
G検定 3-1 7 教師あり学習の基本概念

目標
・教師あり学習には、特徴量と教師データのペアが必要であることを理解する
・教師あり学習における、分析対象に応じた問題の種類を列挙・説明できる
・代表的な教師あり学習モデルの基本概念を理解する
・目的やデータの特性・量に応じて、適切な教師あり学習モデルを選択できる
・ビジネスにおける教師あり学習の応用例を説明できる
キーワード
AdaBoost, アンサンブル学習, カーネル, カーネルトリック, 回帰問題, 決定木, 勾配ブースティング, サポートベクターマシン (SVM), 線形回帰, 自己回帰モデル (AR), 重回帰分析, 多クラス分類, バギング, ブースティング, ブートストラップサンプリング, 分類問題, ベクトル自己回帰モデル (VARモデル), マージン最大化, ランダムフォレスト, ロジスティック回帰
【教師あり学習の基本概念】
教師あり学習のプロセス
データ収集: 学習に使用するデータを収集します。このデータは、入力とそれに対応する正解ラベルを含む必要があります。
モデルの訓練: アルゴリズムは、訓練データを用いてモデルを構築します。この過程では、モデルが入力データから出力を予測するための関数を学習します。
モデルの評価: 訓練が完了した後、テストデータを使用してモデルの性能を評価します。モデルの予測がどれだけ正確であるかを測定するために、損失関数が使用されます。
予測: 訓練されたモデルを使用して、新しいデータに対する予測を行います。
教師あり学習の種類
教師あり学習は主に以下の2つのタスクに分類されます:
分類: データを特定のカテゴリに分類するタスクです。例えば、スパムメールのフィルタリングや画像の認識などが含まれます。一般的な分類アルゴリズムには、ロジスティック回帰、サポートベクターマシン(SVM)、決定木、ランダムフォレストなどがあります。
回帰: 数値的な出力を予測するタスクです。例えば、株価の予測や気温の予測などが該当します。回帰分析には、線形回帰がよく使用されます。
教師あり学習の応用例
教師あり学習は、さまざまな実世界の問題に適用されています。以下はその一部です:
スパムフィルタリング: メールがスパムかどうかを判断するために使用されます。
画像認識: 写真やビデオの中のオブジェクトを識別するために利用されます。
リスク評価: 金融機関が融資のリスクを評価する際に使用されます。
医療診断: 患者のデータを基に病気の診断を行うために活用されます
■代表的な関数
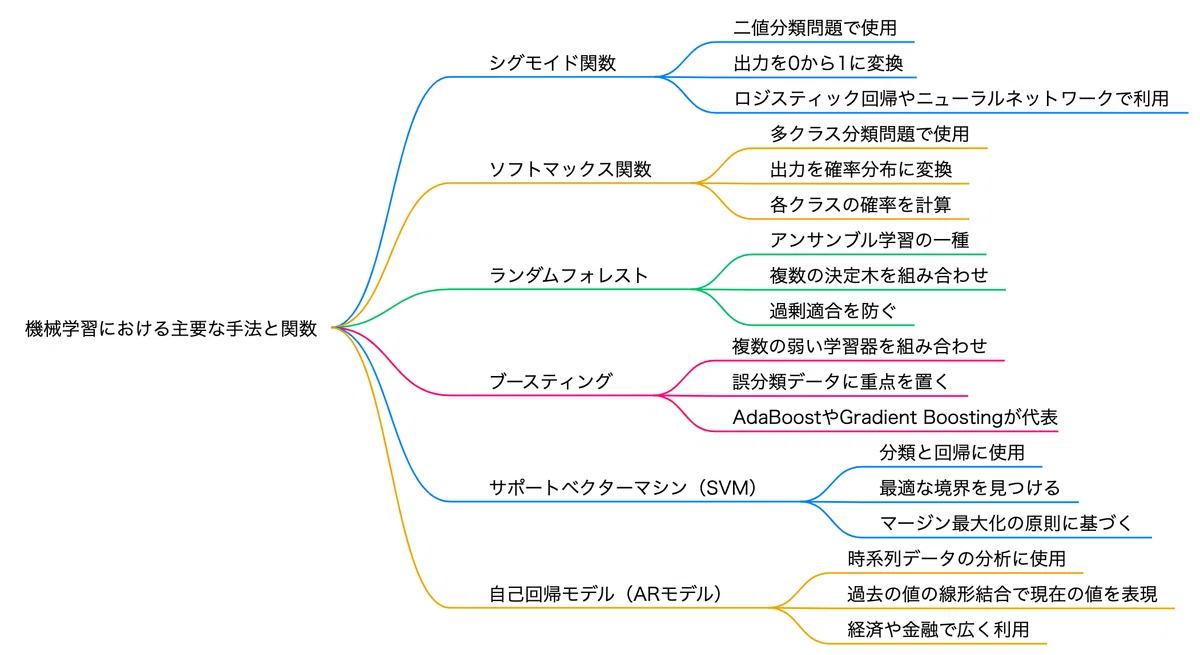
シグモイド関数
主に二値分類問題において使用される活性化関数です。
この関数は、任意の実数を0から1の範囲に変換します。出力は確率として解釈でき、特にロジスティック回帰やニューラルネットワークの出力層でよく利用されます。
ソフトマックス関数
ソフトマックス関数は、多クラス分類問題において使用される関数
ソフトマックス関数は、各クラスの出力が0から1の範囲に収束し、全体の合計が1になるように調整します。これにより、各クラスに属する確率を計算することができます。
■代表的なモデル
ランダムフォレスト (Random Forest)
複数の決定木を組み合わせ
アンサンブル学習の一種
精度が高く汎用性がある
主に分類と回帰の問題に使用
最終的な予測は各木の予測の平均または多数決
ブースストラップサンプリング(ランダムに一部のデータを取り出して学習に使う)
サポートベクターマシン (SVM)
データを高次元空間で分離
カーネルトリックで非線形分類も可能
分類と回帰の問題に使用されるアルゴリズム
自己回帰モデル (AR)
過去の値から将来を予測
株価予測などに使用
時系列データの分析
■モデルの精度向上のアンサンブル学習
バギング
データをランダムに複数抽出して学習
過学習を防ぐ
複数のモデルを並列に作成
ランダムフォレストは、バギングの一例
ブースティング
誤分類データを重点的に学習
AdaBoost、勾配ブースティングなど
複数のモデルを直列に作成
勾配ブースティング(XGBoost(eXtreme Gradient Boosting)というアルゴリズムによって高速に学習計算)
まとめ
シグモイド関数やソフトマックス関数は主に出力層での確率的解釈に使用され、
ランダムフォレストやブースティングはモデルの精度向上に寄与します。
SVMは分類問題に強力な手法を提供し、
自己回帰モデルは時系列データの予測に特化しています。