
G検定 6−7 32. マルチモーダル

シラバス 32. マルチモーダル についてまとめていきます
目標
・マルチモーダルタスクの種類とその概要について理解する
・代表的なマルチモーダルモデルについて理解する
・マルチモーダルモデルが実世界において、どのように活用されているか理解する
キーワード
CLIP, DALL-E, Flamingo, Image Captioning, Text-To-Image, Visual Question
Answering, Unified-IO, zero-shot, 基盤モデル, マルチタスク学習
マルチモーダルタスクの種類とその概要について理解する
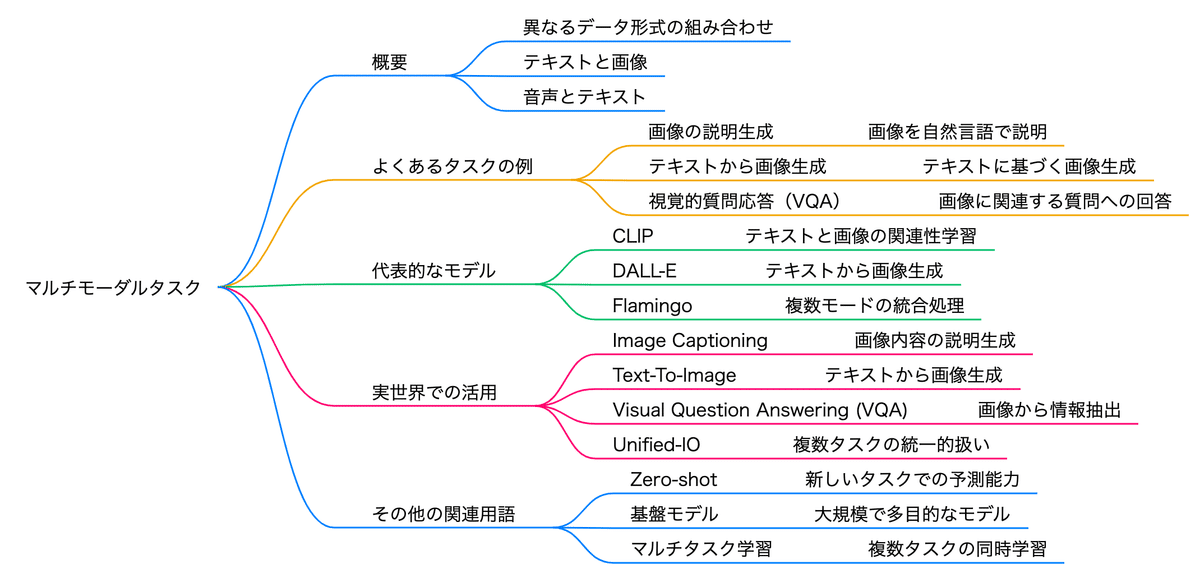
マルチモーダルタスク
複数の異なるデータ形式(モード)を組み合わせて処理するタスク。例えば、テキストと画像を組み合わせたもの。
よくある例として、画像の説明を生成する、テキストから画像を生成する、画像に関連する質問に答える、などがある。
代表的なマルチモーダルモデルについて理解する
CLIP (Contrastive Language–Image Pretraining)
テキストと画像の関連性を学習するモデル。入力された画像とテキストを結びつけて理解することが可能。
Zero-shot学習(学習していない新しいタスクにも説明を与える)
DALL-E
CLIPとDiffusionModelに使用
テキストから画像を生成するモデル。与えられたテキストプロンプトに基づいて創造的な画像を生成する。
オープンAIによって開発
Text-to-Imageを使用
Flamingo
複数のモードを統合して処理を行うモデル。特に視覚とテキストの情報を統合することに優れている。
ディープマインド・テクノロジー社によって開発
画像や動画を入力としたImage-Captioningタスクを解く
Unified-IO
複数の異なるタスクやモーダルを統一的に扱うフレームワーク。汎用的なAIシステムを目指す。
姿勢推定や物体検出、質疑応答、Text-to-Image、Visual Question Answeringなどのさまざまなタスクを解くことができるネットワーク
マルチモーダルモデルが実世界において、どのように活用されているか理解する
Image Captioning
画像を入力として、その内容を説明する文章を生成するタスク。画像認識と自然言語処理の統合の良い例。
Text-To-Image
テキストから対応する画像を生成するタスク。クリエイティブコンテンツの生成で利用される。
DALL-EとUnified-IOのネットワークで使われる
Visual Question Answering (VQA)
画像に関連する質問に答えるタスク。
画像と画像に関する質問文を入力として受け取り、受け取った画像と質問の内容を元に回答を生成する。
その他関連用語
基盤モデル (Foundation Models)
さまざまなタスクに転用可能な、大規模で多目的なモデルのこと。事前に大量のデータでトレーニングされる。
マルチタスク学習 (Multi-task Learning)
複数の異なるタスクを同時に学習する手法。各タスクが持つ共通の情報を活かして効率的に学習が行える。