
G検定 4-6 12 活性化関数(勾配消失問題解決する)

シラバス 12. 活性化関数 をまとめていきます
目標
・代表的な活性化関数の定義・使い分け
・注意点について、それぞれ説明できる
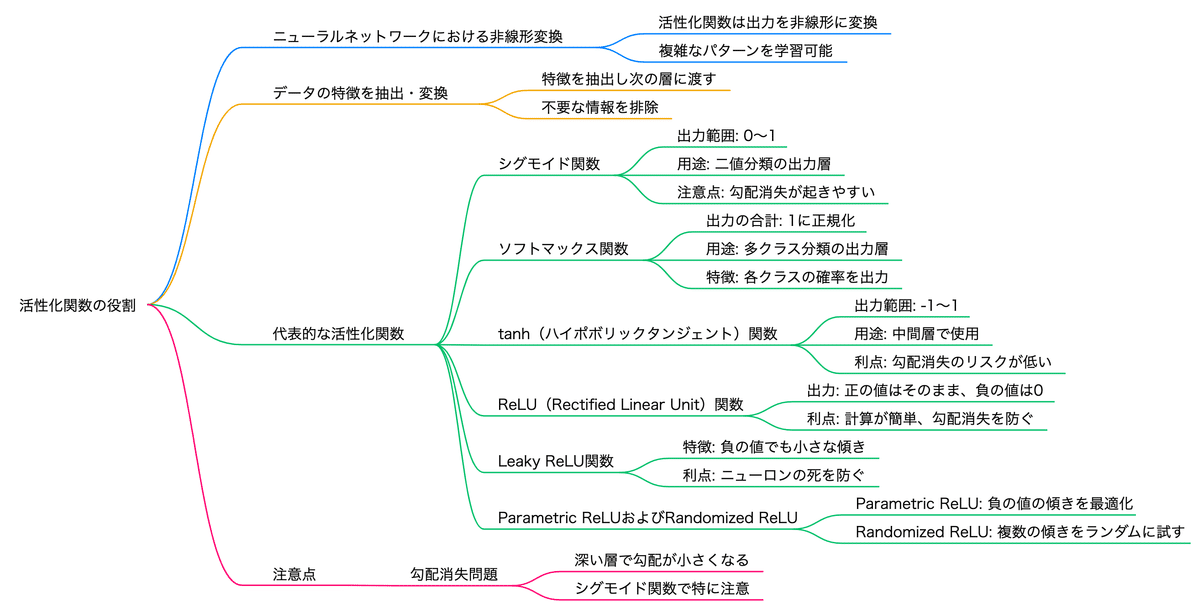
・ディープラーニングにおける活性化関数の役割を説明できる
キーワード
Leaky ReLU 関数, ReLU 関数, tanh 関数, シグモイド関数, ソフトマックス関数, 勾配消失問題
【活性化関数の基本概念】
■シグモイド関数と勾配消失問題
シグモイド関数 シグモイド関数の微分

シグモイド関数の微分は最大値が0.25にしかなりません。隠れ層を遡るごとに(活性化関数の微分が掛け合わさって)伝播していく誤差はどんどん小さくなっていってしまいます。多くの隠れ層があると、誤差がほとんど0になってしまい、勾配消失問題が発生します。
■勾配消失問題を解決する活性化関数
tanh関数(ハイパボリックタンジェント関数)
シグモイド関数の改良版で、出力が-1から1の範囲に収束します。シグモイドよりも勾配消失の影響を受けにくいですが、依然として問題があります。
シグモイド関数の改良版、線形変換したもの
出力が-1〜1の範囲
原点中心の出力
特に中間層の活性化関数としてよく使用されます
ReLU(Rectified Linear Unit)関数
入力が0以上の場合はそのまま出力し、0未満の場合は0を出力します。計算が簡単で、勾配消失が起こりにくいため、最も一般的に使用される活性化関数です。
tanh関数より勾配消失問題に対処
深層学習モデルの隠れ層で広く使用されている
特に大規模なネットワークでの学習速度を向上
正の値はそのまま出力
計算が簡単
勾配消失を防ぐ
中間層で一般的
負の値は0に変換(学習がうまくいかない場合もある)
Leaky ReLU関数
ReLUの改良版(必ずしもLeaky ReLUの方が優れているわけではない)
負の値でも小さな傾きを持つ
Parametric ReLU(負の値の傾きを学習によって最適化)
Randomized ReLU(複数の傾きをランダムに試す)
活性化関数の選択
活性化関数の選択は、ニューラルネットワークの性能に大きな影響を与えます。モデルの目的やデータの特性に応じて適切な活性化関数を選ぶことが重要です。例えば、隠れ層にはReLUがよく使われますが、出力層ではタスクに応じてソフトマックスやシグモイドが選ばれることがあります。
■代表的な活性化関数
隠れ層:tanh,ReLU, Leaky ReLU
二値分類の出力層:シグモイド関数
多クラス分類の出力層:ソフトマックス関数
回帰問題の出力層:線形関数(活性化関数なし)