
OpenAI WhisperAPIのwordレベルでの文字起こしを試したみた

こちらの投稿を見て、少し気になったので試してみました!
The Whisper Audio API now supports word-level timestamps!
— OpenAI Developers (@OpenAIDevs) February 9, 2024
With the new `timestamp_granularities` parameter, you can get word-level precision for transcripts and video edits.https://t.co/aON96JKlkk pic.twitter.com/sinyl77ypS
公式ドキュメントを読む
こちらを参考にしています。
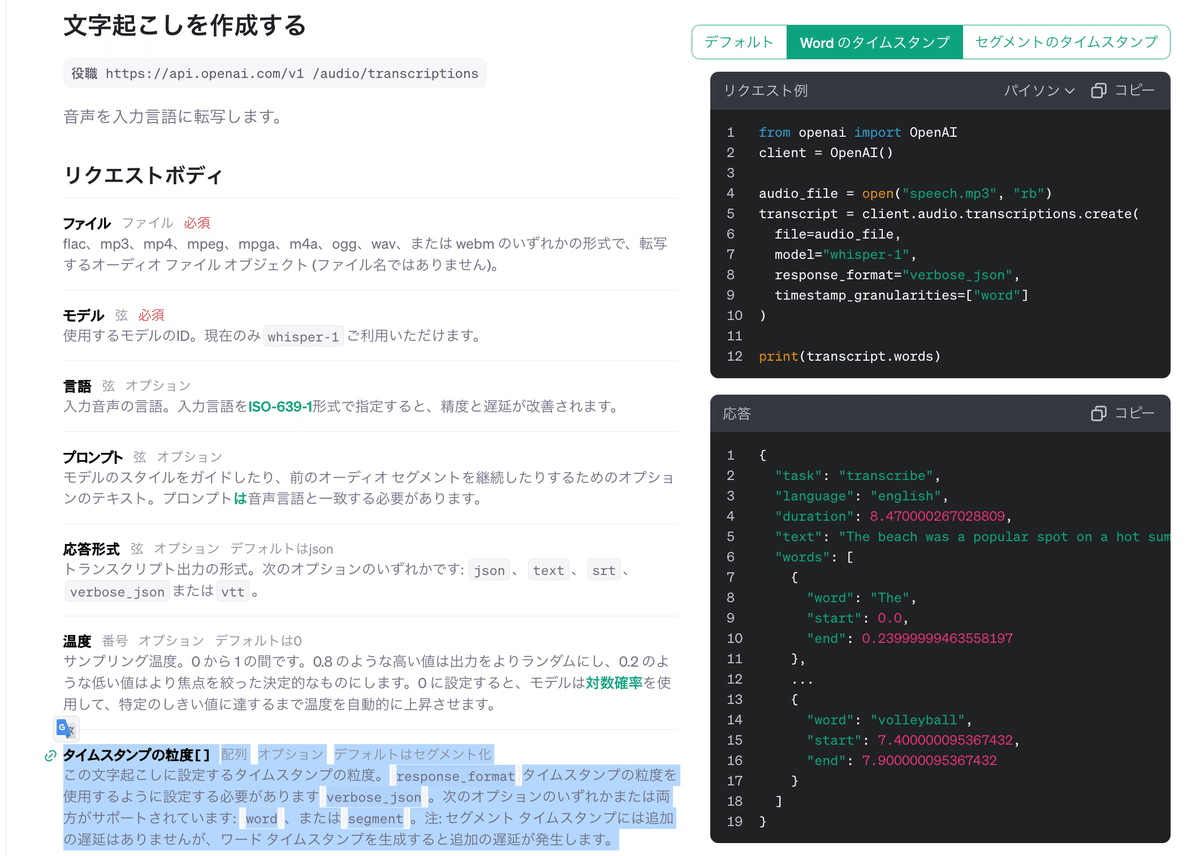
新しく `timestamp_granularities[]` というパラメータが追加されたようです(多分前は無かったはず)。ここで word と指定すると文字レベルで分割された文字起こし結果が出力されます。
また `response_format` を verbose_json にする必要もありそうです。
流石OpenAIといった感じで、ドキュメントの右側にリクエスト例もわかりやすく記載されていました!👏
では実際に試していきましょう!
実際に試してみる
以下のように timestamp_granularities=["word"] と設定して形でリクエストを送ってみます。
from google.colab import userdata
userdata.get('openai-practice') # OPENAI_API_KEYを取得
from openai import OpenAI
client = OpenAI(api_key=userdata.get('openai-practice'))
audio_file = open("audio_1.wav", "rb")
word_transcript = client.audio.transcriptions.create(
file=audio_file,
model="whisper-1",
response_format="verbose_json",
timestamp_granularities=["word"]
)
word_transcriptTranscription(text='さて早くに創業を再開された 尼崎の工場なんですけれども その後の防災対策ということでは どのようなことを進められたんでしょうか', task='transcribe', language='japanese', duration=11.890000343322754, words=[{'word': 'さ', 'start': 0.25999999046325684, 'end': 0.6200000047683716}, {'word': 'て', 'start': 0.6200000047683716, 'end': 0.6800000071525574}, {'word': '早', 'start': 0.6800000071525574, 'end': 0.9800000190734863}, {'word': 'く', 'start': 0.9800000190734863, 'end': 1.1200000047683716}, {'word': 'に', 'start': 1.1200000047683716, 'end': 1.6200000047683716}, {'word': '創', 'start': 1.6200000047683716, 'end': 1.6200000047683716}, {'word': '業', 'start': 1.6200000047683716, 'end': 1.7400000095367432}, {'word': 'を', 'start': 1.7400000095367432, 'end': 2.0799999237060547}, {'word': '再', 'start': 2.0799999237060547, 'end': 2.200000047683716}, {'word': '開', 'start': 2.200000047683716, 'end': 2.319999933242798}, {'word': 'さ', 'start': 2.319999933242798, 'end': 2.6600000858306885}, {'word': 'れた', 'start': 2.6600000858306885, 'end': 2.7799999713897705}, {'word': '尼', 'start': 3.0, 'end': 3.0}, {'word': '崎', 'start': 3.0, 'end': 3.180000066757202}, {'word': 'の', 'start': 3.180000066757202, 'end': 3.440000057220459}, {'word': '工', 'start': 3.440000057220459, 'end': 3.7200000286102295}, {'word': '場', 'start': 3.7200000286102295, 'end': 3.859999895095825}, {'word': 'なんです', 'start': 3.859999895095825, 'end': 4.440000057220459}, {'word': 'けれ', 'start': 4.440000057220459, 'end': 4.699999809265137}, {'word': 'ども', 'start': 4.699999809265137, 'end': 5.199999809265137}, {'word': 'その', 'start': 5.199999809265137, 'end': 5.599999904632568}, {'word': '後', 'start': 5.599999904632568, 'end': 5.920000076293945}, {'word': 'の', 'start': 5.920000076293945, 'end': 6.400000095367432}, {'word': '防', 'start': 6.400000095367432, 'end': 6.539999961853027}, {'word': '災', 'start': 6.539999961853027, 'end': 6.679999828338623}, {'word': '対', 'start': 6.679999828338623, 'end': 7.159999847412109}, {'word': '策', 'start': 7.159999847412109, 'end': 7.300000190734863}, {'word': 'ということ', 'start': 7.300000190734863, 'end': 8.180000305175781}, {'word': 'では', 'start': 8.180000305175781, 'end': 8.600000381469727}, {'word': 'ど', 'start': 8.600000381469727, 'end': 8.779999732971191}, {'word': 'の', 'start': 8.779999732971191, 'end': 8.880000114440918}, {'word': 'よう', 'start': 8.880000114440918, 'end': 9.039999961853027}, {'word': 'な', 'start': 9.039999961853027, 'end': 9.4399995803833}, {'word': 'こと', 'start': 9.4399995803833, 'end': 9.600000381469727}, {'word': 'を', 'start': 9.600000381469727, 'end': 9.760000228881836}, {'word': '進', 'start': 9.760000228881836, 'end': 9.899999618530273}, {'word': 'め', 'start': 9.899999618530273, 'end': 10.020000457763672}, {'word': 'ら', 'start': 10.020000457763672, 'end': 10.15999984741211}, {'word': 'れた', 'start': 10.15999984741211, 'end': 10.279999732971191}, {'word': 'んで', 'start': 10.279999732971191, 'end': 10.539999961853027}, {'word': 'しょう', 'start': 10.539999961853027, 'end': 10.699999809265137}, {'word': 'か', 'start': 10.699999809265137, 'end': 10.9399995803833}])
全体の文字起こし結果に加えて、wordsの中にワードレベルでの文字起こしと開始/終了時刻が出力されていますね。少し見にくいので、wordsの中身を取り出してみます。
word_transcript.words[{'word': 'さ', 'start': 0.25999999046325684, 'end': 0.6200000047683716}, {'word': 'て', 'start': 0.6200000047683716, 'end': 0.6800000071525574}, {'word': '早', 'start': 0.6800000071525574, 'end': 0.9800000190734863}, {'word': 'く', 'start': 0.9800000190734863, 'end': 1.1200000047683716}, {'word': 'に', 'start': 1.1200000047683716, 'end': 1.6200000047683716}, {'word': '創', 'start': 1.6200000047683716, 'end': 1.6200000047683716}, {'word': '業', 'start': 1.6200000047683716, 'end': 1.7400000095367432}, {'word': 'を', 'start': 1.7400000095367432, 'end': 2.0799999237060547}, {'word': '再', 'start': 2.0799999237060547, 'end': 2.200000047683716}, {'word': '開', 'start': 2.200000047683716, 'end': 2.319999933242798}, {'word': 'さ', 'start': 2.319999933242798, 'end': 2.6600000858306885}, {'word': 'れた', 'start': 2.6600000858306885, 'end': 2.7799999713897705}, {'word': '尼', 'start': 3.0, 'end': 3.0}, {'word': '崎', 'start': 3.0, 'end': 3.180000066757202}, {'word': 'の', 'start': 3.180000066757202, 'end': 3.440000057220459}, {'word': '工', 'start': 3.440000057220459, 'end': 3.7200000286102295}, {'word': '場', 'start': 3.7200000286102295, 'end': 3.859999895095825}, {'word': 'なんです', 'start': 3.859999895095825, 'end': 4.440000057220459}, {'word': 'けれ', 'start': 4.440000057220459, 'end': 4.699999809265137}, {'word': 'ども', 'start': 4.699999809265137, 'end': 5.199999809265137}, {'word': 'その', 'start': 5.199999809265137, 'end': 5.599999904632568}, {'word': '後', 'start': 5.599999904632568, 'end': 5.920000076293945}, {'word': 'の', 'start': 5.920000076293945, 'end': 6.400000095367432}, {'word': '防', 'start': 6.400000095367432, 'end': 6.539999961853027}, {'word': '災', 'start': 6.539999961853027, 'end': 6.679999828338623}, {'word': '対', 'start': 6.679999828338623, 'end': 7.159999847412109}, {'word': '策', 'start': 7.159999847412109, 'end': 7.300000190734863}, {'word': 'ということ', 'start': 7.300000190734863, 'end': 8.180000305175781}, {'word': 'では', 'start': 8.180000305175781, 'end': 8.600000381469727}, {'word': 'ど', 'start': 8.600000381469727, 'end': 8.779999732971191}, {'word': 'の', 'start': 8.779999732971191, 'end': 8.880000114440918}, {'word': 'よう', 'start': 8.880000114440918, 'end': 9.039999961853027}, {'word': 'な', 'start': 9.039999961853027, 'end': 9.4399995803833}, {'word': 'こと', 'start': 9.4399995803833, 'end': 9.600000381469727}, {'word': 'を', 'start': 9.600000381469727, 'end': 9.760000228881836}, {'word': '進', 'start': 9.760000228881836, 'end': 9.899999618530273}, {'word': 'め', 'start': 9.899999618530273, 'end': 10.020000457763672}, {'word': 'ら', 'start': 10.020000457763672, 'end': 10.15999984741211}, {'word': 'れた', 'start': 10.15999984741211, 'end': 10.279999732971191}, {'word': 'んで', 'start': 10.279999732971191, 'end': 10.539999961853027}, {'word': 'しょう', 'start': 10.539999961853027, 'end': 10.699999809265137}, {'word': 'か', 'start': 10.699999809265137, 'end': 10.9399995803833}]
またこのワードレベルの文字起こしをする際に、response_formatをverbose_jsonにしないと以下のようなエラーが出ます。
---------------------------------------------------------------------------
BadRequestError Traceback (most recent call last)
<ipython-input-23-2aba1fb74181> in <cell line: 5>()
3
4 audio_file = open("audio_1.wav", "rb")
----> 5 word_transcript = client.audio.transcriptions.create(
6 file=audio_file,
7 model="whisper-1",
3 frames
/usr/local/lib/python3.10/dist-packages/openai/_base_client.py in _request(self, cast_to, options, remaining_retries, stream, stream_cls)
978
979 log.debug("Re-raising status error")
--> 980 raise self._make_status_error_from_response(err.response) from None
981
982 return self._process_response(
BadRequestError: Error code: 400 - {'error': {'message': 'Timestamp granularities are only supported with response_format=verbose_json', 'type': 'invalid_request_error', 'param': 'timestamp_granularities', 'code': 'timestamp_granularities_format'}}ちなみに timestamp_granularities["segment"] ではどうなるかというと、、、
segment_transcript = client.audio.transcriptions.create(
file=audio_file,
model="whisper-1",
response_format="verbose_json",
timestamp_granularities=["segment"]
)
segment_transcriptTranscription(text='さて早くに創業を再開された 尼崎の工場なんですけれども その後の防災対策ということでは どのようなことを進められたんでしょうか', task='transcribe', language='japanese', duration=11.890000343322754, segments=[{'id': 0, 'seek': 0, 'start': 0.0, 'end': 5.260000228881836, 'text': 'さて早くに創業を再開された 尼崎の工場なんですけれども', 'tokens': [50364, 6722, 2996, 21176, 6134, 4108, 5935, 113, 27119, 5998, 8623, 8949, 6722, 35478, 220, 1530, 120, 49378, 236, 2972, 23323, 21446, 42255, 39256, 41397, 50627], 'temperature': 0.0, 'avg_logprob': -0.25088003277778625, 'compression_ratio': 1.2816901206970215, 'no_speech_prob': 0.004049140028655529}, {'id': 1, 'seek': 0, 'start': 5.260000228881836, 'end': 11.720000267028809, 'text': 'その後の防災対策ということでは どのようなことを進められたんでしょうか', 'tokens': [50627, 20564, 5661, 2972, 35863, 13290, 121, 35252, 7973, 244, 29502, 16719, 34994, 2972, 17010, 3203, 13235, 5998, 18214, 11429, 5154, 35478, 35356, 17609, 3703, 50950], 'temperature': 0.0, 'avg_logprob': -0.25088003277778625, 'compression_ratio': 1.2816901206970215, 'no_speech_prob': 0.004049140028655529}])
あまりverbose_json 形式での出力をしたことがなく、馴染みがないフィールドもあったので調べてみました。
id: トランスクリプションされたセグメントの一意の識別子です。各セグメントは、トランスクリプションプロセス中に処理された音声の特定の部分を表します。
seek: トランスクリプション対象の音声ファイル内でのセグメントの開始位置を示す時間(秒)です。これにより、特定のセグメントが音声ファイルのどの部分に対応しているかを知ることができます。
start: セグメントの開始時間(秒)です。これは、トランスクリプションされたテキストが音声ファイル内で開始される具体的な時点を示します。
end: セグメントの終了時間(秒)です。これは、トランスクリプションされたテキストが音声ファイル内で終了する具体的な時点を示します。
text: トランスクリプションされたテキストの内容です。これは、音声ファイルの特定のセグメントから抽出されたテキストを表します。
tokens: トランスクリプションプロセス中に使用された内部的なトークンまたは単語の識別子のリストです。これらは、テキストを生成するためにシステムが内部で使用する符号化された単語やフレーズを表します。
temperature: モデルがテキストを生成する際に使用される「温度」パラメータです。これは、生成プロセスのランダム性を制御し、通常、より高い値でより多様なテキストが生成されます。0に設定されている場合、最も確実性の高い結果が選択されます。
avg_logprob: セグメントの平均ログ確率です。これは、モデルが生成した各トークンの確信度の平均を示し、トランスクリプションの信頼度の指標となります。値が高いほど、モデルがそのトランスクリプションの正確性に自信を持っていることを示します。
compression_ratio: 音声の圧縮比を示します。これは、元の音声データとトランスクリプションされたテキストとの間のデータ量の比率を表し、トランスクリプションによってどの程度音声データが「圧縮」されたかを示します。
no_speech_prob: 「無音声」の確率を示します。これは、モデルがそのセグメントを無音声(つまり、話されている言葉がない部分)と判断する確率を示し、音声活動の検出に関連する信頼度を反映します。
終わりに
ワードレベルで文字起こしされると、より細かな開始/終了時刻がわかるので、字幕付けなど色々な用途でより高品質なアプローチができる気がします。
OSS Whisperにはありましたが、APIの方でもサポートしてもらえるのは嬉しいですね!使い倒していきたいと思います!