
【MLX】Macbookで、WhisperをローカルGUIで実行してみた

Appleシリコンに最適化されたML用ライブラリが出たとのことで、色々試していこうと思います!これまでMacbookだと動かしにくかった色々なものが、サクッと動かせるようになっていて感動してます。
今回は音声認識モデルのWhisperを、MLXを使ってローカル実行する方法についてまとめていきます。方法を調べるにあたって、以下の記事を参考にしました。ありがとうございます🙏
この記事で紹介すること
MLXによる Macbook 環境での Whisper の動かし方
画面上で音声ファイルを文字起こしをする方法
前提:動作環境
Macbook Pro、Apple M1 Maxチップ、メモリ64GBを使って検証してます。
Apple Siliconチップであれば、動作できると思いますが、メモリ不足で実行できないという場合があるかもしれません。ご了承ください。
やり方
mlx-examplesに、MLXを用いて様々なモデルを動かすためのコードが格納されています。今回はここにあるWhisperのコードを利用していきます。
環境構築
適当なディレクトリで以下のコマンドを実行します。
git clone https://github.com/ml-explore/mlx-examples.git続いて、Whisperのコードがあるディレクトリに移動して、環境構築をしていきます。
cd mlx-examples/whisper
# .venv という名前の仮想環境を作成
python3 -m venv .venv
# 仮想環境をアクティベート
source .venv/bin/activate
brew install ffmpeg
pip install -r requirements.txt
pip install mlx streamlit実行ファイルの用意
まずはスクリプトファイルを用意していきます。mlx-samples/whisper 配下に script.py ファイルを作成して、以下のコードを記述してください。
# mlx-samples/whisper/script.py
import time
import whisper
import argparse
# コマンドライン引数のパーサーを作成
parser = argparse.ArgumentParser(description="Transcribe audio file using Whisper.")
parser.add_argument("--model", default="tiny", help="Model to use for transcription.")
# 引数を解析
args = parser.parse_args()
speech_file = "audio_1.wav"
start_time = time.time() # 開始時間を記録
text = whisper.transcribe(
speech_file,
model=args.model,
initial_prompt="こんにちは。今日は、よろしくお願いします。" # 句読点形式で文字起こしさせるため
)["text"]
end_time = time.time() # 終了時間を記録
elapsed_time = round(end_time - start_time, 1) # 経過時間を計算
print(text)
print(f"経過時間: {elapsed_time} 秒") # 経過時間を出力なおここでの import whisper は、mlx-samples/whisper/whisper を読み込んでいます。この配下にある transcribe モジュールを用いて、文字起こしを行います。
では実行してみましょう。その前に文字起こしする音声ファイルを mlx-samples 配下に音声ファイルを配置する必要があります。
もし良さそうな音声ファイルが見当たらない場合、以下のファイルを利用してみてください。
以下のコマンドを実行するとスクリプトを実行できます。なお初回はモデルロードに時間がかかります。
python script.py
> さて早くに想像さえかいされた甘々の工場なんですけれども、そのこの防災対策ということではどのようなことを進められたんでしょうか。
> 経過時間: 1.0 秒少し精度が悪いですね。
デフォルトでは tiny モデルという最も小さいサイズのモデルが利用されているので、少し大きめなモデルで試してみましょう。以下のように実行できます。
python script.py --model small
> さて、早くに創業を再開された 甘岡先の工場なんですけれども、その後の防災対策ということでは どのようなことを進められたんでしょうか。
> 経過時間: 2.9 秒
python script.py --model base
> さて、早くに総業再開された、マガ先の工場なんですけれども、その後の防災対策と、ということでは、どのようなことを進められたのでしょうか。
> 経過時間: 1.4 秒
python script.py --model medium
> さて、早くに創業再開された 長崎の工場なんですけれども、その後の防災対策ということではどのようなことを 進められたんでしょうか。
> 経過時間: 6.8 秒
python script.py --model large
> さて、早くに創業再開された尼崎の工場なんですけれども、その後の防災対策ということでは、どのようなことを勧められたんでしょうか。
> 経過時間: 12.1 秒※先ほどの音声ファイルの長さは12秒なので、largeまでになると等倍の処理時間がかかっていることになります。
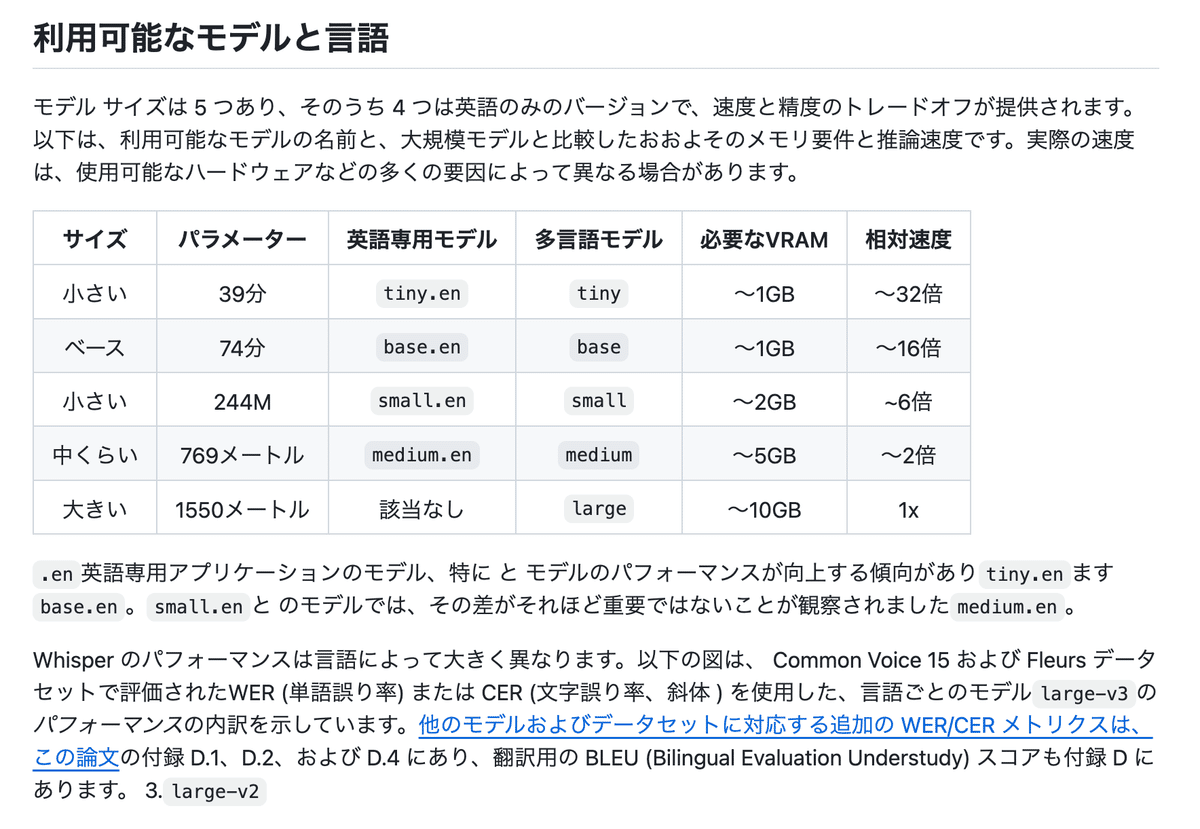
ちなみにモデルの詳細はこんな感じです。
画面上で文字起こしをする
先ほどのスクリプト形式だと、毎回音声ファイルを配置して、コードを書き換えて、、、と面倒くさいですよね。
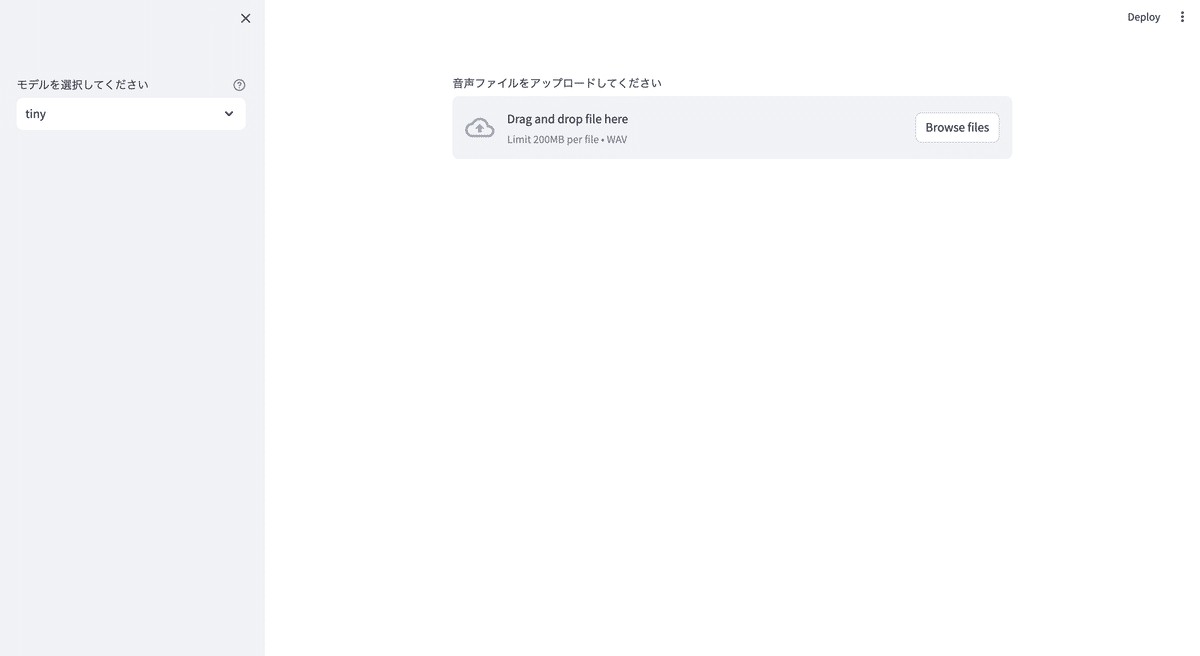
そこで、ここからは画面上から音声ファイルをアップロードして利用できるようにしていきます。
mlx-examples/whisper 配下に、 app.py を作成して以下のコードを記載してください。
# mlx-examples/whisper/app.py
import time
import whisper
import streamlit as st
# モデルの選択
model = st.sidebar.selectbox(
"モデルを選択してください", ("tiny", "base", "small", "medium", "large"), help="文字起こしに使用するモデルを選択します。"
)
# 音声ファイルのアップロード
uploaded_file = st.file_uploader("音声ファイルをアップロードしてください", type=["wav"])
if uploaded_file is not None:
# 音声ファイルを一時的に保存
with open("temp.wav", "wb") as f:
f.write(uploaded_file.getbuffer())
speech_file = "temp.wav"
start_time = time.time() # 開始時間を記録
# 音声ファイルの文字起こし
text = whisper.transcribe(
speech_file, model=model, initial_prompt="こんにちは。今日は、よろしくお願いします。"
)["text"]
end_time = time.time() # 終了時間を記録
elapsed_time = round(end_time - start_time, 1) # 経過時間を計算し、小数点一桁までに丸める
# 文字起こしと経過時間を出力
st.write(text)
st.write(f"経過時間: {elapsed_time} 秒")
その後、以下のコマンドをターミナルで実行します。
streamlit run app.pyそうすると、ブラウザ上に画面が立ち上がります。これで画面上から音声ファイルをアップロードして、文字起こしができるようになりました。ローカルに閉じた形で、無料で利用が可能です🙆♂️

おわりに
mlx-examples にある whisper は、思った以上に結構サクッと利用できてびっくりしました。Whisper以外にも様々なモデルがあるので、他にも色々と調べてみたいところです。
Macbook では正直モデル動かすの大変そうだなー、と諦めていたところでしたが、MLXのおかげで楽しくなってきました…!!!