🎉(146回)
🥈 第2位 🎉 やがて 🎉(118回)
🥉 第3位 🎉 次第に 🎉(79回)
🏅 第4位 そのまま(77回)
🏅 第5位 すぐ(74回)
[('再び', 146), ('やがて', 118), ('次第に', 79), ('そのまま', 77), ('すぐ', 74), ('さらに', 62), ('突然', 41), ('ほぼ', 41), ('まず', 39), ('やや', 36), ('最も', 35), ('よく', 35), ('パッ', 35), ('やはり', 34), ('かなり', 32), ('ゆっくり', 31), ('徐々に', 30), ('同じく', 29), ('きわめて', 28), ('しばしば', 27), ('ほとんど', 27), ('実際', 25), ('同時に', 25), ('ゆったり', 23), ('特に', 23), ('初めて', 23), ('より', 23), ('はっきり', 21), ('しばらく', 21), ('一旦', 20), ('堂々', 20), ('少し', 20), ('次々', 20), ('比較的', 19), ('次に', 17), ('突如', 17), ('生き生き', 16), ('いったん', 16), ('終始', 14), ('ごく', 14), ('もう一度', 14), ('あまり', 13), ('もう', 13), ('順次', 13), ('極めて', 12), ('全く', 12), ('更に', 11), ('また', 10), ('わずか', 10), ('一気に', 9), ('すでに', 9), ('だんだん', 9), ('ようやく', 8), ('もっとも', 8), ('直ちに', 7), ('ついに', 7), ('かつて', 7), ('共に', 7), ('幾分', 7), ('ふたたび', 7), ('まもなく', 7), ('まるで', 7), ('いきなり', 7), ('間もなく', 6), ('既に', 6), ('再度', 6), ('度々', 6), ('いかにも', 6), ('おそらく', 6), ('主として', 6), ('まだ', 6), ('常に', 5), ('とりわけ', 5), ('はじめて', 5), ('ひとしきり', 5), ('いくらか', 5), ('順に', 5), ('もはや', 4), ('むしろ', 4), ('とても', 4), ('勢い', 4), ('そっくり', 4), ('ところどころ', 4), ('もっと', 4), ('古く', 3), ('多少', 3), ('ときどき', 3), ('時に', 3), ('たびたび', 3), ('延々と', 3), ('バーン', 3), ('おおむね', 3), ('ひっそり', 3), ('きびきび', 3), ('なかなか', 3), ('互いに', 3), ('いわば', 3), ('絶えず', 3), ('一層', 3), ('もともと', 3)]
使用例
特に動詞・形容詞・副詞に関しては、上記はかなり有益なデータなのではないでしょうか?
例えば、「『演奏する』という動詞を、文章の中に使いすぎちゃったな〜…」なんてときは、ランキングの出番です。
ニュアンスの似ている単語をピックアップして、差し替えちゃいましょう。
現れる
奏す、奏する、奏でる
歌う、刻む、描く
築く
これらは割と、「演奏する」と気軽に置き換えることができそうです。
前後のフレーズとの関係性や、曲調などにフォーカスした具体性を持つ単語であれば、さらに
続く、転じる
入る、加わる、伴う
盛り上がる
なども、視野に入ると思います。
改めて、最初に作った楽曲解説を見てみます。重複して使用されている語彙を、ランキングに掲載されている言葉に置き換えると、どうなるでしょう?
初めにトランペットが明るくファンファーレを奏する。続いて、クラリネットが明るい第1主題を奏し、続いて弦楽器も明るく奏する。トランペットとスネアによる明るいリズムが奏され、全体が明るくなったとき、突然ホルンとチェロによる明るい第2主題が奏される。弦楽器により奏されるピチカートは明るい。……
↓
初めにトランペットが華々しくファンファーレを奏でる。続いて、クラリネットによる輝かしい第1主題が現れ、続いて弦楽器も活き活きと受け継ぐ。トランペットとスネアによるせわしないリズムに乗せ、全体が徐々に盛り上がりを見せ始めたとき、突然ホルンとチェロによる穏やかな第2主題に転じる。弦楽器のピチカートは軽さを帯びている。……
比べ物にならないほど、立派な曲紹介になりましたね!
コスパ最強。

3. 架空の楽曲解説を生成しよう
語彙は補完できるようになったものの、言葉を入れ替える前の解説文そのものは、やはり自分で用意しなくてはなりません。
とはいえ、Wikipediaや知らない人のブログから解説を丸パクリ…というのも、もしバレてしまったときに世間の目が怖いです。
筆者は怠けの権化ですので、更に楽をしたいと思ってしまいました。
よくある言葉をいい感じに組み合わせて、楽曲解説っぽい文章がいつの間にか勝手に出来上がってくれればいいのにな〜〜〜〜〜!!!!!!!!!!!!!
マルコフ連鎖とは
確率論・統計学の用語ですが、今回は自然言語処理の分野での用いられ方に限定します。
突然ですが、クイズです。
Q. 「今日 / の / 天気 / は / 」に続くことばとして、適切なものはどれ?
1. 晴れ
2. トルネード
3. ハンバーグ
当たり前ですが、「1」を選ぶ人が多いと思います。
次点で可能性があるなら「2」でしょうが、「3」はよっぽどのことが無い限りあり得ないでしょう。
でも、「なぜ?」と訊かれると案外不思議なものです。
どれを選んでも、日本語の文法としては破綻していません。意味の上でも、(「3」はともかく)「1」も「2」も天候を表す名詞ですから、入らない理屈はないはずです。

また、もし仮に問題文の1単語のみが置き換わって、「今日 / の / 災害 / は / 」「今日 / の / 夕食 / は / 」になった途端、答えは大きく変わってくると思います。
なぜ、このように答えを判断できるのでしょうか?
それは、学習を通して次の単語を予測することができるからです。皆さんが「お天気ニュース」や「普段の日常生活」といった文章の学習源を元に、「この言葉の次はこれが来やすいんじゃね?」という遷移確率を推測していることに他なりません。
これこそが、マルコフ連鎖を用いた文章生成の基本です。学習元の文章において、特定の単語(群)の次に現れやすい言葉の確率を計算し、その予測パターンをモデル化します。
楽曲解説においても、同様のことが言えます。
「第1」と言われれば、「番」「楽章」や「主題」などが来そうです。
「セルゲイ」と言われれば、「・プロコフィエフ」か「・ラフマニノフ」でしょう。
もし曲紹介の文頭で、「第2楽章」とだけ書かれていれば、「Allegro 変ロ長調 2/4拍子」みたく、楽章の情報が続きそうな気がしますよね。
マルコフ連鎖は文脈を考慮せず、あくまで直前の単語のみに依存した文の生成を行います。そのため、深層学習モデルを使用した高度なAIのモデリングより、文の品質が劣る側面も見られます。
ですが、単純な文法ルールの再現で事足りるのであれば、少ない計算リソースでモデルを作ることができるマルコフ連鎖は最適です。
できたもの
そんなこんなで、作りましたよ。
楽曲解説(505曲分)における日本語の形態素解析データと、マルコフ連鎖による自然言語文章生成学習モデルを。
百聞は一見に如かず、まずはモデルから自動で出力された短文をば。
この曲はドイツ流の4楽章制である。第2主題は再現部冒頭だけでなく、第1楽章第1主題ではじまる。第2楽章Adagio maestosoヘ長調4/4拍子。ソナタ風の自由な形式。 第1楽章アレグロ・アッサイト短調、4分の2拍子。葬送行進曲。A-B-A')。
第1、第2、第3、第1楽章が引用されるが、短縮、変形がなされている。 憂鬱な短調の主題ではじまり、すぐに短調に変わる。 第1楽章「陰の章」と第2楽章の副主題そのものである。 循環形式による交響曲であり、主要主題が全合奏で輝かしく奏される。最後は第1楽章冒頭の逆行である。 声楽が入るのは第2主題のみが再現する。コーダではフガートが用いられる。
なんか、「っぽさ」ありません?
楽曲解説「っぽさ」。
厳密に読み解くと、日本語としては何も成り立っていないです。が、パンフレットの片隅で流して読んでしまう(※)と、「ふーん」と納得できそうな謎のオーラはあります。
(※良くないですよ!皆さんホントに頑張って書いてるので、実際の演奏会ではちゃんと読んであげてくださいね。)
あとはこのモデルを用いて、第{n}楽章 (ただしnは任意の3とか4とか5くらいまでの自然数)から始まる短文を用意すれば、存在しない楽曲解説の完成です!!
第1楽章開始の鈴の音によってもたらされる。譜例9)は変ニ長調から変ホ短調の第1主題の動機が現れ、イ長調の新たな旋律は現れず、音楽は激しくなり情熱的に奏でて終わる。(略)
第2楽章Andantino in modo di canzona-Piùmosso(Andante)ニ短調。管弦楽による序奏(16小節まで)吹き通すようにしてフルート独奏が聞かれる。再利用されたとき、チェロ独奏と受け継がれてゆく。(略)
第3楽章Strettoト短調3/4拍子ヘ長調金管楽器がファンファーレを奏する序奏で開始され、速度を引き締めてニ長調のパートに転じている折、もっと明るい作品はできないのか?)の動機、弦楽器によるエスプレッシーヴォの主題などが加わって第2の部分も変形された原稿の形から改変し、(略)
第4楽章サルタレッロ:プレストイ短調、4分の4拍子-4分の6拍子、三部形式で、管弦楽とピアノによる強烈な和音の連打で繰り返される。譜例13)で始まる。激しい経過部を形作っていく中でヘ長調に戻る。この旋律は、実際の演奏ではトレモロ奏法されている。(略)

おもしろ楽曲解説たち
期せず誕生してしまった、楽曲解説っぽい何かをいくつかご紹介します。
どの楽章をどう演奏するのが特徴的である。
何も伝わってこない
全4楽章、演奏時間は約11分。
楽章1つでカップ麺1個しか作れない
20世紀終盤からは、ティンパニの弱いトリル保持の上に第1主題が回帰し
数十年単位で続くトリル
この交響曲で唯一呈示部を繰り返し、次第におもちゃが増えていき
トイザらスで演奏してる?
《神はわがやぐら」と冒頭で記されている。
無礼千万
ほか、
・第3楽章だった。
・コーダでは冒頭からホルンが活躍しているのではない。
・ブルックナーさんの持っているトロンボーンだけが残る。
・お使いのブラウザーでは、トゥッティがfffで確保される。
といった怪文たちが生まれました。
こういった偶然の産物も、長い文脈を一切無視して文章を生成する、マルコフ連鎖ならではの面白さと言えますね。
おわりに
Wikipediaに収録されている交響曲のページから、楽曲解説のデータを抽出した結果、品詞別の頻出単語ランキングとマルコフ連鎖の文章生成モデルをつくることができました。
ここまで作っておいてなんですが、文章モデルはぶっちゃけ実用に値しないです。流し読みされる前提の低クオリティで、楽曲解説を書く意味も分かりませんからね。
でも、単語と単語のつなぎ方を学んだり、文章構成の大枠を引くくらいであれば、参考にはなるかも分かりません。
個人的にはむしろ、よく用いられる単語を一覧化できたことのほうが収穫でした。
単に「この言葉を言い換えたい!」なんてときの材料としても重宝できそうです。ただそれよりも、音楽の調子や流れを表すボキャブラリーの繊細さ、豊富さに圧倒されたのが本音です。
音楽は、聴いたときの受け取り方も、その表し方も千差万別です。ご自身の言葉ではどうしても紡ぎきれない、鮮やかな感動を味わうこともあるかもしれません。
そんな情景を言語化したいとき、本記事が助けになれば幸いです。
………。

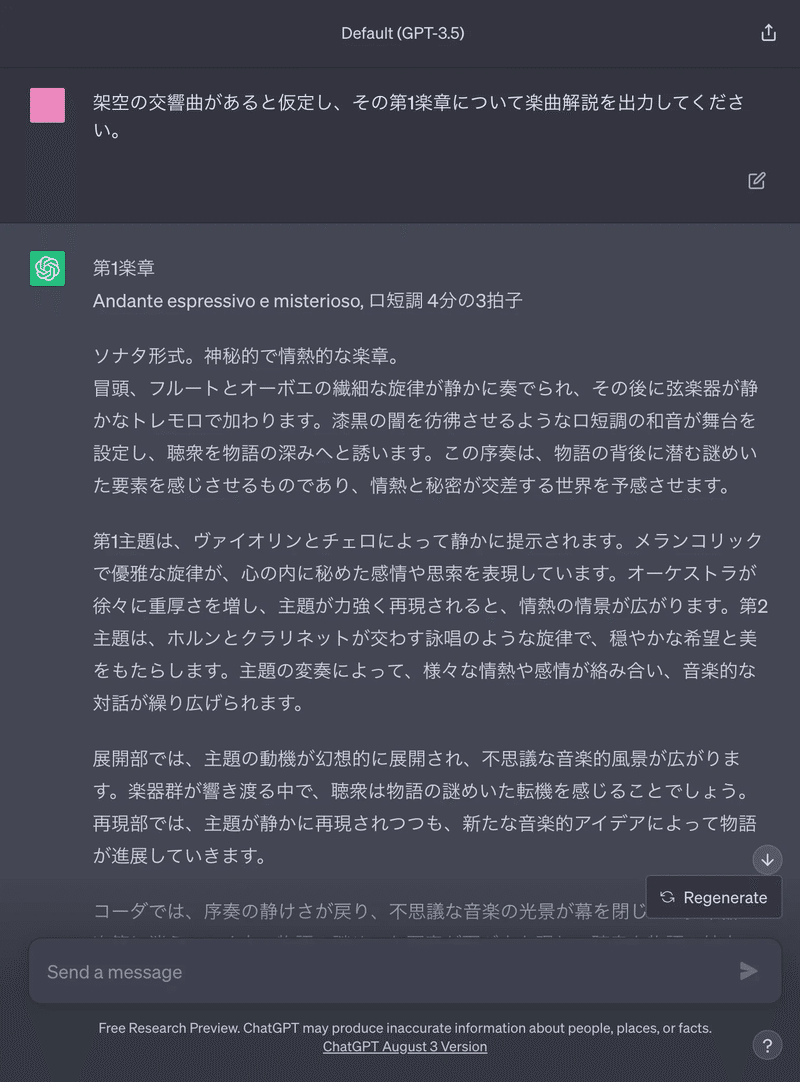
こっちのが良くね?
(おわり)
補遺:技術的解説
筆者はPython初学者につき、コードの粗はご容赦ください。
1. Wikipediaの楽曲解説を解析しよう
Wikipediaはクローラを用いたデータの収集を禁止している代わりに、データベースのダンプデータやAPIを提供しています。
今回は、MediaWiki APIを元に設計されたPython用のAPIライブラリ「Wikipedia」を使用して、記事を取得します。HTMLの解析には「Beautiful Soup 4」を用います。
pip install wikipedia beautifulsoup4モジュールをインポートします。reは正規表現操作のモジュールです。
import wikipedia
from bs4 import BeautifulSoup as bs4
import re「交響曲のタイトルを渡すと、該当するWikipediaのページから『楽曲構成っぽいセクション』のテキストを取得してくれる」関数を定義します。
まずは、ページ内のh2タグ(=セクションの見出し)を全て取得します。続いて、その中に楽曲の構成にまつわる見出しがあれば(厳密には、h2の子要素に「構成」という文字列を含むidのspanタグがあれば)、次に出現するh2(=「構成」の次のセクションに移り変わる箇所)までの兄弟要素をスキャンします。そして、h2見出し間にある平文を逐次取得します。
def get_forming(title):
try:
# 引数と一致するタイトルのwikipediaページを取得
single_page = wikipedia.page(title = title, auto_suggest = False, redirect = False)
if single_page is None:
print(title + " ... ⚠️Skipped: Page not found.⚠️")
return None
# ページ全体のHTML情報を取得
soup = bs4(single_page.html(), 'lxml')
# 不要なタグ・クラスに該当する要素を削除
for tag in soup.find_all(True, ["audio", "img"]):
tag.decompose()
for class_ in soup.find_all(True, {"class": ["noprint", "mw-editsection", "infobox", "reference"]}):
class_.decompose()
# 「構成」「曲の構成」「楽曲構成」などに該当するh2見出しを検索
headings = soup.find_all("h2")
for heading in headings:
heading_inner = heading.find("span", id = re.compile(r".*構成.*"))
if heading_inner:
break
else:
return None
# 「構成」セクションのテキストを格納
target_heading = heading_inner.parent
next_heading = target_heading.find_next_sibling("h2")
text_list = []
current_element = target_heading
while current_element.next_sibling != next_heading:
current_element = current_element.next_sibling
if current_element != "\n" and current_element.text.strip() != "":
text_list.append(current_element.text.strip())
# 不要な記号を削除し、1文に連結して返却
text_line = " ".join(text_list)
text_line = re.sub(r"\n|\r", "", text_line)
text_line = re.sub(r"\u200b|\u3000", " ", text_line)
if text_line is not None:
return text_line
# エラーハンドリング
# PageError: タイトル不一致のエラー。赤リンクで作成されていない記事とか
# DisambiguationError: 曖昧さ回避ページに飛んだエラー
# RedirectError: リダイレクトのエラー
except (wikipedia.exceptions.PageError, wikipedia.exceptions.DisambiguationError, wikipedia.exceptions.RedirectError):
return None交響曲のタイトルは、Wikipedia「交響曲の一覧」ページに含まれる、サイト内の別記事へのリンクを元に取得しています。この中には、赤リンク(記事タイトルは設定されているもののページとしての実体が無い)や、曖昧さ回避(項目名が重複したり曖昧だったりした場合、転送先をユーザーに選択させるページ)も含まれています。
このように、目的以外のページや実在しないページも、解析の対象に含んでしまいます。ですが、正常に情報を取得できる件数も充分に多いですから、ほとんど問題になりません。
wikipedia.set_lang("ja")
list_page = wikipedia.page(title = "交響曲の一覧")
forming_list = []
count = 0
# 「交響曲の一覧」ページから飛べる別記事(=だいたいは交響曲単独のページ)のタイトルを取得
titles = list(set(list_page.links))
total_titles = len(titles)
for i, title in enumerate(titles):
print(f"Processing {i + 1}/{total_titles} titles... ({title})")
single_forming = get_forming(title)
if single_forming is not None:
forming_list.append(single_forming + "\n")
count += 1
print("🎉🎉🎉 Done! 🎉🎉🎉")
print(f"Succeeded: {count}/{total_titles}")
with open("forming.txt", "w", encoding="utf-8", newline="\n") as f:
f.writelines(forming_list) 「交響曲の一覧」ページから取得できた記事リンクは、1213件です。
この中から最終的に、「構成」に類似する見出しのセクションを取得できた記事の数は、執筆時点で505件でした。

2. 単語のランキングを生成しよう
日本語の形態素解析エンジン「MeCab」を利用し、取得したテキストを解析します。使用する分かち書き辞書は、MeCabでも推奨されている「IPAdic」です。
pip install mecab-python3 ipadicインポートします。
また、先ほど出力したtxtファイルを学習源とするので、filesモジュールで予めアップロードしておきます。
import MeCab
import ipadic
import collections
from google.colab import filesuploaded = files.upload()
forming_list = open(list(uploaded.keys())[0], "r").readlines()品詞別に辞書を作ります。形態素の原形や品詞の種別を解析し、既存の語句に一致するものはカウントを増やします。一致しない場合は、新規のkeyとして登録します。
Counterは、collectionsモジュールに組み込まれている大変優秀なオブジェクトです。dictやtupleを用いて自力でデータ構造を実装せずとも、要素ごとの出現回数を含んだ辞書のコンテナを生成してくれます。
def get_hinshi_dic(text):
tagger = MeCab.Tagger(ipadic.MECAB_ARGS)
node = tagger.parseToNode(text)
dic_hinshi = {
"動詞": collections.Counter(),
"名詞": collections.Counter(),
"形容詞": collections.Counter(),
"副詞": collections.Counter()
}
while node:
splitted = node.feature.split(",")
hinshi = splitted[0] # 品詞の種類
genkei = splitted[6] # 原形
hyoso = node.surface # 表層形。文字列中のそのままの形。
if hinshi in dic_hinshi:
if hinshi == "名詞":
dic_hinshi[hinshi][hyoso] += 1
else:
dic_hinshi[hinshi][genkei] += 1
node = node.next
return dic_hinshi品詞ごとに辞書のランキングを出力します。ランキングに載せるだけしょうもないkeyは、予めリストで定義しています。辞書と照らし合わせて合致した語句は、辞書から削除します。
ランキングの生成は非常にシンプルで、most_commonメソッドを呼び出すだけです。keyと出現回数のtupleを出現頻度の高い順に並べ、リストとして返却してくれます。マジで優秀過ぎてエグいです。
forming_full_text = " ".join(forming_list)
dic_hinshi = get_hinshi_dic(forming_full_text)
print("品詞別ランキング")
print("")
print("- - - - - - - - - - - - - - -")
print("")
# あんまり参考にならない単語を結果から省くリスト
del_keys_doushi = ["する", "いる", "ある", "なる", "られる", "れる"]
for key in del_keys_doushi:
dic_hinshi["動詞"].pop(key, None)
c_doushi = collections.Counter(dic_hinshi["動詞"])
print("動詞ランキング:")
print(c_doushi.most_common(20))
del_keys_meishi = ["1", "2", "3", "4", "一", "二", "三", "四", "楽章"]
for key in del_keys_meishi:
dic_hinshi["名詞"].pop(key, None)
c_meishi = collections.Counter(dic_hinshi["名詞"])
print("名詞ランキング:")
print(c_meishi.most_common(20))
del_keys_keiyoushi = []
for key in del_keys_keiyoushi:
dic_hinshi["形容詞"].pop(key, None)
c_keiyoushi = collections.Counter(dic_hinshi["形容詞"])
print("形容詞ランキング:")
print(c_keiyoushi.most_common(20))
del_keys_fukushi = []
for key in del_keys_fukushi:
dic_hinshi["副詞"].pop(key, None)
c_fukushi = collections.Counter(dic_hinshi["副詞"])
print("副詞ランキング:")
print(c_fukushi.most_common(20))品詞別ランキング
- - - - - - - - - - - - - - -
動詞ランキング: [('現れる', 411), ('始まる', 298), ('続く', 246), ('奏す', 234), ('入る', 220), ('終わる', 217), ('繰り返す', 194), ('いく', 177), ('おる', 169), ('せる', 168), ('歌う', 166), ('くださる', 165), ('持つ', 145), ('奏でる', 140), ('用いる', 134), ('くる', 124), ('書く', 121), ('示す', 121), ('戻る', 117), ('基づく', 117)]
名詞ランキング: [('主題', 2883), ('部', 1828), ('拍子', 1440), ('長調', 1217), ('形式', 1168), ('分の', 1010), ('的', 982), ('曲', 789), ('ソナタ', 721), ('短調', 675), ('演奏', 661), ('再現', 619), ('旋律', 575), ('展開', 555), ('分', 539), ('動機', 527), ('提示', 525), ('よう', 496), ('ヴァイオリン', 493), ('音', 492)]
形容詞ランキング: [('短い', 165), ('ない', 149), ('長い', 102), ('力強い', 94), ('明るい', 78), ('強い', 72), ('激しい', 70), ('速い', 57), ('美しい', 56), ('多い', 54), ('大きい', 53), ('新しい', 49), ('暗い', 41), ('高い', 33), ('珍しい', 29), ('輝かしい', 28), ('遅い', 24), ('重々しい', 23), ('荒々しい', 22), ('緩い', 22)]
副詞ランキング: [('再び', 146), ('やがて', 118), ('次第に', 79), ('そのまま', 77), ('すぐ', 74), ('さらに', 62), ('突然', 41), ('ほぼ', 41), ('まず', 39), ('やや', 36), ('パッ', 35), ('最も', 35), ('よく', 35), ('やはり', 34), ('かなり', 32), ('ゆっくり', 31), ('徐々に', 30), ('同じく', 29), ('きわめて', 28), ('ほとんど', 27)]
3. 架空の楽曲解説を生成しよう
マルコフ連鎖の文章ジェネレーターである「markovify」ライブラリを使用します。
pip install markovifyimport markovify辞書の作成にも用いたMeCabを用いて、テキストデータを「分かち書き」します。
日本語は英語などとは異なり、形態素の間がブランクで明確に分かれているわけではありません。ですからマルコフ連鎖の重み付けに先立って、まずはことばの分割ポイントを解析し、区切りを記号に置き換える処理が必要になります。これが、「分かち書き」です。
勁発すれば江潮落ちるが如く🤜
↓
勁 / 発すれ / ば / 江潮 / 落ちる / が / 如く / 🤜
ただ、いざテキストを出力する時に分かち書きされたままだと、日本語として読みにくいことこの上ないです。
そのため出力時には、英数字間を除いた文字どうしの間に区切り文字を残さないよう、正規表現による置換パターンを定義しています。
def get_wakatied_list(forming_list):
wakati = MeCab.Tagger(ipadic.MECAB_ARGS + " -Owakati")
wakatied_list = []
for forming_text in forming_list:
wakatied_forming = wakati.parse(forming_text)
wakatied_list.append(wakatied_forming)
return wakatied_list
def format_text(text):
text = re.sub(r"((?<=[^a-zA-Z0-9])\s(?=\w))|((?<=\w)\s(?=[^a-zA-Z0-9]))", "", text)
return text早速、マルコフ連鎖でテキストを生成します。
以下は、特別な制限なしに、とりあえずテキストを生成してみる処理です。
state_size = 4
wakatied_list = get_wakatied_list(forming_list)
text_model = markovify.NewlineText(wakatied_list, state_size=state_size, well_formed=False)
for i in range(10):
try:
sentence = text_model.make_sentence()
if sentence:
sentence = format_text(sentence)
print(sentence)
except markovify.text.ParamError:
pass
else:
passstate_sizeは、単語を生成する際に遡って参照する単語の連結数です。N階マルコフ連鎖の、「N」の部分にあたります。
この値が小さくなればなるほど、語句どうしの依存関係が希薄になります。文章に自由度が生まれる一方で、文脈は薄れます。
逆に、値が大きいと生成の幅は制限され、より意味理解が容易な高クオリティのテキストに近付きます。その反面、文意の自由度や、そもそも正常に生成できる確率は下がります。
たとえばstate_sizeが4のとき、筆者の環境では下記のようなテキストが5〜7個ほど出力されることが多かったです。正常であれば10個出力されるはずなので、成功確率は概ね6割といったところです。
全3楽章の構成で、演奏時間は約30分。第1楽章アレグロハ長調、4分の3拍子スケルツォ風のメヌエット。変ホ長調、8分の12拍子、ソナタ形式。
文字数の上限を設定したいときは、make_short_sentenceメソッドを用います。
たとえば、TwitterことXに投稿できる文字数に収めたければ、引数に140を渡します。
state_size = 4
wakatied_list = get_wakatied_list(forming_list)
text_model = markovify.NewlineText(wakatied_list, state_size=state_size, well_formed=False)
for i in range(10):
try:
sentence = text_model.make_short_sentence(140)
if sentence:
sentence = format_text(sentence)
print(sentence)
except markovify.text.ParamError:
pass
else:
passまた、make_sentence_with_startメソッドを使うことで、特定の語群から始まる文章を出力することも可能です。
以下は「第◯楽章」から始まる文章を、第1楽章から第4楽章までの合計4つ分、出力する処理です。文章にボリュームを確保したかったので、100回の試行の中で300文字に達した場合、for文をbreakするようにしています。
state_size = 3
wakatied_list = get_wakatied_list(forming_list)
text_model = markovify.NewlineText(wakatied_list, state_size=state_size, well_formed=False)
for i in range(4):
for j in range(100):
try:
sentence = text_model.make_sentence_with_start(beginning=f"第 {i+1} 楽章", strict=False)
if sentence and len(sentence) > 300:
sentence = format_text(sentence)
print(sentence)
break
except markovify.text.ParamError:
pass
else:
pass「第2楽章」から始まる文章の例です。state_sizeは甘めに3で設定したので、日本語としての流暢さはやや失われています。
第2楽章Andante con moto-Allegro di moltoRomanza:AndanteScherzo:PrestoLargo-Finale:Allegro molto—Presto( 「終楽章がよく知られる部分である。性急な中間部をはさみ、再び第1主題「人間の主題」が改変されている。カッコ内は各楽章の終結部は、主要主題は変奏され、交響曲第9番のスケルツォのトリオに似ている。しかしながら第2楽章Andantino in modo di canzona-Piùmosso(Andante)ニ短調。管弦楽による序奏(16小節まで)吹き通すようにしてフルート独奏が聞かれる。再利用されたとき、チェロ独奏と受け継がれてゆく。第4楽章フィナーレ:テンポ・ディ・メヌエットニ長調、8分の3拍子-4分の4拍子、ソナタ形式。冒頭は2つに分かれ、それぞれ反復され、すぐにハ長調の「運命」を象徴している。推移部は主に第1主題ではじまる。管楽器のファンファーレの後にテンポが落ち、Aの3部形式。第1楽章アレグロ変ロ長調、4分の4拍子、ソナタ形式。弦楽器のみで演奏される構成のためか、中間部ののち、バッハの主題が聞こえる。展開部はやはりトレモロで開始し、短調へと転調しつつ、主題の近親調の変ロ長調、4分の3拍子、ソナタ形式。
なお、実はこの方法だと、実際のアウトプットが300文字に満たない場合もあります。前述の「分かち書き」の区切りスペースを含めて300文字を超えればbreakする仕組みであるために、区切り文字を削除して連結した出力文は、元々よりも短くなってしまうからです。
こればかりは仕方ないので、理想のテキストが出力されるまで回転数を上げて生成し続けるしかなさそうです。
元も子もないけど
「マルコフ連鎖ガチャ」のリセマラに頼り続けるくらいなら、素直にGPTに任せるのが賢明だと思います。