
Photo by
moriniko
Pythonコードの復習(3) - Tensorflow + Keras、ニューラルネットワークを用いた2値分類

今回は、機械学習の基礎であるニューラルネットを用いた2値分類について学習をしてみました。
E検定の学習と「Tensorflow2 プログラミング実装ハンドブック」という本を参考に、正規分布に従うクラスターを2つに分類するという簡単な問題に挑戦してみます。
モデルの考案
順伝播・逆伝播ができるニューラルネットをTensorflow・Kerasを用いて実装します。訓練・テストに用いるデータの分割、およびミニバッチに用いるデータのシャッフルにはSKlearnのメソッドを使います。
ニューラルネットの実装
#tensorflowのバックエンドとしてkerasを用いる
#訓練・テストデータの分割にはsklearnを用いる
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import optimizers
import seaborn as snsimport keras
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle#乱数シードの固定
np.random.seed(123)
#入力データの次元数とクラスごとのデータ数
input_dim = 2
n = 500
#正規分布に座標の値を足したデータセットを作り、クラスターとする
x1 = np.random.randn(n, input_dim) + np.array([3,2])
x2 = np.random.randn(n, input_dim) + np.array([7,6])
#正解ラベルを作成。Tensorflowの場合、正解ラベルは2階テンソルの形にする必要がある
t1 = np.array([[0] for i in range(n)])
t2 = np.array([[1] for i in range(n)])
#説明変数と目的変数を作成。x1とx2、t1とt2と行方向に結合する
x = np.concatenate((x1, x2), axis = 0)
t = np.concatenate((t1, t2), axis = 0)
#float64をfloat32に変換する
x = x.astype("float32")
t = t.astype("float32")
print("x's shape:", x.shape)
print("t's shape:", t.shape)
#Pandasによる視覚化。最初・最後の数行がどのような構造かを確認する
df = pd.DataFrame(x)
df["Classified"] = t
df.head(10)
#Seabornによる視覚化。説明変数と目的関数の相関を視覚化できる
sns.pairplot(df)
plt.show()

個人的に、Pandas・Seabornの機能を用いて説明変数と目的関数の相関を視覚化するのがデータの事前処理をする際に役立つと考えています。今回は正規化・次元圧縮などの処理は行わず、シンプル分類だけをしたい場合に集中しています。
学習を開始
隠れ層・出力層の活性化関数はシグモイド、最適化関数はSGD、損失関数は2値クロスエントロピー、評価指標にはテストデータと予測値を比較した精度を使用してます。活性化関数や最適化関数、またノードのウェイトの初期値を変更することで学習の精度を高めるので、次回はそれらに関しても検証していきたいと思います。
#モデルの構築。後にウェイト・バイアスに適切な初期化をした場合なども検証する
model = Sequential()
#隠れ層、出力層のユニット数と活性化関数を定義
model.add(Dense(2, activation = "sigmoid"))
model.add(Dense(1, activation = "sigmoid"))
#最適化関数はSGD。あとでADAMを用いる場合も検証する
optimizer = optimizers.SGD(learning_rate=0.1)
#モデルを実装。最適化関数、損失関数、評価指標を順に指定する
model.compile(optimizer = optimizer, loss = "binary_crossentropy", metrics = ["accuracy"])
#エポック数
epoch = 100
#訓練用データ、テスト用データに分割する
x_train, x_test, t_train, t_test = train_test_split(x, t, test_size = 0.2)#学習を行う
history = model.fit( x_train, t_train, epochs = epoch, batch_size = 32, verbose=1, validation_data = (x_test, t_test))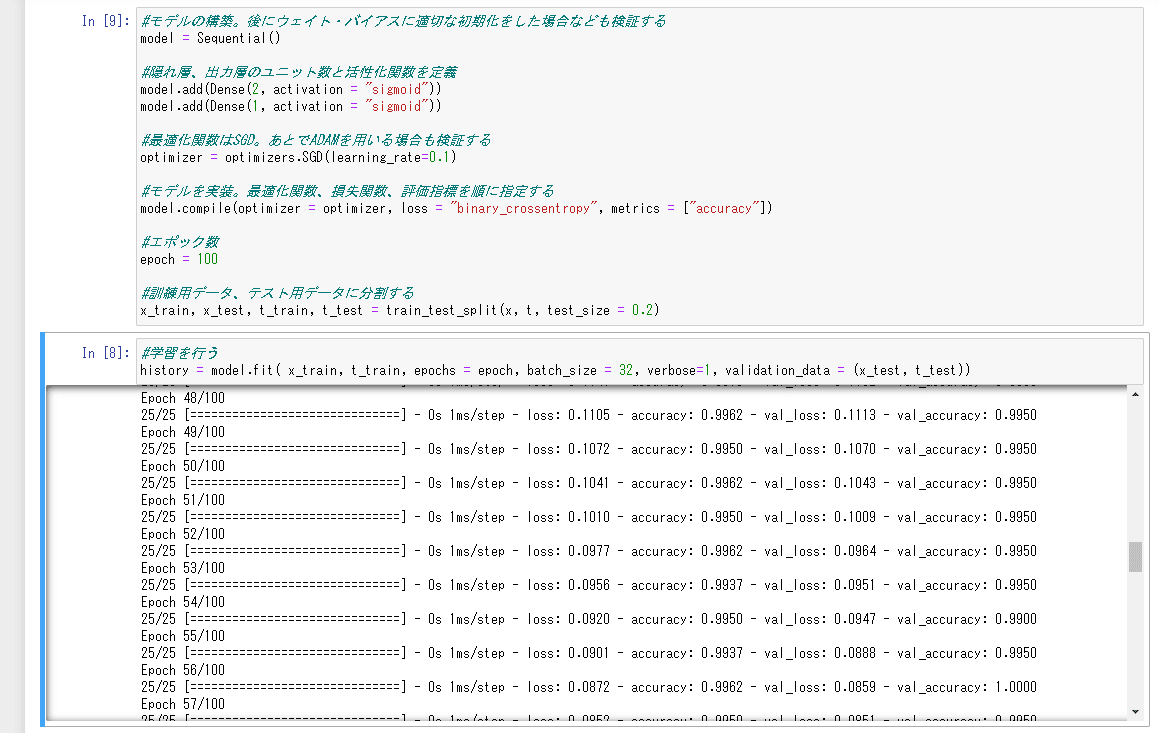
データ数が1000、バッチ数が32ほどのデータで50回学習するだけでほぼ100%の訓練性能が出ます。ニューラルネットを使うと、SVM・K近傍法などよりも手っ取り早く、正確なモデルを作ることができるという一例です。
次回はTensorflow + Kerasを用いて多値分類をする場合を、またデータの整形や欠損値を補う方法などについても考案していきたいと思います。ありがとうございました!