
12 Days of OpenAIから読み解く、生成AI 2025年のトレンド

こんにちは。株式会社Algomaticの大野です。
今月は、OpenAIやGoogleから、インパクトの大きなリリースがありました。本記事では、OpenAIの最新発表を中心にそれらの要点と、それを踏まえた今後のAI領域のトレンドに関して考察をシェアします。
💡 本記事でお話すること
■ 最新リリースのハイライト
①新しい最高級・最高性能モデル「o1」、「o3」
②「文字」だけでない、「動画・音声」における進化
③「チャット」を超えた「エージェント」
■ AI領域の5つの潮流
①「よく学ぶ」から「よく考える」へ
②「知らない」から「豊富な文脈理解」へ
③「モデル」から「アプリ」へ
④「単独ツール」から「常にあるもの」へ
⑤「チャット」から「エージェント」へ
※ なお:
・解説用に作ったメモを、ほぼそのまま公開しています。読みづらいところがあるかもしれません
・AI領域に詳しくない方でも理解しやすく頭に残りやすいよう、「網羅的・精緻に」より「要点を・簡単に」書いております
・詳細で正確な情報は、OpenAIの公式リリースをご参照ください
💡 PIVOTさんにて、同様の内容を解説しております。よければこちらもご覧ください↓
12 Days of OpenAI
日本時間2024年12月5日、OpenAIのX(旧Twitter)公式アカウントで「12日間連続で新しい発表を行う」という告知が突然行われました。

アメリカではサンクスギビング以降、ホリデームードに入るため、この時期に新リリースを連発するのは、珍しいことのように見えます。
そんな年末に、まるでクリスマスまでの日数をカウントダウンする“アドベントカレンダー”のようなスタイルで連日リリースを打ち出した点は、異例だったのではないかと思います。

なぜこんなキャンペーンを?
AI業界では、Google、OpenAI、Anthropicといったビッグテック同士の激しい競争が繰り広げられています。世界トップクラスの企業が連携を組んだり、互いに覇権争いをするという、熾烈な状況です。

そんな名k、今回の12日連続リリースの背景には、「OpenAIこそがAI市場のカテゴリリーダーである」という印象を強く与える狙いがあったのではないか、と推測できます。競合が追従しづらい、ホリデーシーズンに大量のアナウンスをまとめて出すことも、そうした印象付けをするための戦略のようにも見えます。
何が発表されたか?
12日間で、予告通り大小さまざまなトピックが発表されました。下記はリリースのタイトル一覧です。

ただ、内容が盛り沢山なので、本記事では、特に重要と思われ、下記3つのテーマに絞って、それに関連するリリースを中心に解説します。

① 新しい最高級・最高性能モデル「o1」、「o3」
o1:数理系分野で、専門家の壁を突破
新モデル「o1」は、数学、プログラミング、科学など、思考が要される分野で専門家を超える性能を記録したモデルです。

ある数学の試験(AIME2024)にて、93%という正解率を出していますが、これは全米上位500位に入る成績で、米国数学オリンピック選抜基準を上回る成績です。
プログラミングも同様に、ある競技プログラミングコンテストサイト(Codeforces)にで、上位11%の成績を達成しました。
更に、化学・物理学・生物学の分野のベンチマークテスト(GPQA)において、博士号保持者の平均スコア69.7%を大きく上回る、78%の正解率を達成しています。
これらの成果は、大規模言語モデルが「記憶ベースの回答」から「論理的な推論に基づく問題解決」に進化している証のように見えます。
「思考」するモデル
とても簡単にいうと、o1は回答をする前に「思考」をするモデルです。

これまで、従来のモデルでは、質問を受け次に回答の生成をしていたのに対し、まずは思考プロセスを生成し、それに基づき回答をします。
これまでも、例えば「ステップバイステップに考えて」とお願いすると、回答精度が上がることを期待できるChain-of-Thoughtという手法があったわけですが、そうした考えをモデルアーキテクチャに組み込み、思考プロセス自体を訓練したモデルといえます。
「回答する前に自分の頭でよく考えてから回答しよう」「その考え方そのものを学ぼう」といったアプローチで、精度が上がるというのは、直感的に、人と似ていて興味深いですね。
例 & UI上にも表示される思考時間
o1が思考過程を持つことは、ユーザーインターフェース上でも表現されています。
例えば、「ビジネスメディアPIVOTの競争戦略を教えて」といったお願いをしてみましょう。

右側のo1シリーズでは、回答前に明示的に「思考時間」を設けていることがわかります。上記の例では、1分6秒思考していますね。
例えば、そもそもPIVOTってなんだろう、メディアにおける一般論としての成長戦略ってなんだろう、PIVOT独自の要素はなんだろう等々、人が考えるように、論点を洗い出しながら、一つずつ思考して、それを踏まえて結果を返しているように捉えられます。
この例における1分強という思考時間、ITサービスとしては遅く感じますが、人と比べると驚異的な速さですよね。

実際に試していただいたり、内容を見ていただくと、o1シリーズのほうが、網羅的かつ深い思考ができている印象です。
ChatGPT Pro & o1 pro mode
そして同時にリリースされたのが、ChatGPT Proというハイエンドなサブスクプランです。そのプランに含まれるものには、モデルへの無制限アクセス等色々ありますが、一つの大きな特徴は、o1がより深く考えることができるようになったということです。

思考を、より豊富な計算資源とともに長く深く思考できるようにすることで、成果向上を期待できるというものです。
推論時に深く思考するoシリーズのようなアプローチには、これまでと違ったかかり方でコストがかかります。
モデルの事前学習にかかるコストは、(もちろん)そのモデルの利用量に対してはスケールしません。一度学習してしまえば、追加の学習コストなく使うことができるため、事前学習にかかるコストは利用量に対するスケールメリットがあるということです。一方で、モデルの推論時にかかるコストは利用のたびに発生するため、利用量にとともにスケールしてしまいます。利用量に対するスケールメリットがないということです。
そうした背景もあり、今回は、より深い思考をするために、別のハイエンドプランで提供しているように見えます。
リリースでは、「開発者や研究者等プロフェッショナルユースを想定している」と言及されていました。
Googleの対抗リリース
ここまで、o1シリーズすごいねという話だったわけですが、o1リリースからたった二週間で、Googleが対抗するリリースを出してきました。同様に思考プロセスを持つモデル「Gemini 2.0 Flash Thinking Exp」がリリースされました。

既に開発されストックされていたとは思いますが、この年末のホリデーシーズンに、この速さで対抗リリースをするGoogleの瞬発力もすごいですよね。
AI市場の争いの熾烈さ、カテゴリリーダーとしての認知の重要性もよくわかります。
更にOpenAIの「o3」アナウンス
しかし、それだけでは終わらず、更に翌日OpenAIが「o3」という更に深く思考できる新モデルを、アナウンスしました。

o3は、o1をそれぞれのベンチマークにて大きく超えたモデルでした。

今回本発表をしていたOpenAIのリサーチャー、マークさんが自身の競技プログラミングのレーティング2500を超える成績を出した、と言及していたのも印象的でした。
AGIベンチマークにて、人を超える
最も印象的だったのは、AGIへの到達度を図る一つのベンチマークである「Arc AGI」にて、人間の平均スコアを上回る成績を出したことです。

上記のような、人からすると簡単なタスクが、AIには難しいことがあります。Arc AGIは、そうしたこれまでAIにとって苦手だった「未知のルールを推測し、新しいパターンを見抜く」能力を測るベンチマークです。

そのベンチマークにて、人間の平均85%を上回る、87.5%というスコアを出しました。また上記グラフには、横軸リリース日、縦軸スコアとして、これまでのモデルのスコアがプロットされていますが、単一の指標とはいえこの短期間で大きな進化をしていることがよくわかります。
1タスク、15万円以上
ただし、o3には、これまでと桁が違うコストがかかることもわかっています。

o1シリーズが1タスクあたりかかっても数ドルだったのに対し、o3の今回ハイスコアを出した高性能なモードでは、少なくとも1000ドル以上のコストがかかります。
前述の通り、推論時により深く考えるアプローチには、性能とコストにトレードオフがあるということがよくわかります。推論毎のコストを上げるほど、性能を上げやすい構造であるということです。
目下、多くのタスクにおいては、人間よりo3のほうがコストがかかってしまうかもしれません。どういったタスクに使うか、というポイントが少なくとも足元は重要そうに見えます。
o3 mini

こうした課題に対応すべく、コスト効率が良いモデルとして、o3 miniというモデルもアナウンスされました。o1 miniというモデルも出ているのですが、そちらの後継になります。
タスクの難易度に応じて、推論時間(思考する時間)を3段階で調整することができるモデルです。簡単なタスクでは瞬時に結果を返しコストを抑える、難しいタスクではよく考え性能を上げる、といったことを調整できるモデルになっています。
② 「文字」だけでない、「動画・音声」における進化
文字以外の動画、音声領域でも進化しました、という話になります。
Advanced Voice Mode:ChatGPTとビデオ通話可能に
こちら、簡単にいうと、ChatGPTとビデオ通話する機能がリリースされました。これまでも、耳だけでの対話はできていたわけですが、映像込で会話できる機能がリリースされた、というものになっています。
百聞は一見に如かず、ということで、ぜひ下記デモを見ていただくと良いかと思います。

動画の例にもあるように、すべてを口頭で説明するのはなかなか面倒だったりするわけです。そんなときに映像も込で会話することができると便利ですよね。AIにとって、音声対話のみでは捉えられなかった非言語的な情報や視覚的な文脈をより文脈を理解しやすくなります。それによって、物理的なものを示しながらの説明などができるようになります。
ただし、この機能リリースについては過去既にアナウンスはされていたものが、ついに出た、という位置づけでして、そこまでサプライズはなかったかと思います。
Googleでも同様に、こうしたマルチモーダル的な路線は繰り返しアナウンスされており、業界としてそうした流れがあると捉えるとよいかと思っています。
Sora:動画を生成できるように

これまでOpenAIは既にテキスト・音声・画像を生成するサービスを提供していたわけですが、新たに動画を生成できるサービスをリリースしました、というものです。
世界はテキストだけではありません。AGIへの道のりとして、ビデオは物理的な世界の理解、物体間の因果関係、時系列での変化を学ぶために、重要な訓練環境でもあります。
こちらも、百聞は一見に如かずということで、下記サイトを見てみましょう。生成された動画と、その動画を生成するためのプロンプトが並んでいます。

動画生成ツール自体は新しいものではありませんが、今回は実用的な「UI/UX」が作り込まれていた印象でした。
リリースでも言及されていましたが「既に映画一本が作れるレベルではないが、クリエイターが使い始められうもの」という印象です。
下記、特に印象的な機能でした。
機能例:ストーリーボード
下記、動画を見ていただくとよくわかるのですが、連続するシーンごとにプロンプトを記述することで、異なるシーンを一貫性を持って繋いだ一連の映像を生成することができます。


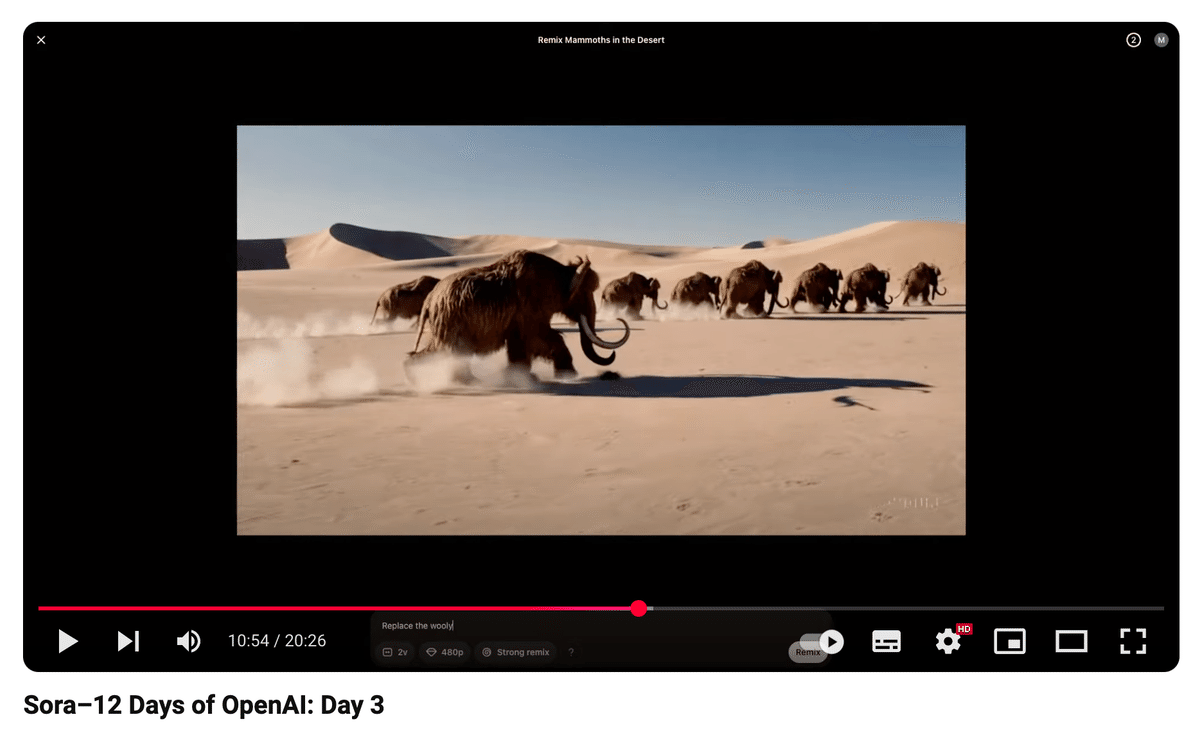
機能例:Remix
こちらも動画を見ていただくと速いのですが、動画の内容をプロンプトによって編集することができます。下記デモでは、マンモスが走る映像におけるマンモスをロボットに置き換えています。

Veo2:Googleによる対抗リリース再び
動画生成においても、Soraリリースから一週間で、Googleによる対抗リリースに見えるリリースがありました。Veo2です。

Veoは以前からあったGoogleの動画生成モデルですが、その最新モデルがアナウンスされました。なお、サービスとしてはまだ一般公開はされておらず、Waiting Listへの登録が可能になっています。
一部出てきている生成結果を見る限り、Veo2のほうが動画の生成精度は高そうにも見えます。
総じて、OpenAIやGoogleが優れたモデル/UX・アプリケーションをリリースしてきたことで、これから動画生成そのものが民主化する流れになりそうです。
③「チャット」を超えた「エージェント」
「AIエージェント」という言葉を、皆様聞いたことあるのではないでしょうか。今回のOpenAIの発表でもそうですし、これまでの主要テック企業による発表の中で今年、たびたび「AI Agent」というキーワーが言及されてきました。
AIエージェントとは
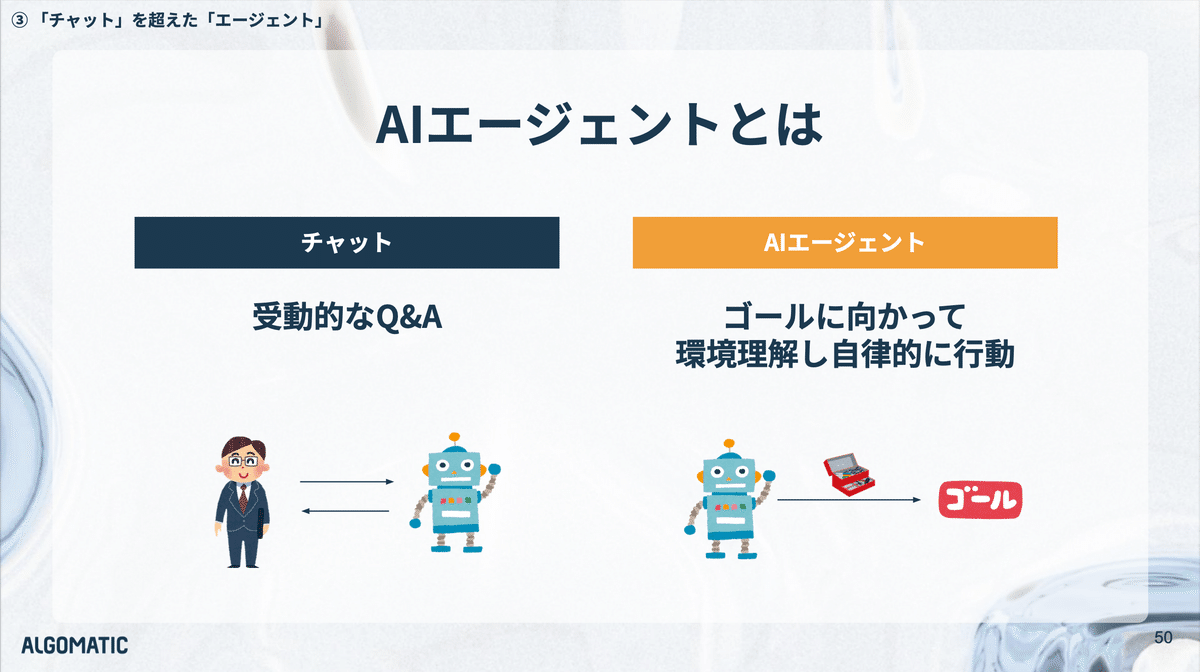
AIエージェントとはなにか。従来のチャットベースのAIが、質問に対する応答という受動的な役割に留まっていたのに対し、AIエージェントは、環境を認識しながら、目的に向けて、自律的に適切なアクションを選択し行動します。
エージェントに関わるリリースは今回は2つありました。
Canvas:テキストやプログラムを共同編集
一つは「Canvas」というChatGPT上の機能です。下記のデモを見ていただくと早いですが、ChatGPTの右側に共同編集する成果物が表示され、これをAIと共に編集していくという体験が実現されています。

上記動画の例では、書かれた文章に対して「物理学の教授としてコメントして」と依頼すると、AIが「書かれている文章」を認識し、様々な可能なアクションの中から「コメント」を選択し、「適切な箇所をハイライト」しながら、コメントしてくれます。人と協働する際に、Google DocsやNotionにコメントをもらうような体験です。
デスクトップアプリ:デスクトップでも共同編集
Canvasは、ChatGPTのブラウザ上での話でした。ただ実際は、ChatGPTのブラウザ外でも我々は作業するわけで、そうしたケースを意識した機能が、デスクトップアプリからリリースされました。
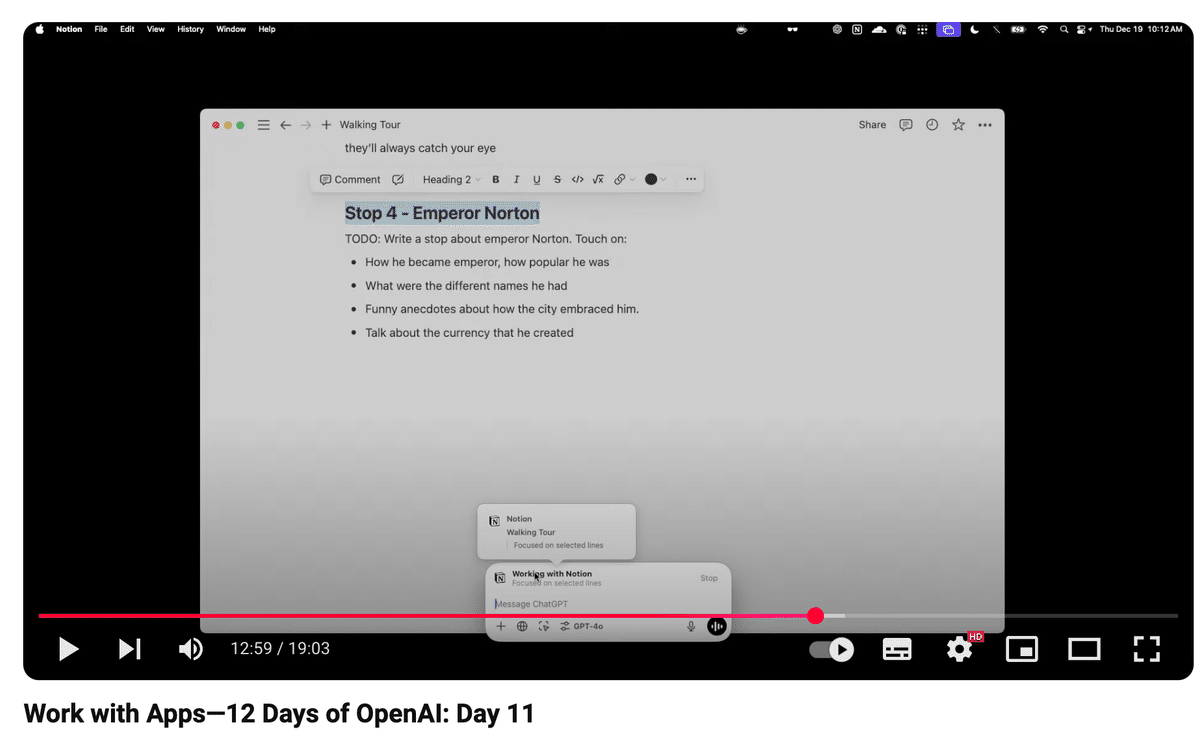
上記動画の例ではNotion上で、文章を作成しています。Notionに記載されている文章のタイトルをハイライトしながら、ChatGPTに「このセクションの文章を書いて」のように自然言語で指示をすると、サーチなど必要なアクションをしながら文章を書いてくれます。「他の文章と文体をあわせて」のようなお願いをすると文体を合わせた調整もできるわけですが、それはまさに文章の全体を、コンテキストとして知覚できているから可能なことです。
このように、AIが「単なる対話相手」から「環境を理解し目的に向かって自律的に行動する協働パートナー」になっていることがわかります。
AI領域の5つの潮流
ここまで、リリースを解釈込で説明してきました。次に、こうしたリリースから何が学びとして得られるか、今後のAI領域の潮流について、お話します。

「よく学ぶ」から「よく考える」へ

大規模言語モデルの進化は、これまで「より多くのデータからより多く学ぶ」という方向性で実現してきました。学ぶ量を増やすことで、性能改善のブレイクスルーがおきた、というのがこれまででした。
しかし、実は最近、その事前学習による効果が収束してきているのでは、とも考えられています。ちょうど直近の人工知能系の国際学会(NeurIPS)でもイリヤサツキバー氏が、「事前学習はもう終わりである」といった話をされていました。そこには、計算能力が向上する一方で、質の高い学習データの量には限界がある、という背景があります。

では今後はどう進化するか?それが「よく考える」へのシフトです。
今回のOpenAIのリリースは、「推論時の思考」に、成長のアップサイドがありそうな印象を受けるものでした。o1、o3シリーズそれぞれ、推論時に時間と計算リソースをかけて思考過程を生成してから回答する、その思考プロセスそのものを訓練する、というアプローチです。
これは、ものすごく重要なブレイクスルーに見えます。もともと事前学習のデータ量を増やすことによるブレイクスルーも、OpenAIによって起こされたわけですが、今回は次のパラダイムである推論側のブレイクスルーも起こしているように見えます。
しかし、このアプローチには既に見えている課題もあります。それは、コストが利用量(推論の量)により、スケールしてしまうということです。事前学習のコストが一度の投資で継続的な価値を生む「固定費型」であるのに対し、思考型推論のコストは利用量に比例して増加する「変動費型」の特性を持つとも言えます。
ゆえに、今後は推論に適したハードの発明が重要になりそうです。従来型のGPUより、推論に特化した新しいハードウェアアーキテクチャの重要性が増してきます。もちろん、これまでも推論におけるハードウェアは重要だったわけですが、今回の推論側でのブレイクスルーにより、これまでとは更に桁違いに推論時の計算量が増えるという前提に立つと、その重要性はより大きくなりそうです。OpenAIが、去年から半導体開発に乗り出す話をしていましたが、ここまで見据えていたのかもしれません。
「知らない」から「豊富な文脈理解」へ

大規模言語モデルを用いたアプリケーションが価値を発揮するうえで、最も本質的な課題の一つは「コンテキストのギャップ」でした。普遍的なイシュー(例えば教科書にのっているような話)に関しては優れた能力を示す一方、特定の文脈に依存するイシュー(例えば特定の人や組織に関する課題解決など)については発揮できる価値が限定的であるという課題を抱えていました。
例えば、多くのチャットインターフェースを持つAIアプリケーションでは、AIからするとチャットに入力された情報しかわかりません。人間の活動は、豊富な文脈の中で行われているため、機能するタイミングが限られてしまっていました。

ではどうするか。シンプルに、より広く文脈を知れば良い、ということになります。
今回のリリースで印象的だったのは、AIに文脈情報をシェアするための機能や進化が多いことでした。チャット指示だけでなく、画像はもちろん、音声ビデオ通話、映像、ファイル、別アプリなど、多様なモダリティを通して、より良く文脈を把握することができるような進化がありました。
今後も、AIシステムの実用的な価値を大きく向上させるためには、豊富なコンテキストを取り込めるようにすることが一つ重要になっていくと思えるリリースでした。
「モデル」から「アプリ」へ

過去のリリースでは、「モデル」の性能競争系の話が多くされていた印象でした。今回もそうした話もあった一方で、プリケーションに関する話が比較的に増えたように見えました。Soraの質の高いインターフェース、ChatGPTのCanvas/Projects機能、デスクトップアプリの展開しかり、ユーザー体験を重視した開発が増えてきた印象です。
そもそも、我々人は「モデル」そのものがほしいわけではありません。モデルを活用して、仕事や生活の実課題を解決したいわけです。モデルは「素材」のようなものです。どれほど高性能な素材であっても、それ自体で価値を生むことは多くありません。価値は、その素材を加工し、実用的なソリューションに変換することで生み出されるようになります。これまでの進化で、素材はある程度良いものができてきたので、次に実価値を出せるようなソリューション化をしていきましょうという、自然なシフトとも捉えられます。今後、より、ユーザーが求める「使い勝手」「利便性」「現実における解決力」に焦点が当たっていきそうです。
また、競争戦略的な意味合いを考えてみると、中長期的には基盤モデルの開発自体が十分な資金と時間をかければ作ることができ、ある種コモディティ化しつつある中で、持続的な競争優位性を確立するためには、各プレイヤーにとっては、モデル開発でのリードがある間に、次に長期的な価値を持つアセットに変換することが重要です。その一つがアプリケーションとも捉えられます。人々が、OpenAIこそカテゴリーリーダーだと認知して、直接サービスを利用しにくる、使い続ける、これはモデル性能云々でない、一つの重要なビジネス的なアセットになるわけです。
アプリケーションの成熟は、AI技術の社会実装を加速させるでしょう。基盤モデルそのものと異なり、実用的なアプリケーションは、すぐに価値を提供できます。来年は、これまで以上に、AIサービスの普及が進む年になるだろうと予想されます。
「単独ツール」から「常にあるもの」へ

これまで、例えばChatGPTなどのAIツールは必要なときに呼び出す「独立したアプリケーション」でした。こういうユースケースでは、ChatGPTが使えると想起し、ユーザ自ら利用しにいく必要がありました。しかし、自然な作業フローを中断して、このようにアプリを切り替えてというのは、ハードルが高いもので、AI活用の障壁となっていました。
今回印象的だったのは、AIをワークフローに溶け込ませるような体験でした。Canvas/Projectsのような、ユーザが作業する場そのものを提供することもそうですし、Appleデバイスでの様々なアプリケーションからシームレスにChatGPTを呼び出せるような体験しかりです。
そのように、様々なワークフローに、常にAIが潜んでいる状況を作ることが今後の鍵になっていくと考えられます。
OpenAIは、デバイスや顧客接点を持つAppleやMicrosoftと提携しているわけですが、その提携により意味が出てきそうです。一方で、Googleのような既にそうしたユーザー接点・ユーザーの作業場であるアプリケーションを大量に抑えているプレイヤーがより強くなりそうな流れでもあります。
「チャット」から「エージェント」へ

既に言及した通り、環境を認識し自律的に行動するエージェントの開発が、今後の進化の一つの潮流になっていくと考えています。
例えば、人が協働することをイメージするとわかりやすいのですが、その人をチャットインターフェースのみの中に閉じ込める(チャットアプリ以外は使えませんとする)ことはしないですよね。本当に価値を出して働いてもらおうと思ったら、様々なツールへのアクセス権を与えるわけですし、チャット以外に現れる幅広いコンテキストをシェアするはずです。
同様に、AIシステムがより大きな価値を出すためにも、できるだけ広く世界を知覚し、働きかけられる必要があります。(過去、下記のnoteでも似たお話をしています)
この進化により、これまで、未だ人間にしか解きづらかったタスクが、AIにも解けるようになっていくと思われます。
AIエージェントは、改めて今後の鍵になると考えています。
Algomaticで、共に未来を作りませんか?
私たちAlgomaticは、AIの進化によって来るべき未来を作っているスタートアップです。
1年8ヶ月前の創業から、まさに上記の「モデルからアプリへ」「チャットからエージェントへ」「豊富な文脈理解へ」のような流れを見据え、AIネイティブなサービスの開発をしてきました。
開発しているサービスを通して、実際にお客様に大きな価値を届けながら、未来を作れていると手応えを感じています。
技術革新のど真ん中で、次の時代を共に作りたい方、ぜひご連絡ください。
リサーチャー、エンジニア、デザイナーの方はもちろん、新たな事業を生み出したい事業家、BizDevの方もお待ちしております。
※ 参考:本記事の内容、スライド版
※ 参考:過去2024年5月に、下記noteで、OpenAIとGoogleのリリースの比較もしております。
本記事はAlgomaticで開催している アドベントカレンダー2024の23日目の記事です。メンバーによる他の投稿もよければご覧ください 🎄📅