
【AWS】 ElastiCacheの解説

ElastiCache
フルマネージドのインメモリデータストアおよびキャッシュサービス。主にデータベースのパフォーマンスを向上させるために使用され、高速なデータアクセスと低レイテンシを提供する。
インメモリデータストア(In-Memory Data Store)は、データをディスクではなくメモリ(RAM)に格納するデータベースの一種。
インメモリデータストアは、キャッシング、リアルタイム分析、セッションストレージなど、高速なデータ処理が求められるアプリケーションに広く使用されている。
ElastiCacheは、RedisとMemcachedの2つの人気のあるキャッシュエンジンをサポートしている。
RedisやMemcachedなどのツールを使用することで、キャッシング、リアルタイム分析、セッションストレージ、キューとメッセージングなど、多様なアプリケーションにおいて性能向上が図れる。Amazon ElastiCacheのようなマネージドサービスを利用することで、インフラストラクチャ管理の負担を軽減し、スケーラビリティと高可用性を確保できる。
Redis
Redisは、オープンソースのインメモリデータストアで、高速なキー・バリュー型ストアとして広く利用されている。
単純なキー・バリューの保存だけでなく、リスト、セット、ソートセット、ハッシュといった高度なデータ構造もサポートしている。また、Pub/Sub(パブリッシュ/サブスクライブ)機能、トランザクション、Luaスクリプトの実行など、多くの便利な機能を提供している。
データをメモリに格納するだけでなく、定期的にディスクに保存することで持続性を確保できる。
利用シーン
複雑なデータ構造を扱う場合:
Redisはリスト、セット、ソートセット、ハッシュなどの複雑なデータ構造をサポートしているため、これらを活用するアプリケーションに最適です。
例:ランキングシステム(ソートセット)、リアルタイムのチャットアプリ(リスト)、セッションデータの管理(ハッシュ)。
永続性が必要な場合:
Redisはデータのスナップショットを定期的にディスクに保存したり、AOF(Append-Only File)を利用してデータを永続化することができます。
例:トランザクションログ、イベントストリーミングの保存。
高可用性とフェイルオーバーが必要な場合:
Redisはレプリケーションをサポートし、自動フェイルオーバー機能を提供します。高可用性とデータの冗長性を確保したい場合に適しています。
例:ミッションクリティカルなアプリケーション、分散システム。
Pub/Sub(パブリッシュ/サブスクライブ)モデルを使用する場合:
RedisはPub/Sub機能を提供しており、メッセージングシステムやリアルタイム通知に使用できます。
例:リアルタイムチャットシステム、ライブデータフィード。
Memcached
Memcachedは、高パフォーマンスな分散メモリキャッシュシステムで、主に一時的なデータのキャッシュとして利用される。シンプルなキー・バリュー型ストアであり、Webアプリケーションのスケーラビリティとパフォーマンスを向上させるために設計されている。
利用シーン
シンプルなキャッシュが必要な場合:
Memcachedはシンプルなキー・バリュー型ストアであり、キャッシュとしての使用に特化しています。複雑なデータ構造や追加機能を必要としない場合に最適です。
例:Webページのキャッシュ、データベースクエリの結果キャッシュ。
メモリ効率が重要な場合:
Memcachedはメモリ効率が高く、大量のキャッシュデータを扱う際に適しています。オーバーヘッドが少ない設計です。
例:大規模なWebアプリケーションのスケーリング。
スケールアウトが必要な場合:
Memcachedは分散キャッシュシステムとして設計されており、ノードの追加によって簡単にスケールアウトできます。水平スケーリングが求められるシナリオに適しています。
例:負荷分散されたWebサーバークラスタ。
簡単な導入と管理が求められる場合:
Memcachedはシンプルで設定が簡単なため、迅速な導入が可能です。キャッシュの設定と運用がシンプルなシナリオに向いています。
例:スタートアップや小規模プロジェクトのキャッシングソリューション。
サービス連携
ElastiCacheと各種サービスが連携する時の流れを記す。
実行のきっかけは主にウェブリクエストやLambda関数のトリガー、アプリケーションコード内の処理フローによって生成される。
ElastiCache自体に直接登録やトリガー設定を行う必要はなく、アプリケーションコード内でElastiCacheへのアクセスを組み込むことで、キャッシュの利用を実現する。
前提
依存関係のインストール:
pip install redis や pip install python-memcached を実行して依存関係をインストール。
ElastiCacheの接続設定:
ElastiCacheクラスターのエンドポイントを取得し、アプリケーション内でRedisクライアントを設定。
キャッシュロジックの実装:
データベースクエリの前にElastiCacheをチェックし、キャッシュミスの場合のみデータベースにクエリを実行して結果をキャッシュに保存するロジックを追加。
アプリケーションロジックの統合:
キャッシュロジックをアプリケーションのビジネスロジックに統合。
テストとデプロイ:
コードをテストし、ElastiCacheが正しく使用されていることを確認し、アプリケーションをデプロイ。
Amazon RDSとの連携
ウェブアプリケーションがデータベースクエリを頻繁に実行し、RDS(Relational Database Service)への負荷が高くなる場合、ElastiCacheをキャッシュとして利用してデータベースの負荷を軽減する。
### 使用例コード(Python)
import redis
import mysql.connector
# ElastiCache Redisクライアントの設定
redis_client = redis.StrictRedis(host='my-redis-endpoint', port=6379, decode_responses=True)
# RDS MySQLクライアントの設定
db_connection = mysql.connector.connect(
host='my-rds-endpoint',
user='username',
password='password',
database='mydatabase'
)
db_cursor = db_connection.cursor()
def get_user_info(user_id):
cache_key = f"user_info:{user_id}"
# キャッシュからデータを取得
cached_data = redis_client.get(cache_key)
if cached_data:
return cached_data
# キャッシュにデータがない場合、RDSから取得
db_cursor.execute("SELECT * FROM users WHERE user_id = %s", (user_id,))
result = db_cursor.fetchone()
# データをキャッシュに保存
redis_client.set(cache_key, result, ex=3600) # 1時間のTTL
return result
# 使用例
user_info = get_user_info(123)
print(user_info)
データベースクエリの結果キャッシュ:
アプリケーションがRDSにクエリを実行する前に、ElastiCacheにデータが存在するか確認。
キャッシュに存在しない場合、RDSからデータを取得し、結果をElastiCacheにキャッシュ。
次回以降の同じクエリでは、キャッシュからデータを取得。
Amazon EC2との連携
EC2インスタンス上で実行されるアプリケーションが、頻繁にアクセスされるデータをキャッシュするためにElastiCacheを使用する。
### 使用例コード(Python)
import redis
import json
# ElastiCache Redisクライアントの設定
redis_client = redis.StrictRedis(host='my-redis-endpoint', port=6379, decode_responses=True)
def save_session(session_id, session_data):
redis_client.set(session_id, json.dumps(session_data), ex=3600) # 1時間のTTL
def get_session(session_id):
session_data = redis_client.get(session_id)
if session_data:
return json.loads(session_data)
return None
# 使用例
session_id = 'session123'
session_data = {'user_id': 123, 'login_time': '2023-01-01T12:34:56'}
# セッションデータの保存
save_session(session_id, session_data)
# セッションデータの取得
retrieved_session = get_session(session_id)
print(retrieved_session)
セッション管理:
ユーザーセッション情報をElastiCacheに保存し、セッションデータの読み書きを高速化。
AWS Lambdaとの連携
サーバーレスアーキテクチャで、Lambda関数がElastiCacheを利用して一時的なデータをキャッシュし、レスポンス時間を短縮する。
### 使用例コード(Python)
import redis
import json
import boto3
# ElastiCache Redisクライアントの設定
redis_client = redis.StrictRedis(host='my-redis-endpoint', port=6379, decode_responses=True)
def lambda_handler(event, context):
cache_key = 'external_api_data'
# キャッシュからデータを取得
cached_data = redis_client.get(cache_key)
if cached_data:
return json.loads(cached_data)
# キャッシュにデータがない場合、外部APIから取得
api_client = boto3.client('apigateway')
response = api_client.invoke_api(api_id='my-api-id', resource_id='my-resource-id', http_method='GET')
api_data = json.loads(response['body'])
# データをキャッシュに保存
redis_client.set(cache_key, json.dumps(api_data), ex=3600) # 1時間のTTL
return api_data
# 使用例(AWS Lambdaコンソールからトリガー)
イベントデータのキャッシュ:
Lambda関数が外部APIからデータを取得し、結果をElastiCacheにキャッシュ。
次回以降のリクエストではキャッシュからデータを取得し、APIへのリクエストを減らす。
Amazon S3との連携
S3バケットに保存されたデータに頻繁にアクセスする場合、ElastiCacheを使用してデータをキャッシュし、アクセス時間を短縮する。
### 使用例コード(Python)
import redis
import boto3
import json
# ElastiCache Redisクライアントの設定
redis_client = redis.StrictRedis(host='my-redis-endpoint', port=6379, decode_responses=True)
def get_s3_metadata(bucket_name, object_key):
cache_key = f"s3_metadata:{bucket_name}:{object_key}"
# キャッシュからメタデータを取得
cached_metadata = redis_client.get(cache_key)
if cached_metadata:
return json.loads(cached_metadata)
# キャッシュにメタデータがない場合、S3から取得
s3_client = boto3.client('s3')
metadata = s3_client.head_object(Bucket=bucket_name, Key=object_key)
# メタデータをキャッシュに保存
redis_client.set(cache_key, json.dumps(metadata), ex=3600) # 1時間のTTL
return metadata
# 使用例
bucket_name = 'my-bucket'
object_key = 'my-object'
metadata = get_s3_metadata(bucket_name, object_key)
print(metadata)
オブジェクトメタデータのキャッシュ:
S3オブジェクトのメタデータをElastiCacheにキャッシュし、頻繁なメタデータの取得を高速化。
クラスターの作成方法
サーバレスElastiCacheの作成方法
ElastiCacheコンソールにアクセス: AWSマネジメントコンソールにサインインし、ElastiCacheのコンソールに移動する。
RedisまたはMemcachedの選択: 左側のナビゲーションペインから「Redis caches」または「Memcached caches」を選択。
サーバレスオプションの選択: 「Create Redis cache」または「Create Memcached cache」をクリックし、表示されるオプションから「Serverless」を選択。
キャッシュの設定:
Name: キャッシュの名前を入力。
Description: 任意でキャッシュの説明を入力。
Engine: 使用するキャッシュエンジン(RedisまたはMemcached)を選択。
デフォルト設定の使用: デフォルト設定を使用してキャッシュを作成。これには、デフォルトのVPC、アベイラビリティゾーン、サービス所有の暗号化キー、およびセキュリティグループが含まれる。必要に応じてカスタマイズも可能。
キャッシュの作成: 設定内容を確認し、「Create」をクリックしてキャッシュを作成。作成が完了すると、キャッシュエンドポイントが表示されるので、このエンドポイントをアプリケーションで使用する。



CLIを使用した作成手順
サーバレスキャッシュを作成する。
aws elasticache create-serverless-cache \
--serverless-cache-name my-serverless-cache \
--description "My Serverless Cache" \
--engine redisエンドポイントを取得する。
aws elasticache describe-serverless-caches \キャッシュにアクセスするためのIAMロールを作成し、適切なポリシーをアタッチする。
aws iam create-role \
--role-name "my-elasticache-role" \
--assume-role-policy-document file://trust-policy.json
aws iam create-policy \
--policy-name "my-elasticache-policy" \
--policy-document file://policy.json
aws iam attach-role-policy \
--role-name "my-elasticache-role" \
--policy-arn "arn:aws:iam::your-account-id:policy/my-elasticache-policy"独自のクラスターを使用
ElastiCacheコンソールにアクセス: AWSマネジメントコンソールにサインインし、ElastiCacheのコンソールに移動する。
RedisまたはMemcachedの選択: 左側のナビゲーションペインから「Redis caches」または「Memcached caches」を選択。
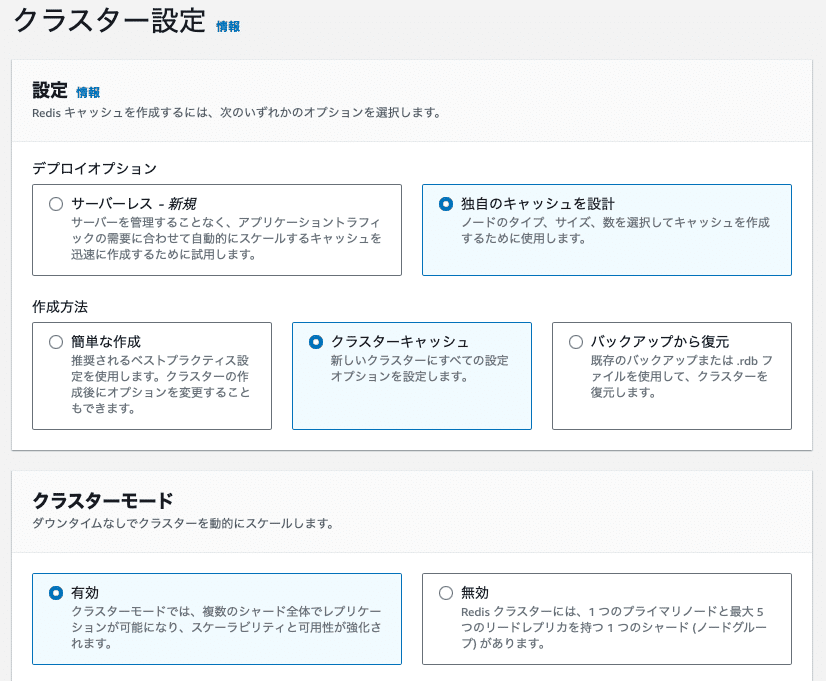
オプションの選択: 「Create Redis cache」または「Create Memcached cache」をクリックし、表示されるオプションから「独自のキャッシュ」を選択。
ネットワーク設定:
Network type: IPバージョンを選択。
Subnet groups: サブネットグループを選択。クラスターの設定:
Cluster mode: 「Disabled」を選択。
Cluster info: クラスター名を入力。
Description: 任意で説明を入力。
Engine version: 利用可能なバージョンを選択。
Port: デフォルトの6379を使用するか、必要に応じて変更。
Parameter group: パラメーターグループを選択または新規作成。
Node type: インスタンスタイプを選択。
Number of replicas: レプリカの数を設定。





よろしければサポートお願いします!よりいい情報を発信します。