
DeepSeek-R1をざっくり理解する

※この記事は15分で読めます。
こんにちは!猫四郎です🐾
今回は、中国のAI企業DeepSeekが開発した「DeepSeek-R1」について、僕も使いながら勉強しているので皆さんにもシェアします。
①DeepSeek-R1の概要
DeepSeek-R1は、論理的推論・数学的問題解決・リアルタイムでの意思決定に特化したAIモデルです。簡単にいうと、従来の汎用的な大規模言語モデル(LLM)とは異なり、「推論」に重点を置いて開発されており、その結果、リソースの効率的な配分とモデル全体の最適化が実現され、OpenAIのo1と同等レベルの性能を持っています。

両者とも得意不得意あるようですが、まあほぼ一緒ですね。
②DeepSeek-R1の特徴
次に、特徴についてポイントを押さえながら解説していきたいと思います。
1. 推論モデルとしての特性
DeepSeek R1は、ただ結果を出すだけじゃなく、「どうやってその結論に至ったのか」を明確に示してくれます。特に活躍するのが、研究や複雑な意思決定が必要な場面。例えば、論文執筆やビジネス戦略の立案など、結果の説明責任が大事なケースで使えそうですね。
2. 高い推論能力
DeepSeek R1の推論能力はo1同様、とにかく優れています。
反射や自己検証が可能で、思考連鎖(Chain of Thought; CoT)という手法で、複雑な問題を段階的に解決してくれます。
3. 革新的な学習のアプローチ
DeepSeek R1は、通常の教師ありファインチューニング(SFT)を極力使わず、強化学習(RL)をメインにトレーニングされています。
4. 完全オープンソース
DeepSeek R1はMITライセンスの下でオープンソース化されています。
つまり、研究者や開発者が自由に利用・改良・商用利用することが可能ということです。
5. "コスパ" 最強
DeepSeek R1はAPIアクセスのコストはかなり安いです。
・入力トークン100万件あたり:キャッシュヒット時は0.14ドル、キャッシュミス時は0.55ドル
・出力トークン100万件あたり:2.19ドル
(https://api-docs.deepseek.com/guides/reasoning_model)
これ、OpenAIのo1と比べるとかなり安くて、ここが世間を驚かせた1つの要素ではないかと思います。
個人でAI開発するハードルがぐんと下がりましたね。
今の所、"コスパ" は最強です。
③DeepSeek-R1-ZeroからDeepSeek-R1への進化
先ほどの特徴で伝えたDeepSeek-R1-Zeroは、DeepSeek-R1の開発前に教師ありファインチューニング(SFT)なしで、強化学習(RL)のみでトレーニングされた前段階の推論モデルです。
このモデルは、従来の言語モデルとは異なり、結論に至るまでのプロセスを明確に示すことができる「推論モデル」ということで非常に優れています。
ただ、このモデルは「可読性が低い」「自然言語(日本語や英語、中国語など)の混在」「一生出力が繰り返される」などの割と重大な欠点がありました。
DeepSeek-R1は、このDeepSeek-R1-Zero(SFTなしのモデル)をベースに、直接的にコールドスタートフェーズや多段階の強化学習を適用させることで、人間が用意した大量のデータを必要とせず、推論能力を効率良く上げることに成功しています。
④DeepSeek-R1の蒸留モデル
はい。ということで、DeepSeek-R1について推論に優れた大規模なモデルとして理解したところで、蒸留モデルについて理解します。
そもそも蒸留モデルって何なん?
そんな方に簡単に説明しますね。
蒸留モデルは、元の大きなモデルをただ凝縮しているだけで、大きくて複雑なAIモデルの知識を、小さくて軽いモデルに移す技術です。これによって、生徒モデルは教師モデルに近い性能を保ちながら、計算にかかるコストを大幅に減らせます。
特に、スマホや小型デバイス(IoT)など、使えるリソースが限られた環境で役立つ技術です。
(詳細はこちらのサイトで解説してくれているので興味ある人はどうぞ)
DeepSeek-R1の計算コストはデカいのよ
DeepSeek-R1は、非常に大きなモデル(6710億パラメータ)であり、高い推論能力を持つ一方で、実行には多くの計算資源を必要とします。そこで役立つのが、上記で説明した「蒸留モデル」です。
小さなモデルとして計算コストを大幅削減し、元の性能と同等レベルを維持してくれています。
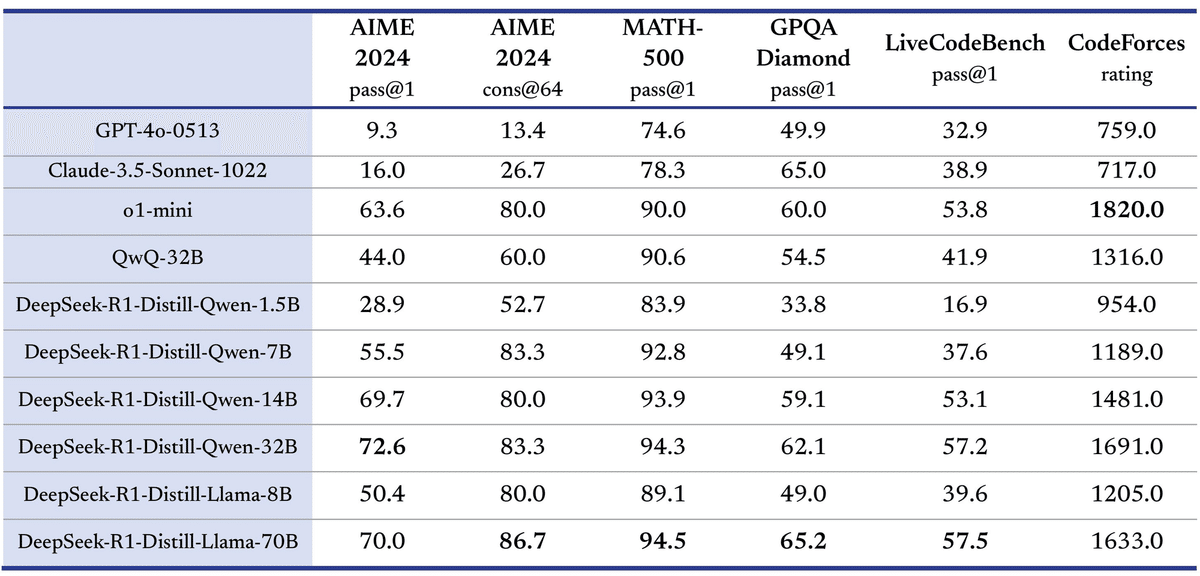
DeepSeek-R1の6つの蒸留モデル
DeepSeekは、この技術を用いてDeepSeek-R1の推論能力を継承した、6つの小型蒸留モデルを公開してくれています。
Qwenベースの蒸留モデル(4つ)
1. deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
2. deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
3. deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
4. deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
Llamaベースの蒸留モデル(2つ)
5. deepseek-ai/DeepSeek-R1-Distill-Llama-70B
6. deepseek-ai/DeepSeek-R1-Distill-Llama-8B
Qwenは、中国のAI企業であるQWENが開発したオープンソースの大規模言語モデルです。
Llamaは、Meta AIが開発したオープンソースの大規模言語モデルです。
上記それぞれのモデルによって、サイズや性能が違うので、用途に合わせて選べます。例えば、4つ目のDeepSeek-R1-Distill-Qwen-1.5Bは小型で、家庭用PCでも動きます。一方、5つめのDeepSeek-R1-Distill-Llama-70Bは高性能で、OpenAIのo1-miniに匹敵する性能らしいです。
⑤まとめ
はい。DeepSeek-R1についてまとめました。
DeepSeek-R1はオープンソースであること、料金が安いこと、o1同等の性能があることなど、様々なメリットがありましたね。
ただし、使用上の注意点もあります。
まだまだ発展途上のモデルということもありますし、オプトアウト設定がないため、API経由でも入力データが学習されてしまいます。(要は入力データが世界中にばら撒かれます)
なので、もし個人データなどを扱う場合は、ローカルに落としてから使うようにするべきですね。
このように、高性能だが料金が安いモデルには欠点もありますので、注意しましょう。
ここまで読んでいただきありがとうございました。
今回は中級者さん向けでした🐾