
G検定 6−4 29. 深層強化学習

シラバス 29. 深層強化学習 についてまとめます
目標
・代表的な強化学習モデルについて理解する
・強化学習が実世界において、どのように活用されているか理解する
キーワード
A3C, Agent57, APE-X, DQN, OpenAI Five, PPO, Rainbow, RLHF, sim2real, アルファスター (AlphaStar), オフライン強化学習, 残差強化学習, 状態表現学習, ダブル DQN, デュエリングネットワーク, ドメインランダマイゼーション, ノイジーネットワーク, 報酬成形, マルチエージェント, 強化学習,連続値制御

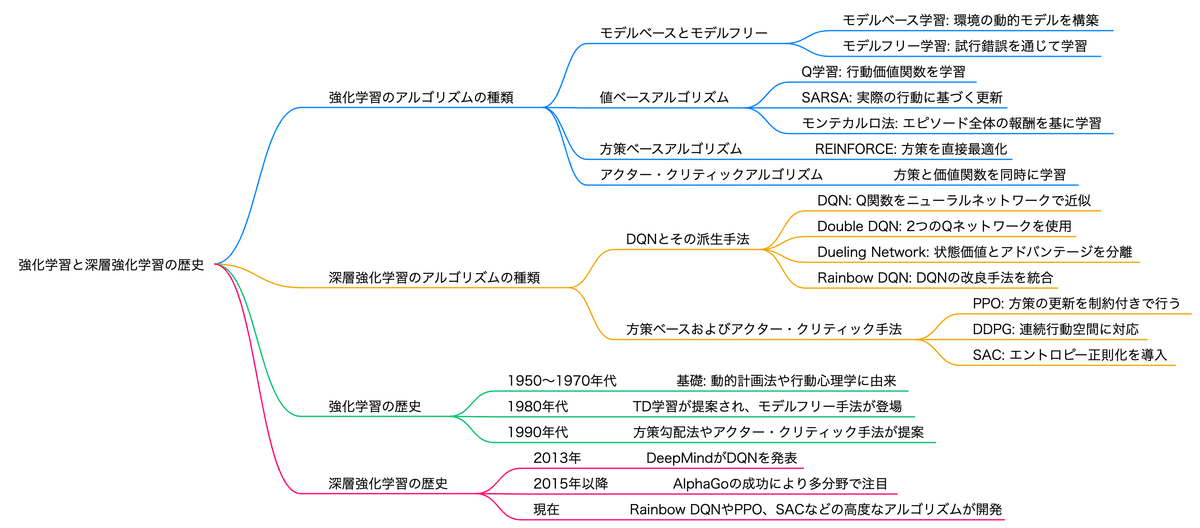
深層強化学習の基本的な手法と発展
深層強化学習(Deep Reinforcement Learning, DRL)は、ディープラーニングと強化学習を組み合わせた手法。
DQN (Deep Q-Network)
最も基本的な手法
Q学習とディープラーニングを組み合わせた手法
深層学習を用いてQ値を推定するアルゴリズムで、ゲームプレイなどに利用される。
DeepMind社が2013年に提案したアルゴリズム
経験再生(探索で得た経験の保存データをランダムに学習に使う)
ターゲットネットワーク(過去のネットワークに教師ような役割を持たせる)
Atariゲームで人間レベルのパフォーマンスを達成したことで注目されました
ダブルDQN (Double DQN)
Q値の過大評価を抑えるために、2つのQネットワークを使用します
優先度付き経験再生
デュエリングネットワーク (Dueling Network)
状態価値とアドバンテージを分離して学習することで、効率的な学習を実現します
Rainbow
DQNの様々な拡張技術を組み合わせたアルゴリズム。
分散型強化学習
学習の収束速度が飛躍的に向上
内発的報酬(intrinsic reward)と呼ばれる報酬の工夫がある
深層強化学習とゲームAI
1.黎明期 (1950年代〜1970年代): ルールベースのAIと初期の成功
この時期は、チェッカーやチェスといったルールが明確なゲームを対象としたAIの研究が始まった時代です。
この時期のAIは主に、事前にプログラムされたルールや評価関数に基づいて動作する「ルールベースAI」でした。
2.探索アルゴリズムの発展と専門家システム (1980年代〜1990年代)
この時期は、ミニマックス法やαβ探索などの探索アルゴリズムが発展し、より複雑なゲームへの対応が進みました。
特に1997年には、Deep Blueが当時の世界チャンピオン、ガルリ・カスパロフに勝利したことは、AIの歴史における大きな転換点となりました。
3.機械学習とモンテカルロ木探索 (2000年代)
モンテカルロ木探索は、ランダムなシミュレーションを繰り返すことで最適な手を探索する手法で、複雑なゲームにも有効であることが示されました。
囲碁はAIにとって長年の課題でしたが、2016年にGoogle DeepMindが開発した「AlphaGo」が、世界トップ棋士の一人であるイ・セドルに勝利し、世界を驚かせました。AlphaGoは、深層学習とモンテカルロ木探索を組み合わせることで、人間の直感を超える能力を実現しました。
4.深層強化学習の台頭と汎用AIへ (2010年代〜現在)
2017年: AlphaGoの後継である「AlphaGo Zero」が登場。人間のデータを一切使用せず、自己対戦のみで学習する手法。囲碁において superhuman level の強さを達成しました。
2018年: OpenAI FiveがDota 2のプロチームに対して競争力のある成果を示す。
2019年: AlphaStarがStarCraft IIでプロレベルのパフォーマンスを達成。
その他のゲームにおけるゲームAI
マルチエージェント強化学習
対戦中に操作する味方のエージェントや相手のエージェントが複数存在し、これらのエージェントの協調的な関係や競争的な関係を考慮して強化学習を行う必要がある。
多数のエージェントが協力してタスクを達成する場面で使う
OpenAI Five: ドタ2(Dota 2)で人間のプレイヤーを打ち負かすために開発されたモデル。
アルファスター (AlphaStar): スタークラフトIIでグランドマスターの称号を持つトップレベルのプレイヤーに勝利。
深層強化学習をロボット制御に応用する際の課題
次元の呪い(curse of dimensionality)
状態や行動の数が指数的に増大するために学習が困難になる
状態表現学習
深層強化学習の文脈では、しばしば「状態」に関する特徴表現学習を指す
効率的な状態の特徴を抽出し、学習を支援する手法
連続値制御
ロボティクスや自動運転での精密な動作制御に使用。
報酬成形 (Reward Shaping)
学習を早めるために報酬を工夫する技術。
サンプル効率が低い割にデータ収集コストが高い
方策の安全性の担保が難しい
ロボット制御に応用する際の課題解決策
事前知識(ドメイン知識)を学習に組み込むための工夫を施すことで効率的な学習を目指す手法が提案されています。
オフラインデータの活用
模倣学習
シュミレータの利用
残差強化学習
環境モデルの学習
1. オフラインデータの活用:
課題: 実ロボットでの試行錯誤は時間とコストがかかり、危険も伴います。
解決策: 事前に収集したオフラインデータ (ロボットの動作データ、センサーデータなど) を活用して学習を行います。
行動クローニング: オフラインデータから直接方策を学習する模倣学習の一種。データの質と量が重要になります。
オフライン強化学習: 事前に収集されたデータを使って学習を行う手法。オフラインデータを用いて、より安全かつ効率的に強化学習を行う手法。データ分布外の行動に対する対策が課題となります。
2. 模倣学習:
課題: 強化学習では適切な報酬関数の設計が難しい場合があります。
解決策: 人間の熟練者の行動データ(デモンストレーション)を模倣することで、報酬関数を明示的に設計することなく、ロボットに複雑なタスクを学習させることができます。
行動クローニング (Behavioral Cloning): 入力データから直接行動を予測するモデルを学習します。
逆強化学習 (Inverse Reinforcement Learning): 熟練者の行動から報酬関数を推定し、その報酬関数を最大化するように方策を学習します。
3. シュミレータの利用:
課題: 実ロボットでの学習は時間とコストがかかり、危険も伴います。
解決策: 現実世界を模倣したシュミレータを用いることで、安全かつ効率的に学習を行うことができます。
ドメインランダマイゼーション (Domain Randomization): シミュレーション環境のパラメータ (摩擦係数、照明条件など) をランダムに変更することで、実環境への汎化能力を高めます。
ドメイン適応 (Domain Adaptation): シミュレーション環境と実環境の差異を埋めるように学習を行うことで、実環境での性能を向上させます。
sim2real: シミュレーションで学習したモデルを実世界に適用する手法。ロボティクスで頻繁に使用。
ドメインランダマイゼーション: シミュレーション環境の多様性を高め、実世界への適用性を向上させる。
4. 残差強化学習:
課題: ロボット制御では、既存のコントローラがある場合があり、深層強化学習モデルはゼロから学習する必要はありません。
解決策: 既存のコントローラをベースラインとして、そのコントローラでは対応できない部分を深層強化学習で学習します。
制御入力への残差を追加: 既存のコントローラの出力に、深層強化学習モデルが出力する修正項を加えることで、より精密な制御を実現します。
制御入力の選択: 深層強化学習モデルが、既存のコントローラから出力された複数の候補の中から、最適な制御入力を選択します。
5. 環境モデルの学習:
課題: 強化学習では、環境との相互作用を通じて多くの試行錯誤が必要となります。
解決策: 環境のダイナミクスを学習する環境モデルを構築することで、試行錯誤の回数を減らし、学習を効率化することができます。
モデルベース強化学習 (Model-Based Reinforcement Learning): 学習した環境モデルを用いて、行動計画を立てたり、方策を学習したりすることができます。
組み合わせ例:
オフラインデータ + 模倣学習 + シュミレータ: 事前に収集したオフラインデータを用いて、シュミレータ上で模倣学習を行うことで、効率的に初期方策を獲得できます。
シュミレータ + 残差強化学習: シュミレータ上で、既存のコントローラをベースラインとした残差強化学習を行うことで、安全かつ効率的にロボットを制御できます。
環境モデル + 強化学習: 環境モデルを用いて将来の状態を予測し、より効率的に強化学習を行うことができます。
これらの手法を組み合わせることで、より効率的かつ安全にロボット制御を行うことが可能となります。
モデルベース強化学習の実社会での活用例
ロボット制御:
モデルベース強化学習は、ロボットの運動計画や制御タスクにおいて非常に有効です。環境の動的モデルを構築することで、試行錯誤を減らして迅速に適応でき、事故や故障のリスクを下げることができます。
自動車の自律走行:
自律走行車の開発においては、モデルベースのアプローチを使用して、シミュレーション環境で安全かつ効率的に運転状況を学習できます。環境のモデル化により、さまざまな運転シナリオや予期せぬ状況を事前にトレーニングできます。
製造業のプロセス最適化:
製造ラインでのプロセス最適化において、環境モデルを構築することで、異なるプロセス条件のシミュレーションが可能となり、効率的なライン運営が実現します。
残差強化学習の実社会での活用例
既存システムの改良:
既に稼働中の産業用ロボットや自律システムにおいて、既存のポリシーを保持しつつ性能を向上させるために、残差強化学習が用いられます。これにより、大規模なシステム変更をすることなく、少しずつ性能を改善できます。
物流のルート最適化:
物流や配達システムにおいて、従来のルートやスケジュールに対して微調整を行い、効率やコストを改善するために使われます。これにより、サービスを中断することなく改善を行うことが可能です。
金融のポートフォリオ最適化:
既存の投資戦略に小さな変更を加えてリターンを最適化する際に、残差強化学習が活用されます。既存の戦略を大幅に変更するリスクを避けつつ、より良いポートフォリオパフォーマンスを狙います。
その他の関連トピック
PPO (Proximal Policy Optimization): 政策ベースの強化学習アルゴリズムで、収束が速いとされる。
A3C (Asynchronous Advantage Actor-Critic): 複数のエージェントで並列的に学習を行う手法。
Agent57: Atari 2600ゲームで人間を超える性能を示した強化学習エージェント。
APE-X: 分散環境で効率的にDQNを学ぶ手法。
ノイジーネットワーク (Noisy Networks): 探索を促進するためにネットワークにノイズを加える手法。
RLHF (Reinforcement Learning from Human Feedback): 人間によるフィードバックを用いてエージェントの性能を向上させる手法。