
ベイズ推定と最尤法

こんにちは。
今日は多項式回帰を通じてベイズ推定と最尤法について話していきたいと思います。
まず準備したダミーデータはこちら

青い点が今回観測された(とする)データです。
本来はオレンジの曲線上に乗るはずのデータが、なんらかのノイズによりずれてしまっていると考えます(実際は意図的にずらしました)。
さて、多項式回帰を使って、観測された青い点からオレンジの曲線=真の分布を予測しようという試みます。
多項式回帰とは
y=w0+w1x+w2x2+...+wnxn�=�0+�1�+�2�2+...+����
の形で真の分布を予測するものです。
本来はモデルエビデンスの評価によって何次式になるか予想するのですが、今回は10次式で固定します。
あとは観測されたデータからw0〜w10�0〜�10を学習するだけ。
まずは最尤法を試してみましょう。
観測値と予測値のずれが最小になるようにします。
解析的に解けるのですが、途中計算は割愛します。
w=(XTX)−1XTy�=(���)−1���
Xとyが観測データです。この数式に観測データをあてはめてグラフを描いたのがこちら

大まかには形を捉えていますが、細かいところでグニャグニャと曲がりノイズまで学習してしまっています。
その代わり全ての観測データを通っています。
今回はそこまでひどくありませんが、学習データに適合しすぎて真の分布とはかけ離れてしまうことを過学習と言います。
最尤法は過学習を起こしやすいという点があります。
今度はベイズ推定をしてみましょう。
ベイズ推定の場合は最尤法と違い重みwを一つの値として求める(点推定)ではなく、確率分布として求めます。
ベイズの定理により観測データを学習した重みwの事後分布と、重みwを固定した時のyの分布を掛け算すれば、yとwの同時分布になります。
これをwについて積分消去(周辺化)することで、あらゆるwをその確率を考慮して重み付けしたyの分布が求まります。
これが予測分布です。
今回は重みwの分布としてガウス分布を使用したので解析的に予測分布を求めることができ、スチューデントのt分布になります。
その期待値をグラフ化したのがこちら
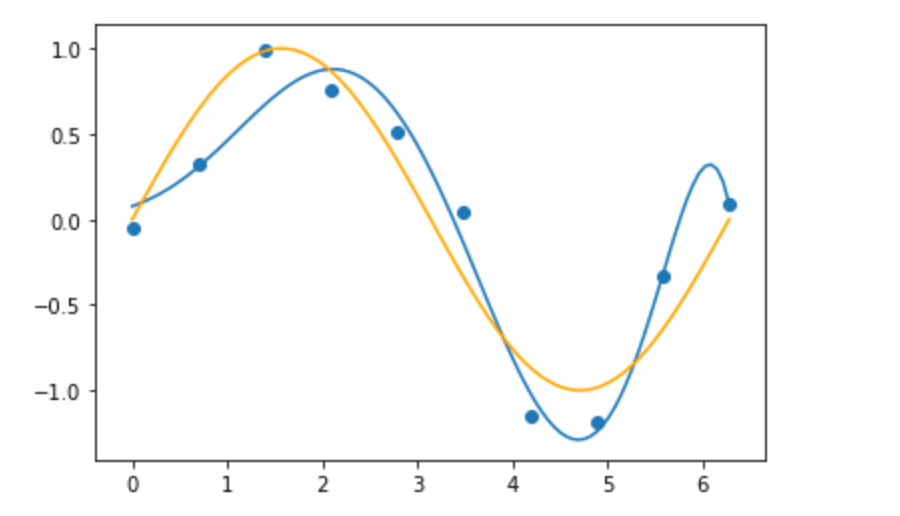
微妙にずれてはいますが、最尤法のようにグニャグニャと曲がってはいません。真の分布をよく捉えていると思います。
ベイズ推定の良さが少しでも伝わったでしょうか?
ベイズ推定の理論についてはかなりはしょった書き方になってしまいましたが、今回伝えたかったのは
最尤法→簡単だが過学習しやすい
です。