
Amazonの人気商品の情報を自動で取得しよう カスタマイズ編

こんにちは。
Pythonでできる100のこと中の人のりょう(@suzu_1996)です。カッコの中はtwitterのIDです。是非フォローしてね。
今回はAmazonの人気商品の情報を自動で取得しよう ツール紹介編で紹介したツールのコードについて紹介していきます。
この記事はツール紹介編の続編となりますので、「何のコード紹介やねん!」と思った方は、是非以下リンクから何のツールを作ったか把握してから戻ってきてください。
コードの全体を一気に張り付けると長くなってしまうので、関数ごとにポイント等を紹介する形とします。
■コード紹介 概要
早速、コードの内容を紹介します。このコードは、
・main()
・access_amazon()
・extract_category()
・save_csv(category_name, amazon_ranking_list)
の4つの関数で構成されています。早速1つ1つ見ていきましょう。
■コード紹介① main()関数
def main():
print("各カテゴリーのランキング上位50位の情報を抽出します。")
access_amazon()main()関数はいたってシンプルにこれから何をするのかを表示するのとaccess_amazon()関数を呼び出しているのみ。
僕がコーディングするときは基本こんな感じで、何をしているのかの表示と関数呼び出しだけのシンプルな構造になります。
■コード紹介➁-1 access_amazon()関数
access_amazon():
category_list = extract_category()
for category_name, url in category_list:
html = request.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
main_item_indexs = soup.find_all("li", "zg-item-immersion")
amazon_ranking_list = []
for main_item_index in main_item_indexs:
rank = main_item_index.find("span", "zg-badge-text").get_text()
title = main_item_index.find("div", "p13n-sc-truncate").get_text().lstrip()
item_urls = "https://www.amazon.co.jp" + main_item_index.find("a").attrs['href']
amazon_ranking_list.append([rank, title, item_urls])
save_csv(category_name, amazon_ranking_list)access_amazon()関数はmain()関数から呼び出されて、実際に情報を抽出する関数です。ここが今回のツールの心臓部です。ここを理解するだけで好きな情報を自由自在に取得できるようになります。
この関数はextract_category()関数で取得したカテゴリーのURLにアクセスすることで情報(今回は順位とタイトルとURL)を取得してリストを作り、save_csv()関数にカテゴリー名と対応するリストを投げて保存するといった流れです。
■コード紹介➁-2 access_amazon()関数をカスタマイズしよう
まず、urlopen()関数やfind_all()関数などを使うためにrequestとBeautifulSoupをインポートしてください(何言ってるかわからなかったらツール紹介編でpythonファイルを配っているのでコードの上の部分を確認してみてください。import ○○とか書いてあるところです)。ダウンロードしたファイルを改造する場合は必要ないです。
では早速ランキング情報を抽出していきましょう。わかりやすく家電&カメラのカテゴリーにアクセスしたとして説明していきます。
Amazonでの家電&カメラのランキングページは以下のような画面です。

検証(f12ボタンクリック)でこのページのHTMLを表示するとこんな感じ。

抽出したい情報が載っているのはこの<div id="zg-center-div">の部分です。さらに詳しく見ていきましょう。
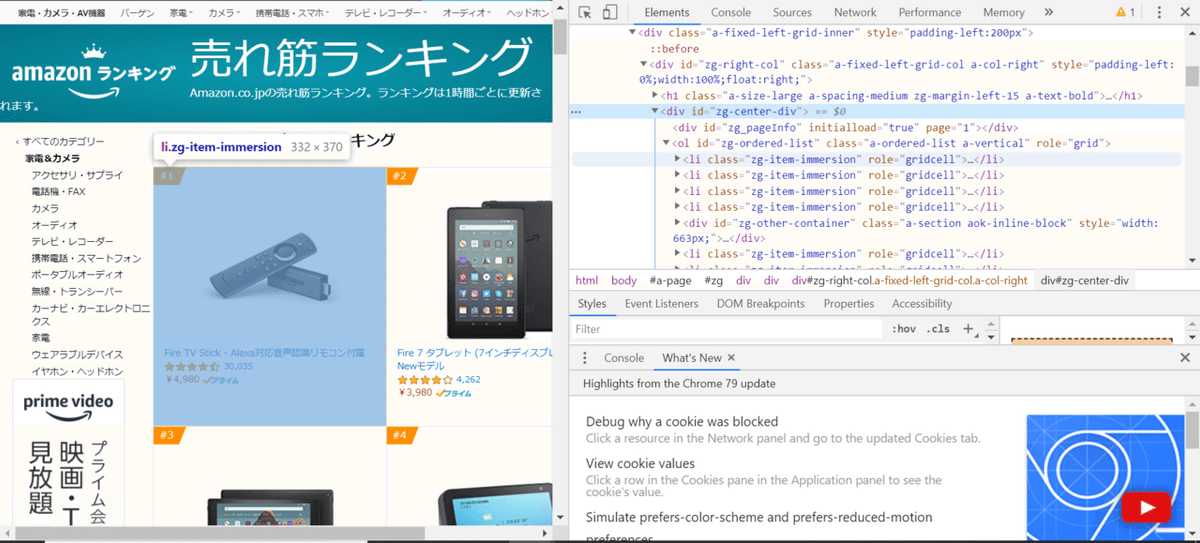
先ほどのdivタグ内に商品のランキングリストが<li class="zg-item-immersion">として羅列してあります。
今回はまずそれらの商品のリストをすべて抜くために、以下のようにfind_all()関数を用います。簡単に説明すると、この関数はカッコ内に書いたものに該当する部分をすべて抽出してくれる関数です。カッコの中はタグ・クラスの順で書いていきます。
main_item_indexs = soup.find_all("li", "zg-item-immersion")これでmain_item_indexsには各商品の情報がhtmlの状態で入ります。<li class="zg-item-immersion">の中身はこんな感じになっています。

この部分の取得する箇所を変えることで好きな情報を取得できます。ここからちょっとだけ難しいですが頑張りましょう。
find_all()関数での抽出後の更なる情報抽出には、基本的に以下のようにfor文を用いて1つ1つに対してfind()関数を適用します。もっといい方法知っている方はぜひともアドバイスください。
find()関数はカッコ内に書いたものに該当する中で一番最初に見つけた情報を抽出してくれます。
for main_item_index in main_item_indexs:
rank = main_item_index.find("span", "zg-badge-text").get_text()
title = main_item_index.find("div", "p13n-sc-truncate").get_text().lstrip()
item_urls = "https://www.amazon.co.jp" + main_item_index.find("a").attrs['href']
find()関数で抽出したものには、以下のようにタグの情報などがすべて含まれているので.get_text()関数を組み合わせて文章部分のみ(以下で言うとFire ...の部分)に成形します。
# find()関数は以下のような形で抽出する
<div class="p13n-sc-truncated" aria-hidden="true" data-rows="2" data-truncate-by-character="1">Fire TV Stick - Alexa対応音声認識リモコン付属</div>
# .get_text()関数を用いるとこうなる
Fire TV Stick - Alexa対応音声認識リモコン付属title=...の行にある.lstrip()関数は先頭の空白を削除する関数です。今回抽出したタイトルの先頭に空白があって不自然だったので使いました。なくてもOKです。
item_urls=...の行にある.attrs['href']は、find()関数で抽出した情報の中のhref部分を抽出するときに使うものです。今回は<a>タグの中のhref部分にURLがあるので用いています。いろいろ変えてみて何がとれるか試してみてください。
ひとまず抽出しそうなところを画像を用いて紹介します。
<span class="zg-badge-text">内にはランキングが載っています。

<a class="a-link-normal" ... >内には商品リンクのURLが載っています。

<div class="p13n-sc-turncated" ... >内には商品のタイトルが載っています。

こちらの<a class="a-link-normal" ... >内にはレビュー(星いくつなのか)が載っています。

<a class="a-size-small" ... >内にはレビューの件数が載っています。

こちらの<a class="a-link-normal" ... >内には商品の値段が載っています。

今回のコードではランキングとタイトルとURLを抽出していますが、これを踏まえて以下のコードの部分を書き換えたり、新たに追加すれば好きな情報を抽出できます。
rank = main_item_index.find("span", "zg-badge-text").get_text()
title = main_item_index.find("div", "p13n-sc-truncate").get_text().lstrip()
item_urls = "https://www.amazon.co.jp" +main_item_index.find("a").attrs['href']
補足ですが、item_urls=...の行に関して、本来はしっかりとクラス等を指定しないといけないところを今回のコードでは簡単化しています。find()関数は条件に一致する一番上ものから(今回は<a>タグ)抽出するためにまぐれで取得できてしまったので横着しちゃいました。いけない子ですね。
また、ここでは行っていませんが、find_all()関数で得た結果に対してfor文等を使わずに直接find()関数やfind_all()関数を適用しようとすると以下のようなエラーが出ます。はじめての人はやりがちかもしれません(僕はやりました)。
AttributeError: ResultSet object has no attribute 'find_all'. You're probably treating a list of items like a single item. Did you call find_all() when you meant to call find()?
複数のdivタグの中に複数のtableタグがあってその中の情報をすべてほしい!ってなった時に
1.divタグをfind_all()関数で取得する
2.その結果に直接find_all()関数を適用する
3.エラー吐かれる
みたいな流れでやったりします。僕はスクレイピングを久しぶりにやるとたまにこのミスします。つらい。
■コード紹介➂ extract_category()関数
def extract_category():
url = "https://www.amazon.co.jp/gp/bestsellers/"
html = request.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
main_category_indexs = soup.find_all("div", "zg_homeWidget")
amazon_category_list = []
for main_category_index in main_category_indexs:
category_name = main_category_index.find("h3").get_text()
category_url = main_category_index.find("a").attrs['href']
amazon_category_list.append([category_name, category_url])
return amazon_category_listextract_category()関数はaccess_amazon()関数の一番最初に呼び出されてamazonに存在するカテゴリー名と対応するURLを返す関数です。抽出の要領はaccess_amazon()関数と同じです。access_amazon()関数の説明を受けて、「完全に理解した」状態の皆さんならきっと一瞬で把握できるでしょう。
■コード紹介④ save_csv()関数
def save_csv(category_name, amazon_ranking_list):
locale.setlocale(locale.LC_CTYPE, "Japanese_Japan.932")
date_now = datetime.datetime.now()
name = date_now.strftime('%Y年%m月%d日 %H時%M分 ') + category_name + ".csv"
with open(name, "w", encoding='shift_jis', errors="ignore") as f:
writer = csv.writer(f, lineterminator="\n")
writer.writerows(amazon_ranking_list)save_csv()関数は、抽出した情報をCSV形式で保存するための関数です。
引数は、
・category_name:カテゴリー名
・amazon_ranking_list:抽出した情報
となっています。
この関数自体は非常に単純で、抽出した日時を取得してカテゴリー名と合わせたファイル名を作り、抽出した情報をCSV形式で保存するといった流れです。
setlocale()関数やnow()関数などを使うためにlocale、datetimeをインポートしてください。
コードのnameが以下の画像のファイル名になっています。

with以下は情報をCSV形式で保存するところです。ここでerrors="ignore"という引数がありますが、これは🄬等SHIFT-JISで保存する際に対応していない文字があった場合に無視するためです。「SHIFT-JISってなんやねん」な人は、「文字コード shift-jis」とかでググってみてください。errors="ignore"を書かないと以下のようなエラーが出ます。
UnicodeEncodeError: 'shift_jis' codec can't encode character '\xae' in position 112: illegal multibyte sequence
\xaeが🄬のことです。というか🄬ってスマホによってはそもそも表示されません。Rを○で囲んだものです。
ちなみに形式をUTF-8にすると、保存したCSVファイルをExcelで表示したときに文字化けします(なんでSHIFT-JIS形式やねん)。SHIFT-JIS、なくなってほしいですね(個人の見解です)。
■まとめ
いかがだったでしょうか。長かったですね。「思ったよりも簡単にかけてるな」と感じた方も多いかと思います。
ぜひ、このコードを拡張してほかの情報をスクレイピングしてみたり、自分の好きなサイト等に適用してみたりしてみてください。
何か疑問等ありましたら是非是非コメントお待ちしております。twitterをフォローしていただければDMでも時間があるときにお答えします。
気に入っていただけたら是非スキ・フォロー・サポートなどをしていただけると中の人のモチベーションになります。
よろしければサポートをしていただけると中の人のやる気アップにつながります!サポートは中の人の餌付けや更なる自動化ツール開発費に充てていきます。