
COVID-19 各日データの集計を自動化してみた(データ取得編)

「国・地域の感染状況」を集計するプログラムを例に集計の自動化をどのように実現するのかをお話ししていきます
本記事では3つに分けた段階のうち最初の、データをどのように取得するかを説明します
厚労省ホームページの構成
厚労省のホームページは以下のような構成になっています
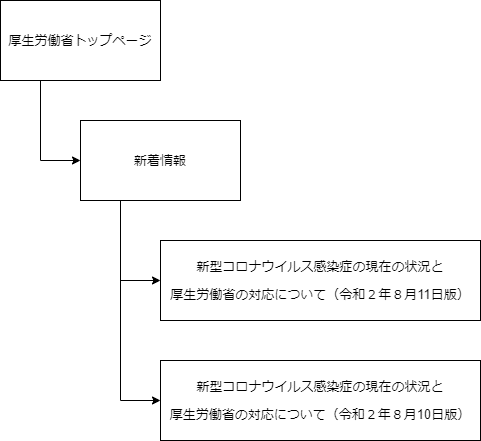
また、今回必要なページは以下になります

国・地域の毎日の感染者数・死亡者数は「新型コロナウイルス感染症の…」のページに記載されています
このURL(ホームページにアクセスするためのアドレス)は年月日とは無関係のため、取得したい年月日からURLを知ることはできません
このため、新着情報からリンクをたどっていく必要があります
新着情報ページには、日ごとに掲載したページのタイトルとリンクが貼られています
【余談】
新着情報ページを見ると厚労省の職員さんが土日たがわず作業されていることがわかります
また、平日の掲載量は大企業のプレスリリースにひけをとりません
大変なご苦労があって、国民に必要なデータが毎日提供されていると感じます
各日データの取得方法
取得したい情報とホームページの構成から、以下の段取りを考えました
- 新着情報ページを取得
- 新着情報ページから特定の年月日の「新型コロナウイルス感染症の…」のリンクを探す
- 「新型コロナウイルス感染症の…」ページを取得
これを「Node-RED」のプログラムにしたのが以下になります

各ノードのうち、オレンジ色のノード(白抜きでfと書かれた箱)はユーザーがプログラムの文章を書かなければいけない部分になります(逆に言うとそれ以外はプログラムの文章より簡単な”設定”で済みます)
「Node-RED」は極力、図を使って誰でもプログラム(や自動化の処理)を作れることを目指しています
ちょっと時間をかけて段取りを整えれば、それを具現化できるツールになっています
気を付ける点
1.情報元のルールに従おう
利用する情報は情報元の権利を害さないようにしましょう
厚生労働省の場合は下記にルールが記載されています
2.情報元にアクセスする頻度
情報元のコンピュータ(サーバー)に過度の負荷をかけないようにしましょう
プログラムによっては1秒間に100回など相手方に迷惑となるアクセスになる場合があります(上記の集計プログラムは1日2回のアクセスになります)
おわりに
次回は、取得したホームページの内容からその日の感染状況のデータを抜粋する方法についてお話しします