
【無料公開】AIモデル「DeepSeek」の真相とテック業界への影響 Daily Memo - 1/28/2025

今日のDaily Memoでは中国のAIモデルDeepSeekについての話です。こちらはOff Topic Clubメンバーシップ向けに平日に投稿している「Daily Memo」ではありますが、少し長文で画像やSNS投稿を表示する必要があったため記事として書かせていただいてます。気になる方は是非Off Topic Clubに参加してみてください!
はじめに
中国のAIスタートアップ「DeepSeek」が去年開発したAIモデル「DeepSeek-V3」はAI・テック業界をビックリさせたが、先週リリースしたモデル「DeepSeek-R1」はさらに大きな衝撃を与えた。ただ、このモデルの凄さは元々のV3から生まれてきているので、今回のDaily MemoではV3の凄さについて話し、それがどのように今後AI業界を影響させるのか自分の考えをまとめてみました。DeepSeek-V3はOpenAIの「GPT-4o」やAnthropicの「Claude 3.5 Sonnet」と同等の性能を持ちながら、はるかに少ない資金、チップ、エネルギーで実現されています。DeepSeekは、ヘッジファンド「High-Flyer」から生まれたオープンソースプロジェクトであり、最近では米国のApp Storeで1位を獲得するなど、その影響力を急速に拡大しています。今回のDaily MemoではDeepSeekが起こしたイノベーション、シリコンバレー内で話題になっているトレーニングコスト、そして大手テック企業、OpenAI、VC、スタートアップ業界への影響について解説してます。
DeepSeekのイノベーション
DeepSeek-V2モデルでは、2つの重要なブレークスルーがあった。DeepSeek-V3モデルの革新の一つは、「専門家の混合(MoE: Mixture of Experts)」アーキテクチャの採用。従来のモデルでは、トレーニングや推論時に全てのパラメータが活性化されていましたが、MoEではモデルを複数の「専門家」に分割し、必要な部分のみを活性化させます。GPT-4は16の専門家を持つMoEモデルと考えられていますが、DeepSeekはより細かく専門化された専門家と、汎用的な能力を持つ共有専門家を組み合わせることで差別化を図っています。

もう一つは「MLA(Multi-head Latent Attention)」で、推論時のメモリ使用量を大幅に削減している。モデルをメモリにロードし、コンテキストウィンドウを読み込む必要がありますが、コンテキストウィンドウはメモリ的に高コスト。DeepSeekのMLAは、キー・バリュー・ストアを圧縮することで、メモリ使用量を劇的に減らしています。

$5.6Mのトレーニングコストはあり得るのか?
DeepSeek-V3では、これらの新しい負荷分散アプローチを導入し、トレーニングコストをさらに削減させた結果、モデルのトレーニングに2,788千H800 GPU時間を費やし、GPU時間あたり$2のコストで、総額$5.56Mと主張している。この$5.56Mの数字に対してかなりテック業界では話題になり、多くの人はそれは不可能だと主張した。実際に論文での注釈の部分にこの$5.56Mの計算方法を説明しているが、そこではV3のトレーニングのみが含まれていて、トレーニング前の研究やアーキテクチャ、アルゴリズム、データに関するアブレーション実験のコストは含まれていないと明記されている。AIチップの獲得コストはいないこととV2とV3モデルでのイノベーションを合わせるとトレーニングコストだけで$5.56Mで実装させることは不可能ではなさそうと多くのエキスパートと予想している。

AIチップに関してDeepSeekの研究レポートには約10,000台のNvidia A100と2,000~3,000台のNvidia H800を使用したと記載。なんとなくだが、今のA100とH800の価格をベースに想定すると少なくとも数百億円はかかると思われる。DeepSeekが去年末に出た時も、今回のDeepSeek-R1が出た時も数名の起業家やVCはDeepSeekは実はA100やH800のAIチップではなく大量のNvidia H100チップを抱えていると予想・主張する人もいた。H100のAIチップはより高いチップ間メモリ帯域幅を抱えているからこそ最先端のモデルのトレーニングには必要だと思われていた。OpenAI、Microsoft、xAI、Amazonなど大手テック企業は基本的にH100を利用しているが、DeepSeekはH100を購入できない状況にある。その理由はバイデン政権が実施した中国企業に対するチップの輸出禁止を儲けている。そのため、Scale AI CEOのAlexandr WangなどはDeepSeekはH100を抱えていることを明かすことができないため、A100やH800だけでこのモデルを作れたのは嘘をついている可能性があると考えている。
中国企業は本来は販売を禁止されているのに大量のNvidia H100チップを抱えているとScale AI CEOのAlexandr Wangが主張。
— Tetsuro Miyatake (@tmiyatake1) January 25, 2025
話題になっているDeepSeekは5万枚のNvidia H100チップを持っていると噂されている。 pic.twitter.com/JkZC9ydPt0
ただ、この仮説は個人的には間違っていると思っている。バイデン政権は確かにH100のAIチップの輸出を制限されているが、H800は制限されていない。DeepSeekはH100を持っていれば、わざわざV2で開発したMoEやMLAに注力せずに似たような結果が出来るかな可能性はある。逆に言えば、H100を使えなかったからこそ生まれたイノベーションと言っても過言ではなさそう。そう考えると、今回のDeepSeekは恐らくほとんどのアメリカのAI基盤モデルを開発している大手AI企業は作れなかった技術かもしれない。OpenAI、Anthropic、Microsoft、Apple、Amazon、Metaはそれぞれ大型投資をする覚悟でAIモデルを開発していて、よりお金をかければより良いモデルが作れるという前提で動いていた部分はある。DeepSeekはそれが出来なかった状況だからこそMoEとMLAを開発できたかもしれない。
なぜDeepSeekはオープンソースなAIモデルを開発したのか?
まず、DeepSeekは完全にオープンソースではない。ウェイトなどをオープンにしているが、データやコードは含まれていないので、完全にオープンソースではないが、ほぼ無料で提供しているのは大事なポイントではある。DeepSeek創業者がなぜオープンソースにしているのかと聞かれた際に大きく二つの理由があると発言した。まずはオープンソースにすることによって人材獲得がしやすくなること、そして二つ目は革命的なテクノロジーが出てくる際にはクローズドソースの優位性は一時的でしかないと発言した。OpenAIでさえクローズドなアプローチを行っても他社がすぐにキャッチアップしてしまうため、DeepSeekはAIモデルを作るプロセスとノウハウを組織化してイノベーションを作り続けられる組織を作るのが最大の優位性であると主張した。
DeepSeekのインタビューは非常に参考になるので、こちらのURLでご覧ください。
このオープンソースにする話はちょうど1ヶ月ほど前にOff TopicのDaily Memoで話した、OpenAIはインターネット初期のAOLと近しいポジションなのかもしれないと言う話に似ている気がする。
基本的に新しいテクノロジーが出てくると、エンドユーザーとしては実はそこまで使い勝手が良くない。初期インターネットはまさにその良い事例。様々なサイトのフォーマットが統一されてなかったり、安全性が担保されてなく、新しいコンテンツやサイトを見つけるのも難しかった。初期インターネットは検索エンジンが存在しなかったので、何を使っていろんなサイトを訪れたのかというとAOLなどポータルサイトを活用した。アメリカではAOLが初期に普及したインターネットサービスだが、今考えてみるとAOLはクローズド版のインターネットは提供していた。基本的に全てをAOL内で完結できるようにしていた。そのため、メール、チャット、フォーラム、ニュース、スポーツ、天気などのサービスを全て提供していた。ただ、それは本当のオープンインターネットではなかったかもしれないが、ユーザー体験としては当時の煩雑でユーザーとしては複雑すぎるオープンインターネットと比較するとUI/UXが圧倒的に良かった。AOLがTime Warnerを買収したのも、ユーザー数が落ちている中でよりバーチカル連携をすればユーザーをロックインできると思っていたが、実際の問題は初期のオープンインターネットの使い勝手が悪かったかもしれないが、その使い勝手が徐々に進化してより幅広く、優れたサービスを提供し始めた。結果的にクローズドだったAOLは無料でオープンなインターネットには勝てなかった。
そのような歴史がAI時代でも繰り返されているという仮説を立てると、AOL役はおそらくOpenAIになる。複雑でユーザーにとってどのように活用するべきかが分からなかったAI生成技術をChatGPTなどを通して圧倒的に使い勝手が良かった体験をOpenAIが提供してくれた。そしてそれに対してお金をとっているが、最終的にオープンなインターネットによって無料で似たパフォーマンスを出せる他社サービスが今後出てくることを考えると、OpenAIが進化してAOLみたいな状況を避けられるのかが気になる。MetaのLlama、そしてAppleが披露したオンデバイスのAIなどを考えると、クローズドな戦略がどこまで成立するのかは見どころになりそう。
DeepSeekの課題
もちろんDeepSeekは色んな課題を抱えている。まずは、明確に分からないのはどこからトレーニングデータを取得したのか、そしてそれが無許可で行ったのかなど。恐らく大規模で複雑なモデル(教師モデル)が学習した知識を、より軽量でシンプルなモデル(生徒モデル)に転移させる技術(蒸留)を活用したが、それは恐らく他社モデルを無許可でやっているはず。ただ、このような手口は他のモデルもやっているからこそ今ではGPT-4oレベルのAIモデルがかなり増えている。明確にはDeepSeekがGPT-4oなどを蒸留したとは言い切れないが、やっててもおかしくない。

アメリカのテック企業とアメリカ政府として一部の人が懸念しているのは、DeepSeekは中国企業であること。ちょうど今月TikTokを禁止にする話が話題になったのに、また中国企業のサービスが人気になり、アプリストアでは1位まで上がってきた。中国政府が行うような検閲をしながら、明確にプライバシーポリシーに収集したデータを中国のサーバーに保管していて、個人情報はユーザーが住んでいない国に保管する可能性があると記載している。DeepSeekに入力する情報は基本的に全て収集するとも記載していて、さらにユーザーのIPアドレス、クッキー、デバイス情報やキーストロークなども集められるような規約になっている。そのため、米中の関係性に対して嫌厭している人たちはこれは中国政府があえてオープンソースにしてアメリカ人の情報を吸い上げながらアメリカのAI企業を潰すための試作だと指摘している。個人的にはそのような意図でやっているのかは分からないが、そのリスクはゼロではなく、情報の取り扱いは他のAIモデルを使うよりも気をつけている。
逆にDeepSeek側として少し懸念しているのは、このような発展をした影響でよりアメリカ政府がAIチップの輸出制限を厳しくするかもしれない。今まではH100などより高度なAIチップを購入できなかったのを、H800などもそのリストに含まれると中国のAI企業としてはかなり厳しくなるかもしれない。
ただ、オープンソースだからこそ複数のスタートアップが既にDeepSeekを活用しながらデータの保管やアウトプットのリスクを削減できると発言している。Perplexityは既にDeepSeekを組み込んでいるが、そのリスクはないと語っている。
Essentially, the DeepSeek you get within Perplexity Pro searches is American. Both in values (no censorship) and in hosting and storage of your data. 🇺🇸🇺🇸🇺🇸
— Aravind Srinivas (@AravSrinivas) January 28, 2025
大手テック企業への影響
DeepSeekのニュースによって多くの大手テック企業の株価が落ちているが、基本的にはDeepSeekのようなイノベーションは各企業にとって良いことのはず。今まではデータセンターやエネルギーだけではなく、AIチップや自社モデルを開発するために大型投資が必要だったのが、思った以上にAIモデルのトレーニングコストがかからない方法もあることが認識された。長期的には大手テック企業のAI投資額が落ちれば、そのコストを消費者が使うプロダクトに反映されなくなるので、より多くの人は安くAIモデルを活用できるようになる。MetaはそもそもオープンソースなAIモデルを推していて、自社のビジネスモデルにAIモデルの利用を組み込んでなかったの悪影響はなさそう。Amazonは自社モデルの開発に苦しんでいると噂されているので、DeepSeekのようなオープンソースなモデルが出てくると喜んで使える。Microsoftもデータセンターなどの投資額を削減できるのは非常にありがたいことと思っていて、AppleもAIモデルのメモリ条件を削減できるとよりデバイス内でAIモデルの処理ができることに対して満足するはず。それぞれの前提としてあるのはDeepSeekのような中国からのモデルだけではなく、今後アメリカ企業が似たようなものを作ってそれもオープンソースすること。
MetaがAIモデルをオープンソース化する理由。 pic.twitter.com/aRGuhvtOTS
— Tetsuro Miyatake (@tmiyatake1) January 28, 2025
一番DeepSeekと悪影響を受けるのは、自社のAIチップは積極的に作っていたGoogleとNvidia。元々はGoogleとしてはTPUと言うハードウェア周りのアドバンテージを抱えていたのがDeepSeekのようなものが出てくると優位性がそこまで強くなくなり、さらに言うとAIモデルを利用するコストが下がるので競合のAI検索エンジンのコストも下がり、競争環境がより激しくなる可能性が高まる。Nvidiaとしてはどんどん最先端のAIチップを出し続けたからこそ多くのAI企業はそのAIチップを改善・最大限に利用するよりも次のAIチップを購入した方がリターンが出ると思っていたのが、今回のDeepSeekで少しゲームが変わった可能性はある。全体としてはAIの利用はこれから増える方向性で、今回のDeepSeekのような発展によってさらに利用率が増えることが想定されていることを考えるとまだNvidiaとしては困らなそうではある。

ちなみにどの大手テック企業の中では何故DeepSeekにこんなに簡単に追い越されたのか社内で調査・議論が行われている。例えばMetaでは次のLlamaはDeepSeekほどのパフォーマンスに至らないことが心配され、Llamaを改善するためにDeepSeekを分析する4つの「War Room」(コマンドセンター)を立ち上げ、MetaのAI生成技術チームおよびインフラチームがアサインされた。二つのグループではDeepSeekがどのように低コストでトレーニングを出来たのかを調べて、そのテクニックをLlamaに適応しようとしているらしい。3つ目のグループはDeepSeekがどのようなデータを使ってそうなのかを調べようとしていて、4つ目のグループではDeepSeekの特徴をベースにどのように自社のLlamaモデルを再構築できるのかを検討している。
OpenAIとAnthropicへの影響
今回のAIモデルでのイノベーションはOpenAIおよびAnthropicが恐らくかなり影響される。その大きな理由は、両社ともAIモデルがビジネスモデルの基盤となっているので、それをオープンソース化されてしまうと根本の事業の価値が下がってしまう。個人的にはOpenAIよりもAnthropicがまず非常に危機感を感じている気がする。そもそもOpenAIには追いついてない中でClaudeのアプリを推していたが、DeepSeekの登場で一気にアプリランキングでClaudeを追い越した。
DeepSeekがアメリカのiOSアプリストアで1位になった。 pic.twitter.com/gQd4ireofs
— Tetsuro Miyatake (@tmiyatake1) January 27, 2025
今後もこれが続くか分からないのと、DeepSeekは中国企業のためアメリカ政府が制限しにくるかもしれないが、Anthropicがまだトラクションが足りてない中で今後より多くのDeepSeek的なプレイヤーが出てくることを想定すると厳しいかもしれない。Together AIは過去2週間ほど毎日DeepSeekモデルのキャパを2倍増やしていて、複数のTogether AIの顧客はAnthropicのClaude 3.5 SonnetからDeepSeekに移行し始めているとTogether AI CEOのVipul Ved Prakashが語る。個人的にも複数のスタートアップがDeepSeekに乗り換えていることを聞いているので、想定以上に早いスピードでAnthropicの利用率が落ちるのかもしれない。
OpenAIについては正直まだ分からない。多くの人はOpenAIはChatGPTの影響によってC向けテック企業になったと言っている。そのためDeepSeekのようなサービスが出てきたとしても、ビジネスモデルはユーザーからのサブスク課金や広告で生き残れるので問題ないと思われている。短期的にはそれは間違いないと思っているが、長期的にはChatGPTの人気が続くのかが分からないと思っている。去年は$3.7Bの売上に対してChatGPTだけで$2.7Bぐらい(73%)を占めたと思われている。

その数字だけを見るとOpenAIはC向け企業として成り立つと思えるかもしれないが、長期的には続くかは不明。そもそもChatGPTを多くのユーザーが使っている理由はChatGPTの回答のクオリティが高いからであり、それがより高いクオリティの回答を出し続けられるサービスが出てくればユーザーはそっちに移行する可能性はある。そう考えると、OpenAIがChatGPTを伸ばし続けるためにはディストリビューションをよりアグレッシブに拡大すること、そして何かしらの方法でそのディストリビューションをスイッチングさせにくくさせること。Googleとかだと様々なプラットフォームとGoogleの検索エンジンをデフォルトにするための契約を結んでいたが、同じようなことをOpenAIが出来るのかは分からない。今現在Appleとの契約も独占契約ではなさそうで、Apple側も他のAIモデルを導入する予定だと明確に発言したことがある。
OpenAIが上手くいかないかもしれない要因をSocial CapitalのChamath Palihapitiyaが解説した。
— Tetsuro Miyatake (@tmiyatake1) October 2, 2024
・オープンソースの普及で独自LLMの経済価値が落ちる
・MetaやGoogleなどAIを利用する窓口が取られる
・大企業が優位になる合成データを集めるレースになる
・OpenAIの経営メンバーの相次ぐ退任 pic.twitter.com/fCAJAAIibG
そうするとOpenAIとしては過去の無料のOff Topic Daily Memoでも書いたように、C向けのプラットフォームではなくインフラ・バックエンド側のプラットフォームとして勝つのが正しい気がする。ただ、これを実現するには大前提としてあるのはOpenAIのAIモデルが他社よりもクオリティが高いこと、そしてクオリティが高いだけではなく、その分のコストもある程度やすいこと。これはStripeと似たようなカオナシプラットフォームの戦略となる。

詳細は以下Daily Memo記事をご覧ください。
VCへの影響
2023年から多くのVCはAI生成技術のトレンドに乗るためにかなり多くのAIスタートアップに投資した。去年アメリカでは全体の投資がなのでの41%をAIスタートアップが占めるぐらい、AI領域が熱かった。
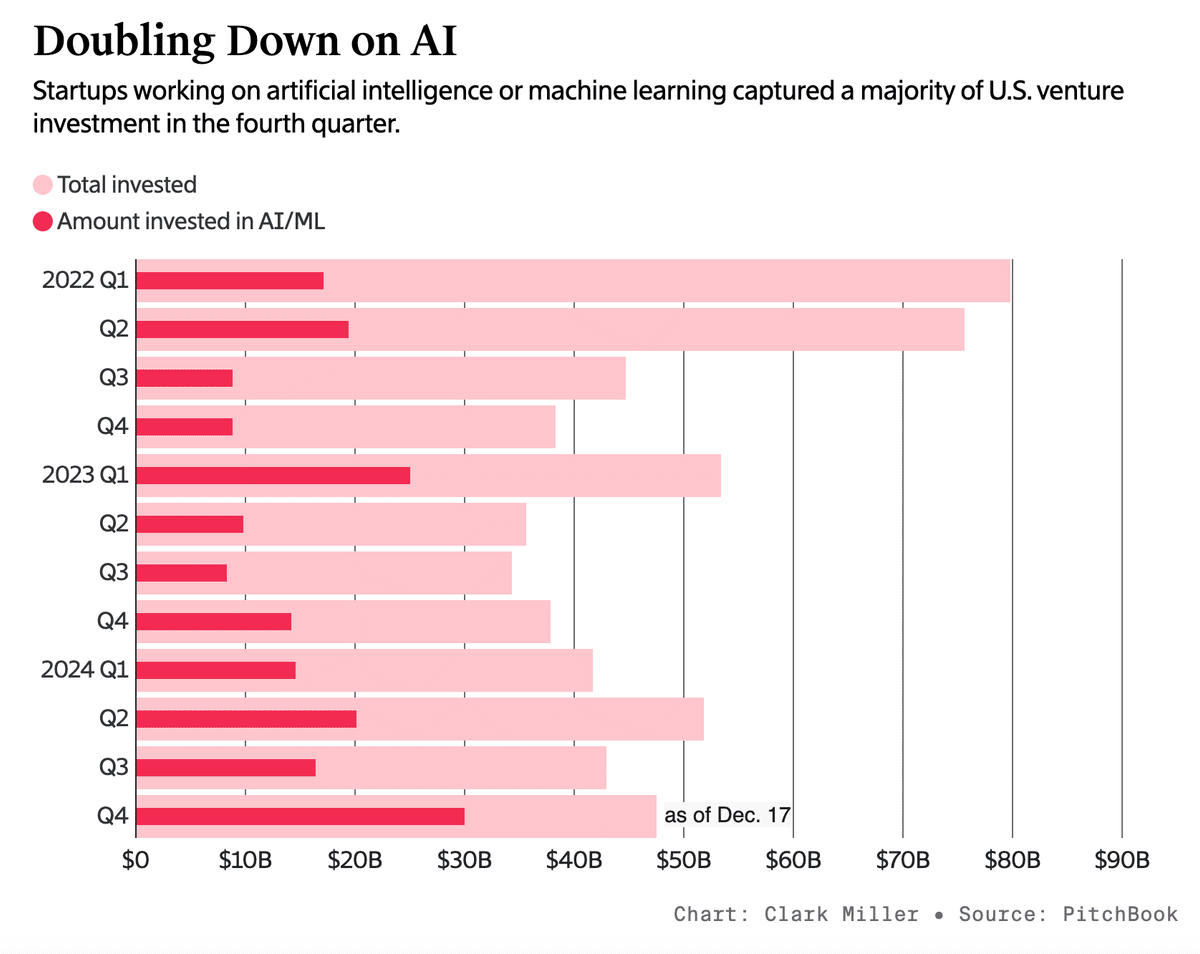
その中でも特に大型調達を必要としたのはAI基盤モデルを開発しているxAI、OpenAI、Anthropicなど。
OpenAI、Anthropic、xAIの累計調達額の変動。 pic.twitter.com/4lBEHHx89c
— Tetsuro Miyatake (@tmiyatake1) December 8, 2024
今回のDeepSeekの登場により、多くのVCは恐らくAI領域への投資戦略を少し見直すはず。Sequoiaなどはあえて基盤モデルではなくアプリに投資すると決めていたのである意味救われたが、多くのVCはかなりドライパウダー(投資可能予算)を持っていたため、大型出資が必要だったAI基盤モデルを開発しているスタートアップと相性がフィットしていた。ただ、それが思った以上にうまくいかない可能性はある。例えばAnthropicは直近ラウンドで$60Bぐらいを想定しているが、今まで累計$15.7Bほど調達している。AI基盤モデルへの投資額はAI投資の全体のかなり多くを占めているため、そこのパフォーマンスが悪化すると多くのVCは厳しいファンドパフォーマンスになる可能性が高まってしまう。
スタートアップへの影響
今回のDeepSeekの登場によって言えるのは、スタートアップとしてAIモデルそのものが技術的な優位性になり得る可能性は大分下がったこと。既にこれは多くのVCや起業家も言っていたことだが、結局裏のテクノロジーはコモディティ化されるため、残る優位性は他のところにある。
What YC startups actively in the idea maze right now are finding is that the moat is ultimately building great software still:
— Garry Tan (@garrytan) January 21, 2025
fixing all the bugs not just the obvious ones, having strong UX that help users accomplish their jobs to be done, extreme customer support https://t.co/jqrgiiBBvV
2年ほど前からOpenAIなど既存存在するAIモデルの上にサービスを提供する「AI wrapper」アプリが批判されていた。理由としては基盤モデルを誰でも提供できることを考えると、誰でも類似アプリを作れるので、AI wrapper的なサービスは優位性がないと言われていた。実態としては何かの技術にUI・サービスをラッピングするのは昔から当たり前であり、そこに本当の優位性があると言うこと。インタフェース・サービスレベルでのロイヤリティで勝負するのは結局AI時代でも変わらない。
DeepSeek just proved the 'worthless' GPT wrapper startups are actually the ones with real moats.
— GREG ISENBERG (@gregisenberg) January 27, 2025
A week ago, nothing was more LOW status than being a 'GPT wrapper' startup.
But I think we're learning that's DEAD wrong. Turns out they were just early to the only game that…
例えばウェブ2.0のサービスを見ても、Stripe、Uber、Robinhood、Snapなど様々な人気アプリは色んな技術の周りに特定のUI・UXをラッピングして価値を得られた。そのラッピングした技術はiPhoneやAWSだったりするが、それは最終的にAIモデルが落ち着く場所になるのかもしれない。ウェブ2.0以外でも、ほとんどの成功するビジネスはラッピングされているビジネスでもある。OpenAIはNvidiaをラッピングしたサービスで、NvidiaはTSMCをラッピングした企業で、TSMCはASMLをラッピングしたものだとPerplexity CEOのAravind Srinivasが語る。
AI Wrapperサービスがよく批判されるが、実は多くの成功しているビジネスはラッパービジネスだとPerplexity CEOのAravind Srinivasが語る。
— Tetsuro Miyatake (@tmiyatake1) November 18, 2024
OpenAIはNvidiaをラッピングしたサービスで、NvidiaはTSMCをラッピングした企業で、TSMCはASMLをラッピングしたもの。… pic.twitter.com/DHCTtZPDYM
実際にDeepSeekのようなオープンソースのAIモデルがこれからどんどん出てくることはOpenAIやAnthropicにとって微妙なことかもしれないが、AI領域で戦う起業家にとってはめちゃくちゃワクワクすることなはず。今までOpenAIのGPT-4oなどを使うのにめちゃくちゃお金かかっていたのが、DeepSeekみたいなサービスが出てくるとようやくある程度低コストでスケールすることが見込める。そして1回の利用でかなりのGPT-4モデルなどを使わなければいけなかったサービス体験なども作れるようになるので、今まで作れなかったようなアプリ・サービス・体験が生まれる可能性もある。これが個人的にDeepSeekの登場によって一番期待していること。
結論:新しいAIアプリの黄金時代が到達した
個人的にはDeepSeekのニュースにかなり興味を示しているのは、DeepSeekの技術的なイノベーションや中国がアメリカを一部のAI領域で越した話ではなく、DeepSeekはAI業界全体として大きな変曲点を示しているのかもしれないと思っているから。過去のOff Topicポッドキャストでも話したことがあるが、新しいテクノロジーシフトが起きると大体その中でアプリの時代とインフラの時代を行き来するサイクルが発生する。
大体アプリの時代が生まれ、そのあとはインフラの時代、そして再度アプリの時代と繰り返される。例えばインターネットが出てきた時はまずはメッセージやメールのようなアプリが生まれ、その影響でTCP/IPやISPなどのインフラが作られた。そのインフラを活用して成長したのがAOLで、その成功をきっかけにGoogle検索など次のインターネットの基盤となるインフラが出てきた。
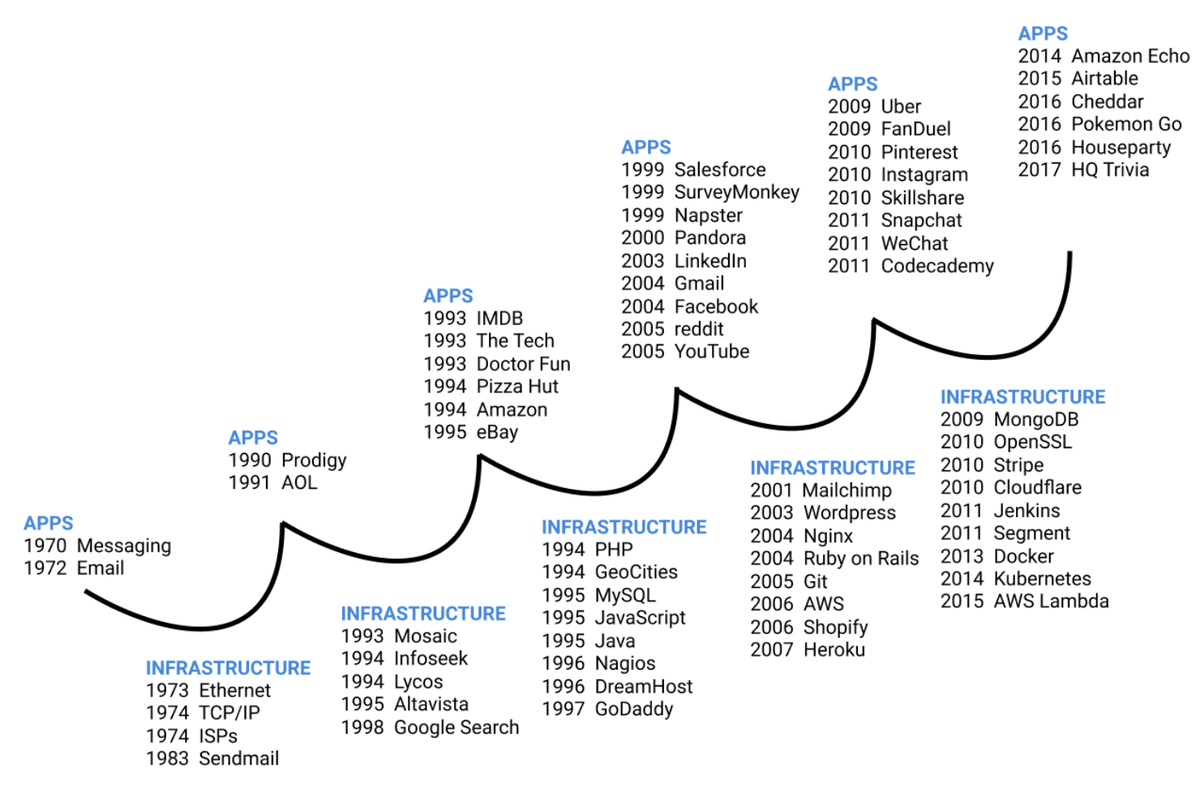
モバイルでも同じように、iPhoneとAndroid(アプリ)がまず出てきたからアプリストア(インフラ)が立ち上がり、そのインフラがあったからこそ初期モバイルアプリの成功したUber、Instagram、Snap(アプリ)が成長した。

そう考えると、AI時代ではこのアプリ・インフラのサイクルをどう見るべきなのか?2022年〜2023年はChatGPTというアプリの時代だった。その後はOpenAI以外にAnthropic、xAI、Mistralなど多くのAIモデルを作るようなインフラ系の会社が出てきた。もしかしたら今回のインフラのサイクルのピークが今回のDeepSeekではないかと個人的には感じている。一旦AIモデルへの重きが落ち着くことを想定すると、次に何が出てくるのかというとそのモデルを活用した新しいアプリ。今まではOpenAIが新しいモデルを出すたびに多くのスタートアップがサービスをシャットダウンしないといけなかったのが、ある程度モデルの精度が落ち着くとアプリの時代に入ってくる。個人的にはこれからはAIアプリの黄金時代が訪れる可能性があると思っていると同時に、そのようなアプリを見ることによって次のサイクルのインフラ系のサービスが何か見定められる気がする。
この記事が気に入ったらチップで応援してみませんか?