Kaggle チュートリアル Titanicその① まだ地味な作業。データの要約の前のデータの俯瞰。

train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
train_data.head()
train.csvを前回は読み込んだところまで。実質なんもしてない。
さてさて、じゃあデータをみていくこととする。先に断りを入れるけど、はっきり言って記事としてはつまらない。
さっさとdescribeしてpair plotして、相関行列のヒートマップ、オートスケーリング、モデル選んでハイパーパラメータチューニング、といきたい。
自分だって他人の記事を読むなら、そういうサクサクしたのを読みたい。
でも、実際のところ、前処理をどれだけ丁寧にするか、前処理に行く前のデータをしっかり俯瞰するかが大事なわけで。
そんなわけで、クソつまらない記事、というか作業記録のようなのを書く。
さて、とりあえずテストデータは忘れて、トレーニングデータのほうだけ眺めてみる。
教科書だと分割してテストデータを取っておいて、モデルの評価で終わりだけど、現実だとそれで終わりじゃなく、真のテストデータは運用後なわけだし。
train_data.info()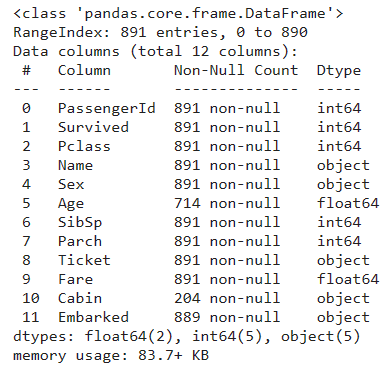
891行の12列あるそうな。
shapeとかcolumnsでそれぞれ取ってきてもいいんだけど、infoで全部出してあげたほうが簡単だし楽。Countの数が違うってことは、欠損値があるってことっぽいな。
重複と欠損値を数えてみる。まずは重複。
train_data.duplicated().sum()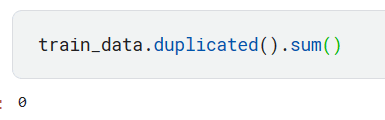
とりあえず重複はなさそう。PassengerIdだけ違ってあとは全部同じっていう重複もあったら怖いのでそれも確認してみる。
train_data[train_data.columns[train_data.columns !="PassengerId"]].duplicated().sum()
うむうむ。次は欠損の確認。
train_data.isnull().sum()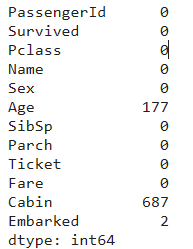
行数=PassengerIDのnon nullの数ってことだから、891名のデータがあるってことだな。AgeとCabinに欠損値が多いっぽいな。
あとで、テストデータでも欠損値をチェックすることにしよう。
AgeとCabin、これを特徴量として使っちゃうと、テストデータにこの列の欠損値があったら予測できないってことになってしまう。
それぞれの列ごと、いくつの水準があんだろうか(SexだったらmaleとFemaleの二つという感じで)?あんまり多いとグルーピングしないといけないし。
uniqueで数えてもいいんだけど、uniqueな名前なんて滅茶苦茶あるとやらなくてもわかるので、先に列ごとの重複数でみてやる。
for _ in train_data.columns:
print(_+":",train_data[_].duplicated().sum(),train_data[_].duplicated().sum()/len(train_data)*100,"%","\n")
意外だけど、名前に重複いないのね。同姓同名なし。チケットに重複があるってどういうこったい?1人1チケットではないということか?代表者に発行されるという感じ?
チケット番号は欠損値はなさそうだし、注意深くみていく必要がある。
ここまでみて、公式のDataset Descriptionを振り返る。
PassengerId – 乗客識別ユニークID
Survived – 生存フラグ(0=死亡、1=生存)
Pclass – チケットクラス(1= 1st, 2 = 2nd, 3 = 3rd)
Name – 乗客の名前
Sex – 性別(male=男性、female=女性)
Age – 年齢
SibSp – タイタニックに同乗している兄弟/配偶者の数
Parch – タイタニックに同乗している親/子供の数
Ticket – チケット番号
Fare – 料金
Cabin – 客室番号
Embarked – 出港地(C = Cherbourg, Q = Queenstown, S = Southampton)
なぜCabinにこんなに欠損値が多いのかよくわからない。
客室と結びつけないままチケットを売るとは思えないし、チケットの番号から部屋番号は自動でわかるとかあるんだろうか。
チケット番号が同じだったら、同じ部屋番号なのだろうかと思ったが、そうでもなさそうだ。とりあえず、チケットをキーにして並べて、関係性を探ってみる。
train_data.sort_values(by="Ticket")[0:15]
数行並べただけだが、チケットが同じだと、料金は同じらしい。
客室番号は違う。頭のアルファベット同じで連番の隣部屋なのかと思ったが、チケット110465でも、Porter, Mr. Walter ChamberlainはC110でClifford, Mr. George QuincyはA14だったりする。
簡単なルールではなさそうな気配。
チケット番号のUniqueを取得して、文字列を眺めてみる。
train_data["Ticket"].unique()
ふむ、さっぱりわからない。
数字4桁のチケット番号もあれば、数字6桁もある。数字が始まる前に、頭にPCとかW./C.とかC.A.とかついているのもある。C.A.とCAが入力した際の表記ゆれなのか、同じなのかわからない。
数字がなくLINEというものさえある。
いくら巨大客船といえど、何十10万人なんて乗るわけないんだから、航海のたびゼロに戻る仕様とは考えられないし。
思いついたのは、代理店(発券所)ごとに発券して、自由なルールで発行。あとで船にチケット番号のリストが送られるという理屈なのじゃなかろうか。
もし、発券所ごと自由なルールでチケット番号が附番されてるとすると、法則性を探すのは困難だ。
チケット番号から客室の欠損を埋める目論見は後回しに、とりあえず同じチケット番号がどのくらいいるのかヒストグラムに。最大で7,最小で1ということは事前に調べてbinsを設定して、書いたのがこちら
import matplotlib.pyplot as plt
plt.hist(train_data['Ticket'].value_counts(),bins=range(1,9,1));
チケット番号がグループごとに発行されるとすると、意外と一人客多い印象。豪華客船なのに。
部屋番号で同じことやったらどうなるんだろう?
plt.hist(train_data['Cabin'].value_counts(),bins=range(1,6,1));
一人部屋の客が100くらい、二人部屋客が40弱、三人、四人同じ部屋の客ももある少数だけどあるのが伺える。欠損値が多いので鵜のみにはできないけれど、3人4人という部屋は少数というのは信じてよさそうな感じがする。
本当に一人客は多いのか、SibSpとParchから探ってみる。
SibSp が同乗している兄弟/配偶者の数で、Parchが同乗している親/子供の数で、これらの列は欠損値がないから、あてになるはず。
train_data[['Parch','SibSp']].value_counts()
ふむふむ、本当に同乗者がいない乗客が537名もいなそうに見える。
チケットの紐づけてみるとどうなるか。頭だけだしてみる。
pd.DataFrame(train_data[['SibSp','Parch','Ticket']].value_counts()).sort_values(by="SibSp",ascending=False).head(20)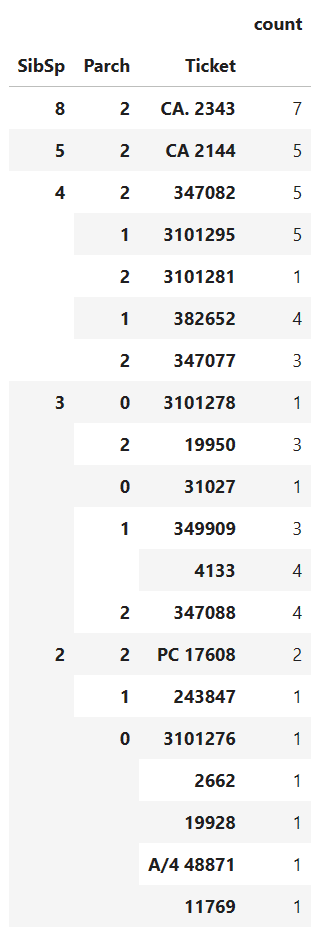
なんか思ったようにはならない。
同乗者はみな同じチケット番号とすると、SibSpとParchの数よりValue_countsが小さいはずがない。しかし、C.A.2343のSibSpは8でParchは2、それでいてValue_countsは7、同乗者でもチケット番号は別だったりすることもあるようだ。
チケット、客室番号、同乗者の謎はすぐには解けなさそうだ。
とりあえず今日はここまで。
次回、可視化に進む。