
NVIDIA CEO ジェンセン・ファン基調講演 at CES 2025(2025/1/6)

【オープニング】
皆様、CES 2025へようこそ。
私はゲイリー・シャピロ、Consumer Technology Associationのプロデューサーであり、CEOおよび副会長です。
世界で最も重要な企業の1つによる基調講演でこのショーを開始できることを大変嬉しく思います。
NVIDIAはCESで祝福される最先端のイノベーションを体現しています。
創業者兼CEOのジェンセン・ファンは真のビジョナリーであり、アイデア、テクノロジー、そして確信の力で、私たちの業界と社会を変革するイノベーションを推進することを実証しています。
私はいつも言っていますが、前回ジェンセンがCTAのイベントで話したときに、もう少し注意深く聞いていれば、すでに引退できていたかもしれません。
しかし過去30年間で、彼はヘルスケアから自動車、エンターテインメントまで、世界中のさまざまな産業で変革を推進するNVIDIAを確立しました。
今日、NVIDIAはほぼ全ての人々とビジネスに影響を与えるAIと加速コンピューティングにおけるブレークスルーを開拓しています。
彼のリーダーシップのおかげで、NVIDIAのイノベーションは高度なチャットボット、ロボット、ソフトウェア定義の車両、巨大な仮想世界、超同期化された工場フロアなど、さまざまなものを可能にしています。
ファンはFortuneとThe Economistによって世界最高のCEOに選ばれ、Time誌の世界で最も影響力のある100人にも選ばれています。
しかし、この部屋にいる私たち全員と同様に、彼の成功は運命づけられたものではありませんでした。
ジェンセンはデニーズで皿洗いとバスボーイとして働き始めました。だから、将来出会う彼らには親切にしてください。
彼が言うには、そこで学んだ勤勉さ、謙虚さ、おもてなしの価値観が、NVIDIAの初期の課題を乗り越える際の信念を保ち続けるのに役立ったそうです。
まもなく、NVIDIA創業者兼CEOのジェンセン・ファンから、揺るぎない未来へのビジョンと、私たちが次にどこへ向かうのかについて聞くことになります。
引き続きお楽しみください。素晴らしいCESになりますように!
【ジェンセン・ファン基調講演】
[拍手]
ステージへようこそ、NVIDIA創業者兼CEOのジェンセン・ファン!
[拍手]
CESへようこそ!
[拍手]
ラスベガスに来て興奮していますか?
[拍手]

私のジャケットは気に入りましたか?
[拍手]
ゲイリー・シャピロとは違う方向に行ってみようと思いました。
[笑い]
結局のところ、ここはラスベガスですから。
もしこれがうまくいかなかったら、もし皆さんが反対するなら、まあ慣れてください。
本当に、これを受け入れる必要があると思います。
[笑い]
あと1時間ほどすれば、気分が良くなるでしょう。
[笑い]
では、NVIDIAへようこそ。
実は、皆さんはNVIDIAのデジタルツインの中にいます。
NVIDIAへご案内しましょう。
皆様、NVIDIAへようこそ。
[拍手]
皆さんは私たちのデジタルツインの中にいます。
[拍手]
ここにあるものは全てAIによって生成されています。
これは驚くべき旅路であり、驚くべき年でした。
そして、それは1993年に始まりました。
レディ?、スタート!

NV1で、私たちは通常のコンピュータにはできないことができるコンピュータを作りたいと考えました。
NV1はPCでゲームコンソールを実現することを可能にしました。
私たちのプログラミングアーキテクチャはUDAと呼ばれていました。
しばらくの間、文字Cには触れませんでした。
しかしUDA、Unified Device Architectureです。
そしてUDAの最初の開発者、UDAで動作した最初のアプリケーションは、セガのバーチャファイターでした。
6年後の1999年、私たちはプログラマブルGPUを発明しました。
そしてそれは、このGPUと呼ばれる驚くべきプロセッサの20年以上にわたる信じられない進歩の始まりとなりました。
それは現代のコンピュータグラフィックスを可能にしました。
そして今、30年後、セガのバーチャファイターは完全にシネマティックになっています。

これは発売予定の新しいバーチャファイタープロジェクトです。
本当に待ちきれません。
絶対に信じられないほど素晴らしいです。
その6年後、1999年の6年後、私たちはCUDAを発明しました。

これは、私たちのGPUのプログラマビリティを、それから恩恵を受けることができる豊富なアルゴリズムセットに説明または表現できるようにするためでした。
CUDAは当初、説明が難しかったです。
実際、それには数年かかりました。
約6年かかりました。
なぜか、6年後、あるいはその頃、2012年に、アレックス・クリシェフスキー、イリヤ・サスコヴァー、ジェフ・ヒントンがCUDAを発見し、AlexNetの処理に使用し、残りは歴史となりました。

それ以来、AIは信じられないペースで進歩しています。
知覚AIから始まりました。
今では画像や言葉、音を理解できます。
生成AI。
画像やテキスト、音を生成できます。
そして今、エージェントAI。
知覚し、推論し、計画し、行動できるAIです。
そして次のフェーズ、その一部を今夜お話しする物理AIは、2012年です。
そして魔法のように、2018年に何かが起こりました。
それは本当に信じられないものでした。
GoogleのTransformerがBERTとしてリリースされ、AIの世界は本当に飛躍的に発展しました。
ご存知の通り、Transformerは人工知能の風景を完全に変えました。

実際、コンピューティング全体の風景を完全に変えました。
私たちは、AIが単なる新しいアプリケーションや新しいビジネスチャンスではないと適切に認識しました。
より重要なことに、Transformerによって可能になった機械学習は、コンピューティングの仕組みを根本的に変えようとしていました。
そして今日、コンピューティングはあらゆる層で革命を起こしています。
CPUで実行される命令を手でコーディングし、人間が使用するソフトウェアツールを作成することから、機械学習がGPUで処理される神経ネットワークを作成・最適化し、人工知能を生み出すようになりました。
テクノロジースタックのあらゆる層が完全に変更されました。
わずか12年でのまさに信じられない変革です。
現在、私たちはほぼあらゆるモダリティの情報を理解することができます。
確かに、テキストや画像、音などを見てきましたが、それらを理解できるだけでなく、アミノ酸や物理学も理解できます。
私たちはそれらを理解し、翻訳し、生成することができます。
アプリケーションは本当に無限です。
実際、あなたが目にするほぼ全てのAIアプリケーションで、どのモダリティが入力として学習されたのか、どのモダリティの情報に翻訳されたのか、そしてどのモダリティの情報を生成しているのか、これら3つの基本的な質問をすれば、ほぼ全てのアプリケーションを推測することができます。
そして、AIドリブン、AIネイティブのアプリケーションを次々と目にするとき、その核心にはこの基本的な概念があるのです。
機械学習は、全てのアプリケーションがどのように構築され、コンピューティングがどのように行われ、その先の可能性がどうなるかを変えました。
さて、GPUとGeForceは、多くの意味でAIを構築した家です。
GeForceはAIを大衆に届け、そして今AIはGeForceに戻ってきています。
AIなしではできないことがたくさんあります。
いくつかをお見せしましょう。
[ビデオ再生]

これはリアルタイムのコンピュータグラフィックスでした。
[拍手]
コンピュータグラフィックス研究者も、コンピュータ科学者も、この時点で全てのピクセルをレイトレーシングすることが可能だとは誰も言わなかったでしょう。
レイトレーシングは光のシミュレーションです。
あなたが見たジオメトリの量は本当に常識外れでした。
人工知能なしでは不可能だったでしょう。
私たちが行った基本的なことが2つあります。
もちろん、プログラマブルシェーディングとレイトレース加速を使用して、信じられないほど美しいピクセルを生成しました。
しかし、そのピクセルによって制御された人工知能を使用して、他の大量のピクセルを生成しました。
空間的に他のピクセルを生成できるだけでなく、色がどうあるべきかを認識しているため、NVIDIAのスーパーコンピュータで訓練され、GPUで実行される神経ネットワークは、私たちがレンダリングしなかったピクセルを推論し、予測することができます。
それだけでなく、DLSSと呼ばれる最新世代のDLSSは、フレームを超えて生成することもできます。
将来を予測し、計算したフレームごとに3つの追加フレームを生成できます。
あなたが見たもの、私たちが4フレームと言ったとすると、1フレームをレンダリングして3フレームを生成するので、フルHD、4Kで4フレームとすると、それは約3,300万ピクセルです。
その3,300万ピクセルのうち、私たちが計算したのはわずか200万プログラマブルシェーダーとレイトレーシングエンジンを使用して200万ピクセルを計算し、AIに他の3,300万のピクセルを予測させることができるというのは、絶対的な奇跡です。
結果として、AIははるかに少ない計算で処理を行うため、信じられないほど高いパフォーマンスでレンダリングすることができます。
もちろん、それを訓練するには膨大な量の処理が必要ですが、一度訓練すれば、生成は非常に効率的です。
これが人工知能の信じられない能力の一つであり、だからこそ多くの驚くべきことが起こっているのです。
私たちはGeForceを使って人工知能を実現し、そして今、人工知能がGeForceを革新しています。
皆さん、本日、次世代のRTX Blackwellファミリーを発表します。
ご覧ください。
[音楽]


[拍手]
これが私たちの新しいGeForce RTX 50シリーズBlackwellアーキテクチャです。
このGPUは本当に化け物です。
920億トランジスタ、4,000 TOPS、4ペタフロップスのAI性能を持ち、前世代の3倍高速です。AIDAAと私たちは、先ほどお見せしたようなピクセルを生成するために、これら全てを必要としています。

380レイトレーシングテラフロップスにより、計算が必要なピクセルに対して、可能な限り美しい画像を計算することができます。
そしてもちろん、125シェーダーテラフロップスです。
実際には同時実行シェーダーテラフロップスと、同等のパフォーマンスを持つ整数ユニットもあります。
つまり、2つのデュアルシェーダーです。
一つは浮動小数点用、もう一つは整数用です。
Micronのオンボードメモリ、1.8テラバイト/秒、前世代の2倍のパフォーマンスを実現し、AIワークロードとコンピュータグラフィックスワークロードを混在させる能力を持っています。
この世代の素晴らしい点の一つは、プログラマブルシェーダーが神経ネットワークを処理できるようになったことです。
シェーダーはこれらの神経ネットワークを実行できるようになり、その結果、ニューラルテクスチャ圧縮とニューラルマテリアルシェーディングを発明しました。
その結果、AIを使用してテクスチャを学習し、圧縮アルゴリズムを学習することで、驚くべき結果を得ることができます。
これが新しいRTX Blackwell 50-Millionです。
機械設計さえも奇跡です。
ご覧ください、2つのファンがあります。
このグラフィックスカード全体が一つの巨大なファンです。
そうですね、では質問です。グラフィックスカードはどこにあるのでしょうか?

本当にこれほど大きいのでしょうか?
電圧レギュレータの設計は最先端で、信じられないデザインです。
エンジニアリングチームは素晴らしい仕事をしました。
はい、これです。ありがとうございます。
それでは、スペックと性能を見ていきましょう。
これがRTX 4090です。はい、多くの方が持っていることは知っています。

分かっています。1,599ドルです。
これは可能な限り最高の投資の一つです。
1,599ドルで、あなたの1万ドルのPCエンターテインメントコマンドセンターに持ち帰ることができます。
そうですよね?
違うと言わないでください。
恥ずかしがる必要はありません。
液冷で、あちこちに派手なライトが付いています。
外出するときはロックします。
これが現代のホームシアターです。
完全に理にかなっています。
そして今、1,599ドルで、アップグレードして思う存分ターボチャージすることができます。

さて、Blackwellファミリーでは、RTX 5070が4090のパフォーマンスを549ドルで実現します。
人工知能なしでは不可能でした。
4テラオプスのAIテンソルコアなしでは不可能でした。
G7メモリなしでは不可能でした。
はい、5070は4090のパフォーマンスを549ドルで、そしてこれがファミリー全体です。

5070から5090まで、5090は4090の2倍のパフォーマンスです。
もちろん、1月から大規模な生産を開始し、入手可能になります。
素晴らしいことに、これらの巨大なパフォーマンスを持つGPUをラップトップに搭載することができました。
これは5070ラップトップです。

1,299ドルで、この5070ラップトップは4090のパフォーマンスを持っています。
ここにあるものを見せましょう。
これは - これを見てください。
ここで - ここです。
ポケットはそれほど多くありません。
皆様、ジャニーン・ポールです。
想像できますか?
ここにこの信じられないグラフィックスカード、Blackwellがあります。

これを縮小してそこに入れるのです。
それは理にかなっていますか?
人工知能なしではできません。その理由は、テンソルコアを使用して大部分のピクセルを生成しているからです。
必要なピクセルだけをレイトレースし、人工知能を使用して他の全てのピクセルを生成しています。
その結果、エネルギー効率は信じられないほど高くなっています。
コンピュータグラフィックスの未来はニューラルレンダリング、人工知能とコンピュータグラフィックスの融合です。
本当に驚くべきことは - ああ、ここにあります。
ありがとうございます。
これは予想外に動きのある基調講演です。
そして本当に驚くべきことは、ここに搭載するGPUファミリーです。
5090は薄型ラップトップに搭載されます。最後のラップトップは14.9ミリメートルでした。

5080、5070 Ti、5070があります。
いかがでしょうか?
皆様、RTX Blackwellファミリーです。

GeForceはAIを世界にもたらし、AIを民主化しました。
今、AIが戻ってきてGeForceを革新しています。
人工知能について話しましょう。
NVIDIAの別の場所に移動しましょう。
これは文字通り私たちのオフィスです。
これは文字通り NVIDIAの本社です。
では、AIについて話しましょう。
業界はAIのスケーリングを追求し、競争しています。
スケーリング則は強力なモデルです。
これは研究者や産業界が数世代にわたって観察し、実証してきた経験則です。
スケーリング則によると、より多くのデータ、つまり学習データを持ち、より大きなモデルを持ち、より多くの計算能力を適用すると、モデルはより効果的に、より有能になります。

そしてスケーリング則は続いています。
本当に驚くべきことは、今では - もちろん、インターネットは毎年、前年の約2倍のデータを生成しています。
今後数年で、人類は - 人類は人類の始まりから今までに生成された全てのデータよりも多くのデータを生成すると思います。
そして私たちは依然として巨大な量のデータを生成しており、それはマルチモーダルになってきています。
ビデオや画像、音声、これら全てのデータは、AIの基礎的な知識、基礎的な知識を訓練するために使用できます。
しかし、実際には2つの新しいスケーリング則が登場しています。

それはある意味で直感的です。
2番目のスケーリング則は、訓練後のスケーリング則です。
訓練後のスケーリング則は、強化学習やヒューマンフィードバックのような技術を使用します。
基本的に、AIは人間のクエリに基づいて答えを生成します。
人間はもちろん、フィードバックを与えます。
それはそれよりもはるかに複雑ですが、その強化学習システムは、かなりの数の高品質なプロンプトによって、AIにスキルを洗練させます。
特定のドメインに対してスキルを微調整することができ、数学の問題をより良く解くことができ、推論がより良くなり、等々です。
本質的には、学校を卒業した後にメンターやコーチからフィードバックを受けるようなものです。
そしてテストを受け、フィードバックを受け、自分自身を改善します。
また、AI フィードバックの強化学習や、合成データ生成もあります。
これらの技術は、いわば自己練習のようなものです。
特定の問題の答えを知っており、正解するまで継続的に試します。
そしてAIは、機能的に検証可能で答えが理解できる非常に複雑で難しい問題、例えば定理の証明や幾何学的問題の解決などに直面することができます。
これらの問題によってAIは答えを生成し、強化学習を使用して自己改善の方法を学びます。
これが訓練後と呼ばれるものです。
訓練後には膨大な量の計算が必要ですが、最終的には信じられないモデルを生成します。
現在、私たちは3番目のスケーリング則を持っており、このスケーリング則はテスト時のスケーリングと呼ばれるものに関係しています。
テスト時のスケーリングは基本的に、使用されているとき、AIを使用しているときのことです。
AIは異なるリソース配分を適用する能力を持っています。
パラメータを改善する代わりに、今度は生成したい答えを生成するためにどれだけの計算を使用するかを決定することに焦点を当てています。
推論はこれについて考える一つの方法です。
長時間の思考はこれについて考える一つの方法です。
直接的な推論やワンショットの答えの代わりに、推論するかもしれません。
問題を複数のステップに分解するかもしれません。
複数のアイデアを生成し、生成したアイデアのうちどれが最良かをAIシステムが評価するかもしれません。
おそらく段階的に問題を解決し、等々です。
そして今、テスト時のスケーリングは信じられないほど効果的であることが証明されています。
ChatGPTから01、03、そして今のGemini Proまで、信じられない成果を見ながら、この技術の流れと、これら全てのスケーリング則が登場するのを目にしています。
これらのシステムは全て、事前訓練から訓練後、テスト時のスケーリングへと、段階的にこの旅を進んでいます。
もちろん、私たちが必要とする計算量は信じられないほどです。
実際、私たちは社会が新しいより良い知能を生成するために計算量をスケールアップする能力を持つことを望んでいます。
もちろん、知能は私たちが持つ最も価値のある資産であり、多くの困難な問題を解決するために適用することができます。
そしてスケーリング則は、NVIDIA のコンピューティングに対する膨大な需要を生み出しています。
この信じられないチップ、Blackwellに対する膨大な需要を生み出しています。
Blackwellについて見てみましょう。
Blackwellは本格的な生産に入っています。
それがどのようなものか、本当に信じられないものです。
まず、すべてのクラウドサービスプロバイダーが今やシステムを稼働させています。

ここには約15、15、申し訳ありません、15のコンピュータメーカーからのシステムがあります。
約200の異なるSKU、200の異なる構成で製造されています。
液冷、空冷、x86、NVIDIA Gray CPUバージョン、MVLink 36×2、MVLink 72×1など、世界中のほぼすべてのデータセンターに対応できるように、さまざまなタイプのシステムがあります。
これらのシステムは現在、45の工場で製造されています。
人工知能がいかに普及し、業界がいかに人工知能とこの新しいコンピューティングモデルに飛びついているかを示しています。
私たちがこれほど強力に推進している理由は、より多くの計算能力が必要だからです。
そして、それは非常に明確です。ジャニーン、分かりますよね。
暗い場所に手を伸ばすのは良くないですよね。
これは良いアイデアですか?

待ってください。待ってください。
私は価値があると思いましたが。
明らかにヨニールはそう思っていませんでした。
よし。
これは私のショー・アンド・テルです。
これはショー・アンド・テルです。

このMVLinkシステム、ここにあるこのMVLinkシステム、これはGB200、MVLink 72です。
これは1.5トン、60万個のパーツ、約20台の車に相当し、120キロワットです。
背後にはすべてのGPUを接続するスパインがあり、2マイルの銅ケーブル、5,000本のケーブルがあります。
これは世界中の45の工場で製造されています。
私たちはそれらを構築し、液冷し、テストし、分解して、1.5トンもあるため、部品をデータセンターに出荷します。
データセンターの外で再組み立てし、設置します。
製造は本当に常識外れです。
しかし、これら全ての目的は、スケーリング則が計算をとても強く推進しているため、この計算レベルで、Blackwellは前世代と比べてワット当たりの性能を4倍向上させています。
ワット当たりの性能が4倍、ドル当たりの性能が3倍です。
これは基本的に、1世代で、これらのモデルの訓練コストを3分の1に削減したということです。
または、モデルのサイズを3倍に増やしたい場合でも、コストはほぼ同じです。
しかし重要なのはこれです。
これらは、私たちがChatGPTやGeminiを使用するとき、将来的には携帯電話を使用するときに、私たち全員が使用するトークンを生成しています。
これらのアプリケーションのほぼすべてが、これらのAIトークンを消費することになります。
そしてこれらのAIトークンは、これらのシステムによって生成されています。
そしてすべてのデータセンターは電力によって制限されています。
そしてBlackwellのワット当たりの性能が前世代の4倍であれば、データセンターで生成できる収益、生成できるビジネスの量は4倍に増加します。
そしてこれらのAIファクトリーシステムは、今日では本当にファクトリーなのです。
これら全ての目的は、1つの巨大なチップを作ることです。
私たちが必要とする計算量は本当に信じられないほどです。
これは基本的に1つの巨大なチップです。
もし私たちがこれを1つのチップとして作らなければならなかったとしたら、明らかにこれはウェーハのサイズになるでしょう。

ご覧ください。
そのクールさが分かりますか。
ディスコライトがここにあります。
これを1つのチップとして作らなければならなかったとしたら、歩留まりの影響は含まれていません。
おそらく3倍か4倍のサイズになるでしょう。
しかし、基本的に私たちがここで持っているのは、72個のBlackwell GPUまたは144個のダイです。

このチップは1.4エクサフロップスです。
世界最大のスーパーコンピュータ、最速のスーパーコンピュータは、つい最近 - この部屋全体のスーパーコンピュータ - つい最近1エクサフロップス以上を達成しました。
これは1.4エクサフロップスのAI浮動小数点演算性能です。
14テラバイトのメモリを搭載しています。
しかし、驚くべきことは次のことです。
メモリ帯域幅は毎秒1.2ペタバイトです。
これは基本的に、今この瞬間に発生している全インターネットトラフィックに相当します。
世界中の全インターネットトラフィックがこれらのチップを通じて処理されています。
分かりますよね?
そして私たちは合計で130兆個のトランジスタ、2,592個のCPUコア、大量のネットワーキングを持っています。
そして私はこれができればいいのですが。
できそうにありません。
これらがBlackwellです。
これらは私たちのConnectXネットワーキングチップです。
これらがNVLinkです。
そして私たちはNVLinkスパインについて仮定していますが、それは不可能です。
分かりますよね?
そしてこれらは全てのHBMメモリ、14テラバイトのHBMメモリです。
これが私たちがしようとしていることです。
そしてこれが奇跡です。
これがBlackwellシステムの奇跡です。
ここにあるBlackwellダイです。
これは世界で最も大きな単一チップです。
しかし本当の奇跡は、それに加えて、これがGrace Blackwellシステムだということです。
もちろん、これら全ての目的は -
少し座らせてもらえますか?
ミケロブ ウルトラをいただけますか?
ミケロブ ウルトラスタジアムにいるのはどうしてですか?
NVIDIAに来てGPUがないようなものです。
より大きなモデルを訓練したいので、膨大な計算能力が必要です。
これらの推論は以前は1回の推論でしたが、将来的にはAIは自分自身と対話することになります。
考えることになります。
内部で反省し、処理することになります。
今日、トークンが1秒あたり20または30トークンの速度で生成されている限り、それは基本的に誰もが読める速度です。
しかし将来的には、そして現在でもGPT-01、新しいGemini Pro、新しいG - 01、03モデルでは、彼らは自分自身と対話し、反省しています。
彼らは考えています。
そして想像できるように、トークンを取り込むことができる速度は信じられないほど高くなります。
そのため、トークンレート、トークン生成レートを大幅に上げる必要があります。
また、同時にコストを大幅に下げる必要があります。そうすることで、サービスの品質が非常に高く、顧客のコストを継続的に低く抑えることができ、AIは継続的にスケールアップすることができます。
これが基本的な目的であり、MVLinkを作成した理由です。
エンタープライズの世界で起こっている最も重要なことの1つが、エージェントAIです。

エージェントAIは基本的に時間スケーリングの完璧な例です。
それは - AIはモデルのシステムです。
その一部は理解し、顧客とやり取りし、ユーザーとやり取りします。
一部は情報を取得し、ラグのような意味的AIシステムからストレージから情報を取得するかもしれません。
インターネットにアクセスするかもしれません。PDFファイルを調べるかもしれません。
そしてツールを使用するかもしれません。計算機を使用するかもしれません。
そして生成AIを使用してチャートなどを生成するかもしれません。
そしてそれは反復しています。与えられた問題を段階的に分解し、これらの異なるモデルを通じて反復しています。
将来的に顧客に応答するために、AIが応答するために、以前は質問をして、答えが出力され始めていました。
将来的には質問をすると、大量のモデルがバックグラウンドで動作することになります。
そしてテスト時のスケーリング、推論に使用される計算量は急上昇することになります。
より良い答えが欲しいから、それは急上昇することになります。
エージェントAIの構築を業界が支援するために、私たちのゴートゥーマーケットは企業顧客への直接的なものではありません。

私たちのゴートゥーマーケットは、CUDAライブラリで行ったように、新しい機能を可能にするために私たちの技術を統合するITエコシステムのソフトウェア開発者と協力することです。
今、私たちはそれをAIライブラリで行いたいと考えています。
そして過去のコンピューティングモデルがコンピュータグラフィックスや線形代数や流体力学を行うAPIを持っていたように、将来的には、それらの加速ライブラリ、CUDA加速ライブラリの上に、AIライブラリを持つことになります。
私たちはエージェントAIの構築を支援するためのエコシステムに3つのものを作成しました。
NVIDIA NIMS、これは本質的にパッケージ化されたAIマイクロサービスです。
これは非常に複雑なこれらのCUDAソフトウェア、CUDA DNN、Cutlass、または TensorRTLM、または Tritonなど、これら全ての非常に複雑なソフトウェアとモデル自体を取り、パッケージ化し、最適化し、コンテナに入れ、好きな場所に持っていくことができます。
そして私たちは視覚、言語理解、音声、アニメーション、デジタル生物学のためのモデルを持っており、物理AIのためのいくつかの新しい興味深いモデルも持っています。
これらのAIモデルは、NVIDIAのGPUが現在すべてのクラウドで利用可能なため、すべてのクラウドで実行されます。
すべてのOEMで利用可能です。そのため、これらのモデルを文字通り取り、ソフトウェアパッケージに統合し、Cadenceで実行されるAIエージェントを作成するか、それらはServiceNowエージェントかもしれませんし、SAPエージェントかもしれません。
そして顧客が望む場所でソフトウェアを実行できるように、顧客に展開することができます。
次のレイヤーは、私たちがNVIDIA NEMOと呼ぶものです。
NEMOは本質的にデジタル従業員のオンボーディングと訓練評価システムです。
将来的に、これらのAIエージェントは本質的に、あなたの従業員と共に働く、あなたに代わって物事を行うデジタルワークフォースです。
そしてこれらの専門化されたエージェントを会社に導入する方法は、従業員をオンボーディングするのと同じように、オンボーディングすることです。
そのため、私たちは異なるライブラリを持っており、これらのAIエージェントがあなたの会社の言語のタイプに対して訓練されるのを支援します。
おそらく語彙は会社独自のものです。ビジネスプロセスは異なります。働き方が異なります。

そのため、作業成果物がどのようなものであるべきかの例を与え、彼らはそれを生成しようとし、あなたはフィードバックを与え、そして評価します。
そしてガードレールを設定します。「これらは許可されていないこと。これらは言ってはいけないこと」と言います。
そして特定の情報へのアクセスも与えます。
そのため、そのデジタル従業員パイプライン全体がNEMOと呼ばれています。
多くの意味で、すべての企業のIT部門は、将来的にはAIエージェントのHR部門になることでしょう。
今日、彼らはIT業界からの大量のソフトウェアを管理・保守しています。
将来的には、大量のデジタルエージェントを維持し、育成し、オンボーディングし、改善し、企業が使用するためにプロビジョニングします。
そしてあなたのIT部門は、いわばAIエージェントのHRのようになります。
その上に、私たちはエコシステムが活用できる多くのブループリントを提供しています。
これらはすべて完全にオープンソースであり、皆さんはブループリントを取得して修正することができます。
私たちはさまざまな種類のエージェント向けのブループリントを持っています。
本日、私たちは本当にクールで、私が思うに本当に賢明なことを発表します。

NVIDIA LAMA Nemotron言語基盤モデルに基づく、全く新しいモデルファミリーを発表します。
LAMA 3.1は完全な現象です。
Metaからの LAMA 3.1のダウンロード数は65万回ほどで、約6万の異なるモデルに派生され、変換されています。
これは、ほぼすべての企業とすべての業界がAIの取り組みを開始する理由となった単一の要因です。
私たちが気付いたことは、LAMAモデルは企業での使用のためにより良く微調整できるということでした。
そこで、私たちの専門知識と能力を使用して微調整を行い、LAMA Nemotronオープンモデルスイートに変換しました。
非常に高速なレスポンスタイムで対話する小規模なものがあります。
私たちが「LAMA Nemotronスーパー」と呼ぶものです。
基本的に、モデルのメインストリームバージョンやウルトラモデルです。
ウルトラモデルは、多くの他のモデルの教師モデルとして使用できます。
他のモデルが答えを作成し、それが良い答えかどうかを判断する、基本的に他のモデルにフィードバックを与える報酬モデル、評価者、ジャッジとなります。
多くの異なる方法で蒸留できます。基本的に教師モデル、知識蒸留モデル、非常に大規模で有能なモデルです。
これらすべてが現在オンラインで利用可能です。
これらのモデルは信じられないものです。
チャット、指示、検索のリーダーボードで1位です。
世界中のAIエージェントで必要とされる異なる種類の機能に対して、これらは信じられないモデルになるでしょう。

私たちはエコシステムとも協力しています。
私たちのNVIDIA AIテクノロジーはすべてIT業界に統合されています。
ServiceNow、SAP、産業用AIのSiemensなど、素晴らしいパートナーがいて、本当に素晴らしい仕事が行われています。
Cadenceは素晴らしい仕事をしています。
Synopsisは素晴らしい仕事をしています。
Perplexityと行っている仕事を本当に誇りに思います。
ご存知の通り、彼らは検索を革新しました。
本当に素晴らしいものです。
Codium、世界中のすべてのソフトウェアエンジニア、これが次の巨大なAIアプリケーション、次の巨大なAIサービスになります。ソフトウェアコーディングです。
世界中に3,000万人のソフトウェアエンジニアがいて、誰もがコーディングを支援するソフトウェアアシスタントを持つことになります。
もしそうでなければ、明らかに生産性が大幅に低下し、より質の低いコードを作成することになります。
これは3,000万人です。
世界には10億人のナレッジワーカーがいます。
AIエージェントが次のロボット産業になり、複数兆ドルの機会になる可能性が非常に高いことは明らかです。
これらのAIエージェントで行った作業と、パートナーと行った作業のブループリントのいくつかをお見せしましょう。
(ビデオ再生)

AIエージェントは、私たちのために、そして私たちと共に働く新しいデジタルワークフォースです。

AIエージェントは、ミッションについて推論し、タスクに分解し、データを取得またはツールを使用して質の高い応答を生成するモデルのシステムです。
NVIDIAのエージェントAI構築ブロック、NEM事前訓練モデル、NEMOフレームワークにより、組織は簡単にAIエージェントを開発し、どこでも展開することができます。

私たちは従業員と同じように、会社の方法についてエージェントワークフォースをオンボーディングし、訓練します。
AIエージェントはドメイン固有のタスクエキスパートです。

4つの例をお見せしましょう。

数十億のナレッジワーカーと学生のために、AI研究アシスタントエージェントは講義、ジャーナル、財務結果などの複雑な文書を取り込み、簡単な学習のためのインタラクティブなポッドキャストを生成します。
UNET回帰モデルとディフュージョンモデルを組み合わせることで、CoreDiffはグローバルな気象予報を25キロメートルから2キロメートルにダウンスケールできます。
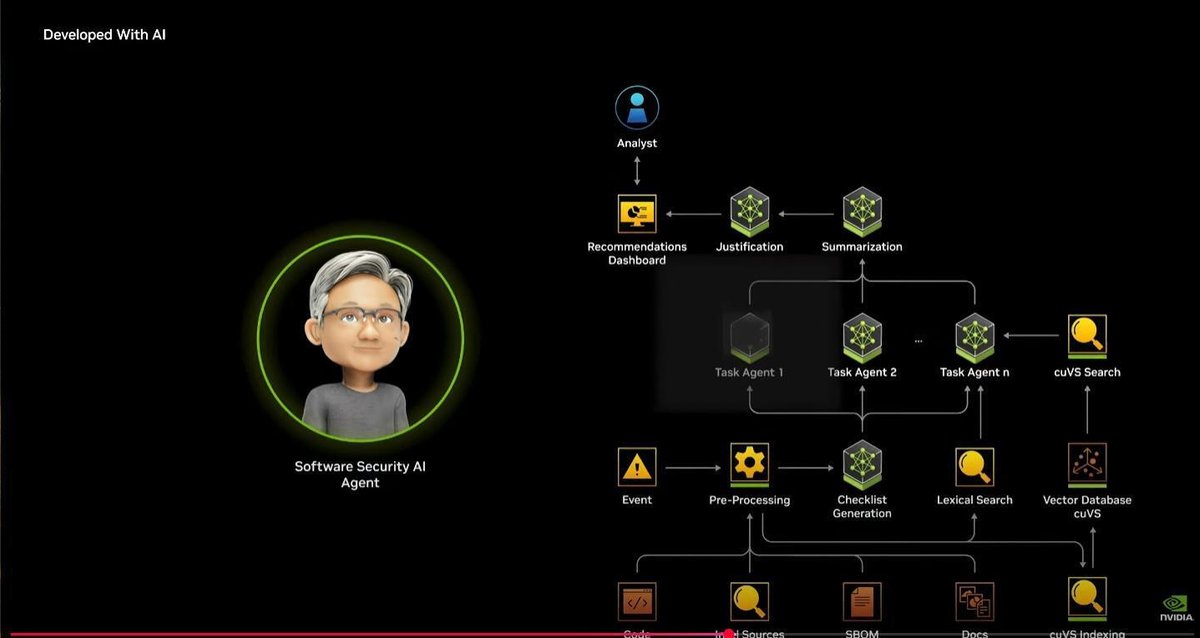

NVIDIAのような開発者は、ソフトウェアのセキュリティAIエージェントを管理し、継続的にソフトウェアの脆弱性をスキャンし、必要なアクションを開発者に警告します。

仮想ラボAIエージェントは、研究者が数十億の化合物を設計・スクリーニングし、有望な薬剤候補をこれまでにない速さで見つけることを支援します。


NVIDIA MetropolisブループリントをベースにしたNVIDIAアナリティクスAIエージェントには、NVIDIA Cosmos Nematronビジョン言語モデル、Lama Nematron LLM、NEMO Retrieverが含まれています。

Metropolisエージェントは、1日に10万ペタバイトのビデオを生成する数十億台のカメラからのコンテンツを分析します。

インタラクティブな検索、要約、自動レポート生成を可能にします。

そして交通流を監視し、渋滞や危険を警告します。

産業施設では、プロセスを監視し、改善のための推奨事項を生成します。

Metropolisエージェントは数百台のカメラからのデータを集中管理し、事故が発生した際に作業員やロボットを迂回させることができます。
エージェントAIの時代は、すべての組織にとって到来しています。
(ビデオ再生ここまで)
はい。
それは野球の試合での最初の投球でした。それは生成されたものではありません。
誰も感動していなかったと感じたので。
はい、AIはクラウドで作成され、クラウド向けに作成されました。
AIはクラウドで作成され、クラウド向けに作成されました。
そして携帯電話でAIを楽しむのは、もちろん完璧です。
非常に近い将来、私たちは継続的なAIを持つことになります。
そしてMetaのグラスを使用する時、もちろん何かを指さしたり、見たりして、欲しい情報を尋ねることができます。
そしてAIはクラウドで完璧です。クラウドで作成され、クラウドで完璧でした。
しかし、私たちはそのAIを至る所に持っていきたいと考えています。
すでにNVIDIA AIを任意のクラウドに持っていけることを言及しましたが、会社の内部にも置くことができます。
しかし、私たちが何よりもしたいのは、PCにも搭載することです。

ご存知の通り、Windows 95はコンピュータ業界に革命をもたらしました。
新しいマルチメディアサービスを可能にし、アプリケーションの作成方法を永遠に変えました。
Windows 95、このコンピューティングモデルは、もちろんAIには完璧ではありません。
そのため、私たちが将来的にしたいのは、あなたのAIを基本的にあなたのAIアシスタントにすることです。

そして3D APIやサウンドAPI、ビデオAPIだけでなく、3Dの生成APIや言語の生成API、音声の生成AIなどを持つことになります。
そしてクラウドの巨大な投資を活用しながら、それを可能にするシステムが必要です。
私たちがAIモデルのプログラミングの新しい方法をさらに作成することは、世界的にも不可能です。
それは起こりえません。
そしてもし Windows PCを世界クラスのAI PCにする方法を見つけることができれば、それは完全に素晴らしいことでしょう。
答えはWindowsであることが判明しました。
Windows WSL 2です。

Windows WSL 2です。
Windows WSL 2は基本的に1つの中に2つのオペレーティングシステムがあります。
完璧に動作します。
開発者向けに開発され、ベアメタルにアクセスできるように開発されています。
WSL 2はクラウドネイティブアプリケーション向けに最適化されてきました。
そして非常に重要なことに、CUDAのために最適化されてきました。
その結果、WSL 2は標準でCUDAを完璧にサポートしています。
NVIDIA NIMS、NVIDIA NEMO、ai.nvidia.comにアップロードされる予定のブループリントで私が示したすべてのものは、コンピュータに合う限り、そのモデルに合う限り、視覚モデルや言語モデル、音声モデル、これらのアニメーション人間デジタル人間モデルなど、さまざまな種類のモデルがあなたのPCに完璧に合うでしょう。
そしてダウンロードすれば、そのまま実行されるはずです。
そのため、私たちの焦点は、Windows WSL 2、Windows PCを、私たちが生きている限り、サポートし、維持する一流のプラットフォームにすることです。
これは世界中のエンジニアと開発者にとって信じられない出来事です。
それで作成できるものを見せましょう。
これは私たちが作成したブループリントの一例です。
(ビデオ再生)
生成AIは、シンプルなテキストプロンプトから驚くべき画像を合成します。

しかし、画像の構成を言葉だけでコントロールするのは難しい場合があります。

NVIDIA NIMマイクロサービスを使用すると、クリエイターは単純な3Dオブジェクトを使用してAI画像生成をガイドすることができます。
コンセプトアーティストがこのテクノロジーを使用してシーンのルックを開発する方法を見てみましょう。
手作りまたはAIで生成された3Dアセットのレイアウトから始めます。

そして、Fluxのような画像生成NIMを使用して、3Dシーンに準拠した視覚を作成します。

構図を洗練するためにオブジェクトを追加または移動します。

完璧なショットをフレーミングするためにカメラアングルを変更します。

または新しいプロンプトで全シーンを再構想します。

生成AIとNVIDIA NIMに支援されて、アーティストは素早く自分のビジョンを実現できます。

(ビデオ再生ここまで)
あなたのPCのためのNVIDIA AI。
世界中に何億台ものWindowsを搭載したPCがあり、私たちはそれらをAI対応にすることができます。

OEM、私たちが協力している全てのPCのOEM、基本的に世界をリードするすべてのPCのOEMがこのスタックに対応するPCを準備することになります。
そのため、AI PCがあなたの近くの家庭にやってきます。
Linuxは良いですね。
はい、物理AIについて話しましょう。
Linuxと言えば、物理AIについて話しましょう。

物理AI。
想像してください。あなたの大規模言語モデルは、左側にコンテキストとプロンプトを与えると、一度に1つずつトークンを生成して出力を生成します。
基本的にそれがどのように機能するかです。
驚くべきことは、中間のこのモデルがかなり大きく、数十億のパラメータを持っていることです。
コンテキストの長さは信じられないほど長いです。なぜなら、PDFを読み込むことを決めるかもしれないからです。
私の場合、質問をする前に複数のPDFを読み込むかもしれません。
それらのPDFはトークンに変換されます。
トランスフォーマーの基本的な注意特性は、すべてのトークンが他のすべてのトークンに対する関係性と関連性を見つけることです。
そのため、何十万ものトークンを持つことができ、計算負荷は二次関数的に増加します。
そしてこれを行い、すべてのパラメータ、すべての入力シーケンスをトランスフォーマーの各層を通して処理し、1つのトークンを生成します。
これがBlackwellが必要だった理由です。
そして次のトークンは、現在のトークンが完了したときに生成されます。
現在のトークンを入力シーケンスに入れ、それ全体を取って次のトークンを生成し、一度に1つずつ行います。
これがトランスフォーマーモデルです。
これが非常に効果的で、計算要求が高い理由です。
PDFの代わりに、それがあなたの周囲の環境だったらどうでしょうか?
そしてプロンプト、質問の代わりに、それがリクエストだったらどうでしょうか?
あそこに行って、その箱を拾って持ち帰ってください。
そしてテキストとしてトークンで生成される代わりに、アクショントークンを生成します。
私が今説明したのは、ロボット工学の未来にとって非常に理にかかったことです。
そしてその技術はすぐそこにあります。
しかし私たちがする必要があるのは、効果的に、GPTが言語モデルであるのと同様に、世界モデルを作成することです。
そしてこの世界モデルは世界の言語を理解する必要があります。物理的なダイナミクスを理解する必要があります。
重力や摩擦、慣性のようなものです。
幾何学的および空間的関係を理解する必要があります。
因果関係を理解する必要があります。
何かを落とすと、地面に落ちます。
それを突くと、倒れます。
物体の永続性を理解する必要があります。
ボールをキッチンカウンターの上で転がすと、反対側に行ったとき、ボールは別の量子宇宙に行ったわけではなく、まだそこにあります。
そしてこれらすべての種類の理解は、今日ほとんどのモデルが非常に苦手とする直感的な理解です。
そのため、私たちは世界を作成したいと考えています。
世界基盤モデルが必要です。
本日、私たちは非常に大きなことを発表します。
物理的世界を理解するために設計された世界基盤モデル、NVIDIA Cosmosを発表します。
そしてこれを本当に理解する唯一の方法は、それを見ることです。
再生してみましょう。
(ビデオ再生)

次のAIのフロンティアは物理AIです。
モデルのパフォーマンスはデータの可用性に直接関係します。
しかし物理世界のデータは、キャプチャ、キュレーション、ラベル付けが高コストです。

NVIDIA Cosmosは、物理AIを進歩させるための世界基盤モデル開発プラットフォームです。

これには自己回帰型世界基盤モデル、拡散ベースの世界基盤モデル、高度なトークナイザー、NVIDIA CUDA、そしてAIで加速されたデータパイプラインが含まれています。
Cosmosモデルはテキスト、画像、またはビデオプロンプトを取り込み、ビデオとして仮想世界の状態を生成します。

Cosmos生成は、実世界の環境、照明、物体の永続性など、自動運転車とロボティクスのユースケースの独自の要件を優先します。

開発者はNVIDIA Omniverseを使用して、物理ベース、地理空間的に正確なシナリオを構築します。

そしてOmniverseのレンダリングをCosmosに出力し、写真のようにリアルな、物理ベースの合成データを生成します。
多様なオブジェクトや環境、天候のような条件でも...
■一部、音声が飛んでいます■
世界の開発者エコシステムと協力して、NVIDIAは次世代の物理AIを進歩させることを支援しています。
(ビデオ再生ここまで)

NVIDIA Cosmos。
NVIDIA Cosmos。
NVIDIA Cosmos、世界初の世界基盤モデルです。
2,000万時間のビデオで訓練されています。
この2,000万時間のビデオは物理的なダイナミックなものに焦点を当てています。
ダイナミックな自然、自然のテーマ、テーマ、人間の歩行、手の動き、物の操作、素早いカメラの動きなどです。
これは本当にAIにクリエイティブなコンテンツを生成させることではなく、物理的な世界を理解させることについてです。
そしてこの物理AIにより、その結果として多くのダウンストリームのことができます。
モデルを訓練するために合成データ生成を行うことができます。
蒸留して、効果的にロボティクスモデルの種、始まりに変換することができます。
複数の物理ベース、物理的にもっともらしい未来のシナリオを生成することができます。基本的にドクター・ストレンジのようなことができます。
このモデルは物理的な世界を理解しているので、もちろん、生成された大量の画像を見ましたね。
このモデルは物理的な世界を理解しています。
もちろん、キャプション付けもできます。
そしてビデオを取り込んで信じられないほど上手くキャプションを付けることができ、そのキャプションとビデオを使って大規模言語モデル、マルチモーダル大規模言語モデルを訓練することができます。
そしてこの技術を使って、この基盤モデルを使ってロボットや大規模言語モデルを訓練することができます。

これがNVIDIA Cosmosです。
このプラットフォームには、リアルタイムアプリケーション用の自己回帰モデル、非常に高品質な画像生成のための拡散モデル、信じられないトークナイザー、基本的に実世界の語彙を学習し、あなた自身のデータで訓練したい場合のデータパイプラインがあります。非常に多くのデータが関与するため、エンドツーエンドですべてを加速化しました。
これは世界初のCUDA加速およびAI加速されたデータ処理パイプラインです。
これらすべてがCosmosプラットフォームの一部です。
そして本日、Cosmosがオープンライセンスであることを発表します。
GitHubで利用可能です。
(観客拍手)
私たちはこの瞬間を、そして高速モデル、メインストリームモデル、また教師モデル、基本的には知識転移モデルのための小型、中型、大型があることを期待しています。
Cosmos世界基盤モデルがオープンになることで、LAMA 3がエンタープライズAIに対して行ったことを、ロボティクスと産業用AIの世界に対して行うことを本当に期待しています。

魔法はCosmosをOmniverseに接続したときに起こります。
その根本的な理由はこうです。Omniverseは物理的に基づいているのではなく、物理学に基づいています。
それはアルゴリズム的な物理学、原理的な物理学シミュレーションに基づくシステムです。
それはシミュレーターです。
それをCosmosに接続すると、Osmos生成を制御し条件付けすることができる基盤、真実の基盤を提供します。
その結果、Osmosから出てくるものは真実に基づいています。
これは、大規模言語モデルをrag、検索拡張生成システムに接続するのと全く同じアイデアです。
AI生成を真実に基づかせたいのです。
そして、この2つの組み合わせにより、物理的にシミュレートされた、物理的に基づいたマルチバース生成器が得られます。
そしてアプリケーションとユースケースは本当にエキサイティングです。
もちろん、ロボティクス、産業用アプリケーションにとって、それは非常に、非常に明確です。
このCosmos プラス Omniverse プラス Cosmosは、ロボットシステムを構築するために必要な第3のコンピュータを表しています。

すべてのロボティクス企業は最終的に3つのコンピュータを構築する必要があります。
ロボティクス、ロボットシステムは工場かもしれません、ロボットシステムは車かもしれません、ロボットかもしれません。
3つの基本的なコンピュータが必要です。
もちろん1つのコンピュータはAIを訓練するためのものです。私たちはそれをDGXコンピュータと呼んでいます。
もちろん、もう1つは完了したらAIを展開するためのものです。私たちはそれをAGXと呼んでいます。それは車の中、ロボットの中、またはAMRの中、スタジアムの中など、これらのコンピュータはエッジにあり、自律的です。
しかし、この2つをつなぐには、デジタルツインが必要です。
これがあなたが見ていたすべてのシミュレーションです。
デジタルツインは、訓練されたAIが実践し、洗練され、合成データ生成、強化学習AIフィードバックなどを行う場所です。
そしてそれはAIのデジタルツインです。
これら3つのコンピュータは対話的に動作することになります。
産業界に対するNvidiaの戦略、私たちはしばらくこれについて話してきましたが、この3つのコンピュータシステムです。
3体問題の代わりに、3つのコンピュータソリューションを持っています。
そしてこれがNvidiaのロボティクスです。
(観客拍手)
では、3つの例を挙げましょう。

最初の例は、これらすべてを産業用可視化にどのように適用するかということです。
数百万の工場、数十万の倉庫があり、それは基本的に50兆ドルの製造業の背骨です。
そのすべてがソフトウェア定義になる必要があります。
すべてが将来的に自動化を持つ必要があります。
そしてすべてがロボティクスを搭載することになります。
私たちは世界をリードする倉庫自動化ソリューションプロバイダーのKeyon、世界最大のプロフェッショナルサービスプロバイダーのAccentureと提携しています。そして彼らはデジタル製造に大きな焦点を当てています。
私たちは一緒に本当に特別なものを作り出すために協力しています。
それを数秒後にお見せしますが、私たちのゴートゥーマーケットは基本的に他のすべてのソフトウェアプラットフォームと私たちが持つすべてのテクノロジープラットフォームと同じです。

開発者とエコシステムパートナーを通じて、Omniverseに接続するエコシステムパートナーが増え続けています。
その理由は非常に明確です。
誰もが産業の未来をデジタル化したいと考えています。
世界のGDPの50兆ドルには、非常に多くの無駄があり、自動化の機会が多くあります。
では、KeyonとAccentureと一緒に行っているこの一例を見てみましょう。
(ビデオ再生)
サプライチェーンソリューション企業のKeyon、プロフェッショナルサービスのグローバルリーダーのAccenture、そしてNVIDIAは、1兆ドルの倉庫・流通センター市場に物理AIをもたらしています。

高性能な倉庫物流の管理には、常に変化する変数の影響を受ける複雑な意思決定の網を Navigate する必要があります。
これには、日々および季節的な需要の変化、空間的制約、労働力の可用性、多様なロボットおよび自動化システムの統合が含まれます。
そして今日、物理的な倉庫の運用KPIを予測することはほぼ不可能です。
これらの課題に取り組むために、Keyonは、ロボットフリートをテストし最適化するための産業用デジタルツインを構築するためのNVIDIA Omniverseブループリントであるメガを採用しています。
まず、Keyonの倉庫管理ソリューションは、バッファーロケーションからシャトルストレージソリューションへの荷物の移動など、デジタルツイン内の産業用AIブレインにタスクを割り当てます。

ロボットのブレインは、オープンUSDコネクタを使用してOmniverseにデジタル化された物理倉庫のシミュレーション内にあり、CAD、ビデオと画像から3D、LIDARからポイントクラウド、AI生成データを集約します。

ロボットフリートは、Omniverseデジタルツイン環境を認識し推論して、次の動きを計画し行動することでタスクを実行します。

ロボットブレインはセンサーシミュレーションを通じて結果の状態を見て、次のアクションを決定することができます。
メガがデジタルツイン内のすべてのものの状態を正確に追跡している間、ループは続きます。

今、Keyonは、処理能力、効率性、利用率などの運用KPIを測定しながら、無限のシナリオを大規模にシミュレートすることができます。すべて物理的な倉庫に変更を展開する前にです。
NVIDIAと共に、KeyonとAccentureは産業用自律性を再発明しています。
(ビデオ再生ここまで)

将来的には、それは信じられません。すべてがシミュレーション内にあります。
将来的には、すべての工場がデジタルツインを持ち、そのデジタルツインは実際の工場とまったく同じように動作します。
実際、OmniverseとCosmosを使用して大量の将来のシナリオを生成し、そしてAIがKPIに対して最適なシナリオを決定し、それが実際の工場に展開されるAIのプログラミング制約、プログラムとなります。
次の例は、自律走行車です。
AV革命が到来しました。

WaymoとTeslaの成功から多くの年月を経て、自律走行車が最終的に到来したことは非常に、非常に明確です。
この業界への私たちの提供は3つのコンピュータ、AIを訓練するための訓練システム、シミュレーションシステム、合成データ生成システム、OmniverseそしてCosmosと車の中のコンピュータです。
各自動車会社は私たちと異なる方法で協力し、1つまたは2つ、または3つのコンピュータを使用するかもしれません。
私たちは世界中のほぼすべての主要な自動車会社と協力しています。WaymoとZooks、もちろんTesla、データセンターでは、世界最大のEV企業BYD、JLRは本当にクールな車を開発中です、Mercedesは今年から生産を開始するNVIDIA搭載の車の群れを持っています。
そして本日、私は非常に、非常に嬉しく発表できます。ToyotaとNVIDIAが次世代AVsを作るためにパートナーを組むことになりました。
(観客拍手)
本当に多くの、多くのクールな企業があります。LucidとRivianとXiaomi、そしてもちろんVolvo、本当に多くの異なる企業があります。
Wabiは自動運転トラックを開発しています、Auroraは、今週も発表したように、NVIDIAを使用して自動運転トラックを開発することになりました。
自律走行、毎年1億台の車が製造され、世界中の道路に10億台の車両があり、毎年1兆マイルが世界中で運転されています。
それらすべてが、高度に自律的または完全に自律的になろうとしています。
これは非常に大きな産業になるでしょう。
これは世界初の複数兆ドルのロボティクス産業になる可能性が高いと予測しています。
私たちにとってのこのビジネス、世界に展開し始めているこれらの車のうちのほんの数台で、私たちのビジネスはすでに40億ドルであり、今年はおそらく約50億ドルのランレートになるでしょう。
すでに本当に重要なビジネスになっており、これは非常に大きくなるでしょう。

本日、私たちは、車向けの次世代プロセッサ、車向けの次世代コンピュータである「Thor」を発表します。
ここに1つ持っています。少々お待ちください。
はい、これがThorです。

これがThorです。
これはロボティクスコンピュータです。
これはロボティクスコンピュータで、センサー、途方もない量のセンサー情報を取り込みます。
それを処理し、数々のカメラ、高解像度、レーダー、ライダーなど、すべてがこのチップに入力されます。
そしてこのチップはそれらすべてのセンサーを処理し、トークンに変換し、トランスフォーマーに入れて、次のパスを予測しなければなりません。
このAVコンピュータは現在、本格生産に入っています。
Thorは、現在の自律走行車の標準となっている前世代のOrinと比べて20倍の処理能力を持っています。
これは本当に信じられないことです。
Thorは本格生産に入っています。
なお、このロボティクスプロセッサは完全なロボットにも搭載されます。
それはAMRかもしれませんし、人型ロボットかもしれません。それは頭脳かもしれませんし、マニピュレーターかもしれません。
このプロセッサは基本的にユニバーサルなロボティクスコンピュータです。
私たちのドライブシステムの2番目の部分で、私が非常に誇りに思っているのは安全性への献身です。

Drive OSは、自動車向けの機能安全の最高基準であるASIL-Dまで認証された、初のソフトウェア定義プログラマブルAIコンピュータになったことを発表できて嬉しく思います。唯一かつ最高の基準です。
これを本当に、本当に誇りに思います。
ASIL-D、ISO 26262。
これは約15,000エンジニア年の仕事です。
これは本当に驚異的な仕事です。
その結果、CUDAは現在、機能的に安全なコンピュータになりました。
そのため、ロボットを構築している場合、Nvidia CUDA、そうです。
(観客拍手)
さて、自動運転車の文脈でOmniverseとCosmosを何に使用するかをお見せすると言いました。
そして今日は、道路を走る車の大量のビデオをお見せする代わりに - それもお見せしますが - AIを使って自動的にデジタルツインを再構築し、その機能を使って将来のAIモデルを訓練する方法をお見せしたいと思います。
では、再生してみましょう。
(ビデオ再生)
自律走行車革命が到来しました。



すべてのロボットと同様に、自律走行車の構築には3つのコンピュータが必要です。AIモデルを訓練するNvidia DGX、テストドライブと合成データを生成するOmniverse、そして車載のスーパーコンピュータであるDrive AGXです。
安全な自律走行車を構築するには、エッジケースに対処する必要がありますが、実世界のデータには限界があります。
そのため、訓練には合成データが不可欠です。

Nvidia Omniverse、AIモデル、Cosmosを搭載した自律走行車データファクトリーは、訓練データを桁違いに強化する合成運転シナリオを生成します。
まず、OmniMapはマップと地理空間データを融合して、運転可能な3D環境を構築します。

運転シナリオのバリエーションは、ドライブログの再生やAIトラフィックジェネレーターから生成できます。





次に、ニューラル再構築エンジンは自律走行車のセンサーログを使用して、高精度な4Dシミュレーション環境を作成します。
以前の運転を3Dで再生し、訓練データを増幅するためのシナリオバリエーションを生成します。

最後に、Edify 3DSは既存のアセットライブラリを自動的に検索するか、新しいアセットを生成してシミュレーション対応のシーンを作成します。

Omniverseのシナリオは、Cosmosを条件付けして大量の写実的なデータを生成するために使用され、シミュレーションと実世界のギャップを縮小します。

そしてテキストプロンプトを使用して、運転シナリオの無限に近いバリエーションを生成します。


Cosmos Nemotron Video Searchを使用すると、記録された運転と組み合わされた大規模な合成データセットをキュレーションして、モデルを訓練することができます。
NvidiaのAIデータファクトリーは、数百回の運転を数十億マイルの実効的な走行に拡大し、安全で高度な自律走行の基準を設定します。
(ビデオ再生ここまで)
信じられないですよね。
数千回の運転を数十億マイルに変換します。
私たちは自律走行車のための膨大な訓練データを持つことになります。
もちろん、実際の車を道路で走らせる必要はまだあります。
もちろん、私たちは生きている限り、継続的にデータを収集し続けます。
しかし、このマルチバース、物理ベース、物理的に基づいた能力を使用した合成データ生成により、物理的に基づき、正確で、よりもっともらしいAIの訓練データを生成できるため、膨大なデータで訓練することができます。
AV産業はここにあります。
これは信じられないほどエキサイティングな時期です。次の数年に対して本当に、本当に、本当にワクワクしています。
コンピュータグラフィックスが信じられないペースで革新されたように、次の数年でAVの開発のペースが劇的に加速するのを見ることになるでしょう。
(観客拍手)
次はロボティクスだと思います。
そして...
(観客歓声)

人型ロボット。
皆さん。
汎用ロボティクスのChatGPTモーメントはすぐそこにあります。
実際、私が話してきたすべての実現技術が、次の数年で非常に急速なブレークスルー、驚くべきブレークスルーを汎用ロボティクスで見ることを可能にします。
汎用ロボティクスが非常に重要な理由は、トラックや車輪を持つロボットが特別な環境を必要とするのに対し、世界には私たちが作ることができる3つのロボットがあり、グリーンフィールドを必要としないからです。
ブラウンフィールドへの適応は完璧です。
もしこれらの驚くべきロボットを構築できれば、私たち自身のために構築した世界にそのまま展開できます。




これら3つのロボットは、1つ目は、エージェントロボットとエージェントAIです。情報労働者なので、オフィスにある私たちのコンピュータに対応できる限り、素晴らしいでしょう。
2番目は、自動運転車です。
その理由は、私たちが100年以上かけて道路と都市を建設してきたからです。
そして3番目は、人型ロボットです。
これら3つを解決する技術があれば、これは世界が今まで見た中で最大の技術産業となるでしょう。
そしてロボティクスの時代はすぐそこにあると考えています。
重要な能力は、これらのロボットをどのように訓練するかです。
人型ロボットの場合、模倣情報の収集は非常に難しいです。
その理由は、車の場合は単に運転すればよく、私たちは常に車を運転していますが、これらの人型ロボットの場合、人間のデモンストレーションという模倣情報を行うのは非常に労力がかかるからです。
そのため、数百のデモンストレーション、数千の人間のデモンストレーションを取り、人工知能とOmniverseを使って何らかの方法で数百万のロボットの動きを合成的に生成する賢明な方法を考え出す必要があります。
そしてそれらの動きから、AIはタスクの実行方法を学習することができます。
それがどのように行われるのかをお見せしましょう。
(ビデオ再生)

世界中の開発者が次世代の物理AI実体化ロボット、人型ロボットを構築しています。
汎用ロボットモデルの開発には、キャプチャとキュレーションにコストのかかる大量の実世界データが必要です。

NVIDIA Isaac Grootはこれらの課題に取り組むのを支援し、人型ロボット開発者に4つのものを提供します。ロボット基盤モデル、データパイプライン、シミュレーションフレームワーク、そしてThorロボティクスコンピュータです。

合成モーション生成のためのNVIDIA Isaac Grootブループリントは、開発者が少数の人間のデモンストレーションから指数関数的に大きなデータセットを生成できる模倣学習のためのシミュレーションワークフローです。
まず、Groot Teleopにより、熟練した作業者はApple Vision Proを使用してロボットのデジタルツインにポータル接続することができます。

これは、物理的なロボットがなくてもデータをキャプチャできることを意味し、リスクのない環境でロボットを操作でき、物理的な損傷や摩耗の可能性を排除できます。
ロボットに単一のタスクを教えるために、オペレーターは少数のテレオペレーションによるデモンストレーションを通じてモーショントラジェクトリをキャプチャし、Groot Mimicを使用してこれらのトラジェクトリをより大きなデータセットに増やします。

次に、ドメインランダム化と3Dからリアルへのアップスケーリングのために、OmniverseとCosmosを基盤としたGroot Genを使用して、指数関数的に大きなデータセットを生成します。

OmniverseとCosmosのマルチバースシミュレーションエンジンは、ロボットポリシーを訓練するための大規模なデータセットを提供します。
ポリシーが訓練されると、開発者は実際のロボットに展開する前に、IsaacSimでソフトウェアインザループのテストと検証を実行できます。
NVIDIA Isaac Grootによって実現される汎用ロボティクスの時代が到来しています。
私たちはロボットを訓練するための膨大なデータを持つことになります。
(ビデオ再生ここまで)
NVIDIA Isaac Groot、NVIDIA Isaac Groot、これは汎用ロボティクスの開発を加速するために、ロボティクス産業に技術要素を提供する私たちのプラットフォームです。
そして、もう1つお見せしたいものがあります。
これらすべては、約10年前に私たちが開始したこの信じられないプロジェクトがなければ不可能でした。
社内ではProject Digitsと呼ばれていました。Deep Learning GPU Intelligence Training System、Digitsです。
発表前に、私はDGXに縮めました。
そしてRTX、AGX、OVX、そして会社内の他のすべてのXと調和させるために。
そしてDGX1は本当に革命を起こしました。DGX1はどこですか?

DGX1は人工知能に革命をもたらしました。
私たちがそれを構築した理由は、研究者とスタートアップが箱から出してすぐに使えるAIスーパーコンピュータを持てるようにしたかったからです。
過去のスーパーコンピュータの構築方法を想像してください。
本当に自分の施設を作り、自分のインフラを構築し、本当にそれを工学的に存在させる必要がありました。
そこで私たちは、研究者とスタートアップのために、文字通り箱から出してすぐに使えるAI開発用のスーパーコンピュータを作りました。
2016年に最初の1台をOpenAIというスタートアップ企業に納入しました。Elonもそこにいて、Ilya Suskovaもいて、多くのNVIDIAのエンジニアもいました。
そしてDGX1の到着を祝いました。明らかにそれは人工知能コンピューティングに革命をもたらしました。
しかし今や人工知能はどこにでもあります。
もはや研究者やスタートアップの研究室だけではありません。
ご存知の通り、私たちは人工知能を望んでいます。冒頭でお話ししたように、これは今やコンピューティングの新しい方法です。
これはソフトウェアを作る新しい方法です。
すべてのソフトウェアエンジニア、すべてのエンジニア、すべてのクリエイティブアーティスト、今日ツールとしてコンピュータを使用するすべての人がAIスーパーコンピュータを必要とするでしょう。
そこで、私はDGX1がもっと小さければいいのにと思いました。

そして、そうですね...
そうですね...想像してください、
皆様、私たちの...
(観客歓声)
(観客拍手)
これがNVIDIAの最新のAIスーパーコンピュータです。

(観客歓声)
現在はProject Digitsと呼ばれています。
もし良い名前があれば、ご連絡ください。
これが、驚くべきことです。
これはAIスーパーコンピュータです。
NVIDIAのAIスタック全体がこれで動作します。
NVIDIAのすべてのソフトウェアがこれで動作します。
DGX Cloudがこれで動作します。
これはどこかに置かれ、ワイヤレスか、あるいはコンピュータに接続されます。
望めばワークステーションにもなります。
そしてクラウドスーパーコンピュータのようにアクセスでき、到達でき、NVIDIAのAIがそれで動作します。
そしてこれは、私たちが開発してきた超秘密チップGB110、私たちが作る最小のGrace Blackwellに基づいています。
そして私は、まあ、皆さん、中を見せましょう。

(電子音)

(電子音)





(観客拍手)
これは本当に、これは本当に、これはとてもかわいいですね。
そしてこれが内部のチップです。

これは生産中です。
この最高機密チップは、CPU、Gray CPUを、世界をリードするSOC企業であるMediaTekと協力して開発しました。
彼らは私たちと協力してこのCPU、CPU SOCを構築し、チップ間NVLinkでBlackwell GPUと接続しました。

そしてここにあるこの小さなものは本格生産中です。
このコンピュータは5月頃に利用可能になる予定で、皆さんのもとにやってきます。
私たちができることは本当に信じられず、本当に、私は考えていました、
手が必要なのか、ポケットが必要なのか。
さて、これが実際の姿です。

このようなものが欲しくない人がいるでしょうか?
そしてPC、Mac、何でも使えます。
なぜなら、これはクラウドプラットフォームだからです。
デスクに置かれるクラウドコンピューティングプラットフォームです。
望めばLinuxワークステーションとしても使用できます。
Double Digitsが欲しい場合は、このような感じです。

ConnectXで接続し、Nickel、GPU Direct、すべてが箱から出してすぐに使えます。
スーパーコンピュータのようです。
私たちのスーパーコンピューティングスタック全体が利用可能です。
これがNVIDIA Project Digitsです。
(観客拍手)
では、お話ししたことをまとめましょう。
私たちは3つの新しいBlackwellを生産していると申し上げました。

Grace Blackwellスーパーコンピュータ、NVLink 72sが世界中で生産されているだけでなく、現在3つの新しいBlackwellシステムが生産中です。
1つの驚くべきAI、世界初の物理AI基盤モデルがオープンで、世界のロボティクスなどの産業を活性化するために利用可能です。そして3つのロボット。
私たちはエージェントAI、人型ロボット、そして自動運転車に取り組んでいます。
素晴らしい1年でした。
皆様のパートナーシップに感謝いたします。
ご来場いただいた皆様に感謝いたします。
昨年を振り返り、来年を展望する短いビデオを作成しました。
再生をお願いします。
(ビデオ再生)
<これまでのビデオの連続再生>
(ビデオ再生ここまで)
(観客拍手)
皆様、素晴らしいCESを。
新年おめでとうございます。
ありがとうございました。
【要約】
1.新製品の発表:
RTX Blackwellファミリー (RTX 50シリーズ) の発表
4090の2倍の性能を持つRTX 5090
より手頃な価格帯の5070 ($549)
ノートPC向けの5070~5090シリーズ
2.AIとコンピューティングの進化:
1993年のNV1から現在までのNVIDIAの歴史を振り返り
CUDAの開発とAI革命への貢献を説明
AIの進化を「知覚AI」→「生成AI」→「エージェントAI」→「物理AI」と説明
3.NVIDIA Cosmosの発表:
世界初の「世界基盤モデル」
2,000万時間の動画で訓練された物理的世界理解モデル
オープンソースで提供
Omniverseと組み合わせることで物理シミュレーションが可能
4.自動運転技術の進展:
新世代車載コンピュータ「Thor」の発表
トヨタとの新規パートナーシップ発表
合成データ生成による自動運転学習の革新
年間50億ドル規模のビジネスに成長
5.ロボティクスへの展開:
NVIDIA Isaac Grootプラットフォームの発表
人型ロボット開発のための包括的なソリューション提供
Apple Vision Proを活用したロボット制御システム
6.Project Digitsの発表:
デスクトップサイズの新型AIスーパーコンピュータ
MediaTekと共同開発したGB110チップ搭載
5月頃の発売予定
主要な戦略的方向性:
1.AIの民主化:より小型で手頃な価格のAIコンピューティング製品の提供
2.物理的世界とデジタル世界の融合:CosmosとOmniverseによる実世界シミュレーション
3.三大ロボット分野への注力:
エージェントAI(情報労働)
自動運転車
人型ロボット
講演全体を通じて、NVIDIAが単なるグラフィックスカード企業から、AI、自動運転、ロボティクスを包括的にカバーする総合テクノロジー企業へと進化している様子が明確に示されました。特に、物理的世界の理解とシミュレーションに焦点を当てた新しい取り組みは、次世代のAIとロボティクスの発展に大きな影響を与える可能性を示唆しています。