
ChatGPT×Slack、仕事で質問しずらい問題を解決するアイデアメモ。多分インパクトは大きい気がする。

思考メモとして残しておきます。ありきたりな発想ですが、どこかがやっている事例も聞いたことないので、言語化を試みます。おそらく半年以内にどこかが社内実装の取り組み事例を記事化するはず。
課題感はなにか
社内情報へのアクセス性が低い人にとって、仕事を進める中でストレスを感じるシーンが多いということ。
ここでの"社内情報へのアクセス性"とは、どれくらい社内特有の知識について知っている、あるいは知るための方法をどれくらい知っているか、どうかということです。
例えば、稟議の方法であったり、社内特有の申請方法、そのプロジェクトの背景であったり、特定タスクを進めるにあたって確認すべき人は誰か、運営サービスにおけるドメイン知識などなど。これらは仕事を進める上で、前提知識として求められてくるケースが多いです。
こういった知識は仕事を進める中で、既存社員に聞いたりする中で徐々に培われていくものだと思います。ただ入社したての頃は、こういった情報を知る術を持ち合わせていないことが多く、誰かに聞くということが一般的な解決方法になってきます。
ただ信頼関係がまだ構築されていなかったり、リモートワークで顔が見えない関係の人に質問をするということは、割と負荷が大きい作業です。
そして仕事を進める上で、細切れに何回も質問をせざるを得ない状況というのも往々にしてあり、忙しい中で何度も質問してしまう申し訳なさや、現在直面している背景を共有する難しさ、返信が来るまで仕事を進められないもどかしさが発生してきます。
こういった課題を解決するために、
既存社員とペアで仕事を進めて聞きやすい関係を作る
社内情報のドキュメント化を整備してアクセスできるようにする
このような手法は組織によっては取られてきていると思いますが、ChatGPTを組み合わせれば、より革新的なソリューションを実現できるのではないか?と思い立ったのが今回の背景です。
解決策として
Slackなどのコミュニケーションツールで、社内情報について回答してくれるBotを用意し、知りたい情報をピンポイントで質問し、即座に情報を得られる仕組みを整備する。
簡潔にいうと、知りたい情報をピンポイントかつ簡単に知れる、社内情報へのアクセスBotを作るという話です。
これを実現することで、これまでの課題が解消できると考えています。
質問に対する申し訳なさ
→相手はBotであるため、質問をするにあたってのハードルが低い現在直面している背景を共有する難しさ
→Botとの会話形式で、知りたい情報の背景を揃えていくことが可能返信が来るまで仕事を進められないもどかしさ
→Botなので遅くとも数分以内には返ってくる。また「処理に時間がかかっているんだ」という認識によって、精神的なもどかしさも緩和される
実現方法について
いくつかの前提のもと、実現方法を記載していきます。
前提として
・社内のコミュニケーションツールとしてSlackを中心に利用している
・Slack上にはいろいろな社内情報がストックされている
・その他のツールにも社内情報が蓄積されていて、任意にソース元として追加したい
具体的な内容
まず大枠としては、LLM(大規模言語モデル)を活用したQAサービスの手法を用います。いわゆる、社内情報をベクターストアに保管しておいて、受け付けた質問に類似する情報を逐次引っ張ってきて、それを前提情報として含めて、LLMに回答してもらうという方法です。
イメージをつけるために分かりやすい図と、処理の流れを記載します。
図解
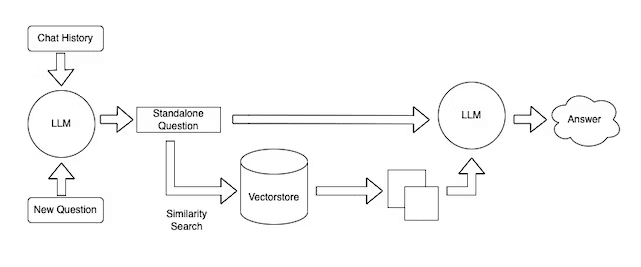
処理の流れ
ユーザーから質問を受け付ける
合わせて過去の会話履歴データを取得する
ユーザーの質問+会話履歴を合わせてLLMに投げて、答えるべき単独の質問(Standalone Question)に整形し直す。(色々な情報が雑多にあるため、答えるべき質問のみに情報を精査するステップ)
答えるべき質問内容に類似するドキュメントをベクターストアに対して検索をかける。(ここでの検索は一般的にベクトルを用いた"意味の近しさ"による検索になります。単語の部分一致などではありません)
質問内容に類似する幾つかのドキュメントを取得する
答えるべき質問(Standalone Question)と、いくつかの類似ドキュメントを合わせてLLMにリクエストし、回答結果をBotを通してユーザーに返す
ただし、この前段階として社内情報をベクターストア等に保管する前準備が必要となります。ざっくりいうと、次のような流れです。
各種ツールにある社内情報を読み込み可能な形(HTML, PDF, jsonなどなど)に変換する。
LangChainのDocumentLoadersに記載されている形式は読み込み可能なはず。
Slackであればチャンネルの内容をzipファイルにエクスポートする機能があるのでそれを利用すると取り込みが可能になる。
各種形式のデータから必要なドキュメント情報(テキスト形式)を抽出して、ある程度小さめなドキュメントサイズに分割する。(分割されたドキュメントは、一般的にChankと呼ばれている)
ベクトル表現に変換する(Embedding)
OpenAIのtext-embedding-ada-002がかなり低コストで利用可能
ベクトルデータとドキュメント情報をベクターストアに書き込む
ベクターストアについてはこちらのリポジトリがかなりまとまっています
どれがいいかは正直分からないですが、社内情報を扱うということもあり、AWSなどのクラウドサービスで社内に閉じたサーバを立てて、そこでOSSのライブラリを利用する形が安心なのかなと思っています
個人で利用する分にはPineconeが無料枠もありおすすめです
これらの処理は、OSSライブラリのLangChainやLlamaIndexなどを用いられることが多いです。実装の仕方などは、以下の記事がわかりやすいです。
以降は、ざっくりこんな感じで実装できるんじゃないか?を雑にまとめたメモになります。興味があれば、参考程度にご覧ください。
1. 前準備
LangChainを使うか、LangChainのコードを参考に自作するか。どちらでも良いと思いますが、LangChainを使う場合はバージョンが爆速で上がっていくので、バージョン管理を徹底するのが良いでしょう。
ここではSlackのデータに焦点を絞って、進めていきます。
1-a. Slackデータをzipでエクスポート
こちらのページに記載されている手順を進めていくと、データのエクスポートができるページにいきます。ここで日付範囲を選択すると、該当期間のパブリックチャンネルに投稿されたメッセージなどがエクスポートできます。

エクスポートを実行すると処理が開始します。SlackBotからDMで、zipファイルのDL準備が整った頃に連絡がきます。そこに記載されているリンクからzipファイルが届きます。

zipファイルを展開すると、次のようなファイルを見ることができます。主にはチャンネル情報(フリープランの場合はパブリック)、そして各チャンネル(ここでは「論文」チャンネル)の日付ごとのjsonファイルが取得できます。
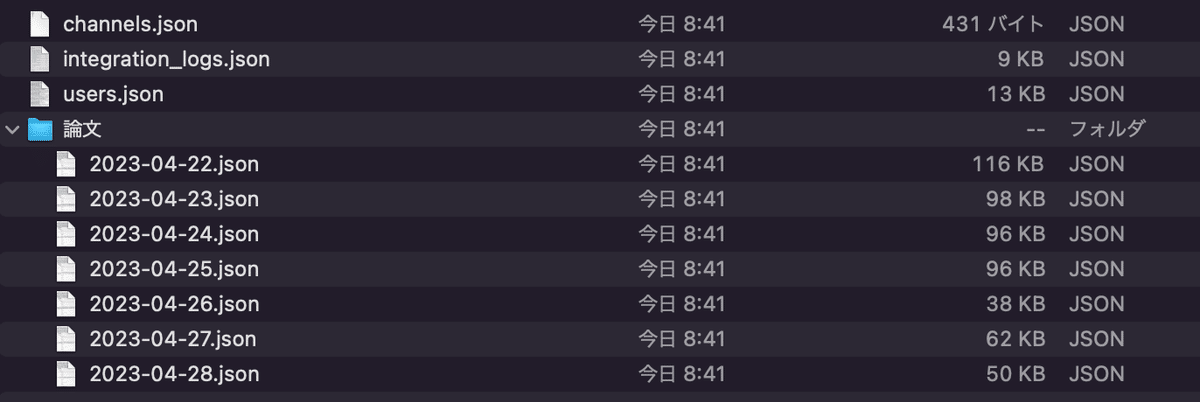
1-b. zipファイルからロードする
LangChainにはSlackDirectoryLoaderが存在します。これはzipファイルとしてエクスポートすれば、取り込みまで行うことができる高レベルな機能です。(ファイルの中身はこちらのGithubを参照)
ただ一方で、LangChainには5/7現在、取得するチャンネルを制御できるようにはなってません。zipファイルにある全チャンネルのメッセージがロードされます。
社内運用を考えたとき、もしかしたら(パブリックではあるが)Botが情報として保持できるチャンネルを絞りたいというニーズが出てきそうだなと思っており、これに現仕様では対応できません。なのでLangChainのSlackDirectoryLoaderをオーバーライドして利用するか、自作するかといったアプローチが考えられます。
# GPT-4をもとに作成(動くかは分かりません。あくまでイメージです。)
# ref: https://python.langchain.com/en/latest/modules/indexes/document_loaders/examples/slack.html
from langchain.document_loaders import SlackDirectoryLoader
# Optionally set your Slack URL. This will give you proper URLs in the docs sources.
SLACK_WORKSPACE_URL = "https://xxx.slack.com"
LOCAL_ZIPFILE = "" # Paste the local paty to your Slack zip file here.
class CustomSlackDirectoryLoader(SlackDirectoryLoader):
def __init__(self, zip_path: str, workspace_url: Optional[str] = None, allowed_channels: Optional[List[str]] = None):
super().__init__(zip_path, workspace_url)
self.allowed_channels = allowed_channels
def load(self) -> List[Document]:
docs = []
with zipfile.ZipFile(self.zip_path, "r") as zip_file:
for channel_path in zip_file.namelist():
channel_name = Path(channel_path).parent.name
if not channel_name or (self.allowed_channels is not None and channel_name not in self.allowed_channels):
continue
if channel_path.endswith(".json"):
messages = self._read_json(zip_file, channel_path)
for message in messages:
document = self._convert_message_to_document(
message, channel_name
)
docs.append(document)
return docs
loader = CustomSlackDirectoryLoader(LOCAL_ZIPFILE, SLACK_WORKSPACE_URL)
docs = loader.load()
docs1-c. ロードしたドキュメントをベクターストアへ書き込み
Slackということもあり、かなり機密情報が多いデータになってくる可能性があるので、AWSなどの会社で利用しているクラウド上で社内に閉じた形で利用するのが安心なのかなとも感じます。
ECSを利用して、FAISSを使った類似ドキュメントを検索できるAPIを立てるなどでしょうか。このAPI側でドキュメント取得できるチャンネルをコントロールするのもアリかもしれません。
FAISSはLangChainがサポートしており、下記が参考になります。
2. QAサービスの実装
ちょっとここからは実装方法は幅広くかつ一般的なので他記事に譲りますが、インターフェースとなるSlack botを作成することと、回答生成をする内部処理をそれぞれ実装する必要があります。
2-a. LLMを活用した内部処理
LLMを活用した内部処理についてはこちらが参考になります。
2-b. Slack Botの作成について
Slack Botの作成についてはこちらが参考になります。
おわりに
LLMの活用について、個人的にはサービスへの組み込みよりも、このような社内における仕事のしやすさの整備(業務効率化)の方が、ポテンシャルを秘めていると考えています。
私自身は育休に入るので、しばらくはこのような領域にコミットできないのですが、アイデアは色々湧いてくるので、時折こういった形でアイデアを言語化していきたいと思います。