
SoftBank World 2024 孫 正義 特別講演(2024/10/3)

【要約】
AGI(汎用人工知能)は2-3年以内に実現する可能性がある。
ASI(人工超知能)は10年以内に人間の知能の1万倍に達する可能性がある。
最新のAIモデル(O1)は、考える能力を持ち、多くの分野で人間の専門家レベルを超えている。
強化学習と並列処理により、AIは短時間で膨大な試行錯誤を行い、新しい解決策を見出すことができる。
パーソナルエージェントが登場し、個人の生活のあらゆる面をサポートする。
A to A(Agent to Agent)の時代が来る。エージェント同士が通信し、人間の代わりに多くのタスクを処理する。
AIの進化は単なる知能の向上だけでなく、知性の発展へと向かう。これには倫理、思いやり、調和が含まれる。
超知性AIの最終目標は、人類の幸福を最大化することであるべき。
適切に設計されれば、ASIは人類にとって脅威ではなく、むしろメンターのような存在になり得る。
孫氏は、この技術革新が人類の幸福につながると楽観的な見方を示し、それがソフトバンクの理念「情報革命で人々を幸せに」と一致すると述べています。
【本編】(後ほどブラッシュアップ予定)
ソフトバンクの孫でございます。よろしくお願いいたします。
最近、いろんなアレルギーのようなものが飛んでいるみたいで、ちょっと声が枯れておりますけども、よろしくお願いします。
一年に一回、このソフトバンクワールドで、これから起きるであろうと、少なくとも私がそう思っている近い未来について話す、そういう機会が今日の日であります。私なりの思い込みもあるかもしれません。でも、かなり強く思い込んでおりますので、そのつもりで聞いていただきたいというふうに思います。
それでは早速始めます。

私は超知性、これが10年以内に実現するというふうに思っています。このことについて、今日は話をしたい。どのように起きるのかということを話したいと思います。
超知性。超知性とは何かと。超知能とは何かと。知性と知能の違いを考えてみたことありますでしょうか。その辺についても、今日は語りたいと思います。

AGIがやってくると。AGI、Artificial General Intelligence。AGIを定義で一言で言えば、人工知能AIが人間の知能とほぼ一対一になるというレベルのことを、AGIというふうに世の中では定義されています。人間が喋ったのか分からない。AIが喋っているのか、壁の向こうで聞いたら分からない。というレベルのテストが一つのテストであります。
そのAGIは、去年のこの場でしたからね。私は10年以内に来るというふうに確か言ったんじゃないかと思います。今そのAGIは、10年以内という思いではなくて、グッと近まりました。今日現在私の正直な気持ちで思うAGIの達成時期は、2、3年後にやってくるというふうに考えています。
AGIには5つのレベルがあります。
まず一般的な会話。これが人間とほぼ同等の、同等のスピード。0.1秒から0.2秒以内に、パンパンパンパンと言葉のやり取りができる。しかも途中で遮っても、その内容を理解して会話が続く。まるで人間とそのまま会話しているようだと。これがレベル1の部分ですね。
レベル2はですね、既にもう半年くらい前からですね、AGIのChatGPT4.0は、アメリカでいうと大学の医学部の試験に合格できると。法学部の試験に合格できるというレベルに来ていました。しかしレベル2はですね、全てのサブジェクト、全ての科目ですね。数学だとか物理だとか歴史だとか、ありとあらゆる科目で、博士号レベル、PhDレベルの知能を持っている。これがレベル2です。
この中に来ている皆さんでですね、自分は5つぐらいの博士号のレベルを通る自信あるよという方がいたら、1人ぐらいいるかな。いませんよね、絶対ね。医学と物理と数学と科学と、異なった分野で全部博士号を持っている。1人でそんな人いないと思います。それでもAGIでいうとこのレベル2であります。
レベル3はですね、エージェント機能であります。あなたの代わりにいろんなことをやってくれるという機能であります。
レベル4はですね、ついにAGIが発明をし出すというのがレベル4。
レベル5はですね、このエージェントが1対1のレベルではなくて、組織的な活動を群れになってやってくる。というのがレベル5であります。
今日はそのレベル5のAGIのレベル5を超えるような世界を話したいと思います。それがASIの世界であります。
このASI、このAGIのレベルを1万倍ぐらい超えたもの。そのAの部分、その知能の部分をASIという風に私は定義しました。
ASIの定義というとですね、アーティフィシャル・スーパー・インテリジェンスですから、どのくらいスーパーかと。AGIは1対1ですからみんな分かりやすいんですけども、どのくらいスーパーかというとですね、たくさん、たくさん。人によってたくさんの度合いが違うわけですね。
いつかたくさんになると、いうとASIはいつか来るぞと。あんまり異論はないんじゃないかと思うんですが、じゃあいつ何倍ぐらいになるのか。いうとですね、そこには定義がないわけですね。誰も明確にいつ何倍だと、勇気を持って言ってる人はいないんです。
私は勇気を持って10年以内に、1万倍の人間の英知を1万倍超えている。AGIの1万倍レベルのものASI、これが10年以内に来るという風に思っています。
しかもこのASI人工知能がですね、超知性に進化すると。その超知性が10年以内にやってくると。この知能と知性の違いについてこの後述べていきますけれども、その詳細に入る前にですね、そもそも我々の人間の脳細胞というのは、どういう仕組みでものを考えたり記憶したり認識したりしているのか。

これはニューロンの写真ですけれども、ニューロン。我々人類の脳細胞の中に、ニューロンがいくつぐらい入っているか。何本ぐらい入っているか。自信を持って言える方はちょっと手を挙げてみていただけますか。あんまりいないですね。あれ全然いないかな。いません。
約1000億本です。ニューロン、これが1000億本あると。ニューロンがくっついたり離れたりする作業をするんですけれども、それで記憶したり考えたりするんですが、このくっついたり離れたりというのをシナプスが行います。
このシナプス、ニューロンが木の幹だとすると、シナプスは枝葉に相当するんです。この木の幹にですね細かい枝葉がいっぱい付いている。このシナプスが枝葉と枝葉がくっついたときに、ニューロン同士がくっついて電気的信号が流れる。あるいは科学的に物質がつながるということになるんですが、これをシナプスというふうに呼びます。
このシナプスが人間の脳にいくつぐらいあるかと思って答えられる方ちょっと手を挙げてください。いませんね。
つまりこのことは普段我々の日常生活ではあまり考えない質問なんですね。我々の脳にいくつもニューロンがあって脳が考えているんです。脳が考えているというのは実はシナプスが考えているんです。
このシナプスがくっついたり離れたりというのが、まるでコンピュータのトランジスタの世界のように、くっついたら電気が流れる、離れたら電気が流れないという仕組みになっているんですが、このシナプスは我々の脳には約100兆個あるというふうに言われています。
さてこのニューロンの数あるいはシナプスの数と我々の知能、これが犬や猿やトンボなどと比べてですね、どのくらい賢いかというのはニューロンの数におおむね比例するということであります。シナプスの数におおむね比例するということであります。
我々の人間の脳の1万分の1が金魚であります。魚ですね。もっとそれよりも少なくなると蚊とかなるわけです。約1兆個のシナプスがあるんですけれども、この我々の人類のシナプスの数というのは、20万年前ぐらいから今日に至るまで全く変わってないです。これDNAが我々の生命体を設計して定義してるわけですから変わらないんですね。今から1000年後も変わらないんです。1万年後も変わらないんです。100兆個のままなんです。
しかしこのシナプスに相当する生成AIのパラメータ、これはですねものすごい勢いで伸びてるんです。最近の生成AIではおおむね数兆個、一番大きなモデルでですね数兆個というふうに言われておりますけれども、よく日本的な生成AIを作るんだ。我が社製とかいろいろ言って日本製だから工夫をしようと。工夫をするということはこのパラメータの数を少なくして、ほぼ似たような成果を出すようにしようと。こういう努力をしていやそう少ないパラメータ数にすると電気があんまりいらなくなるんだ。チップの数があんまりいらなくなるんだ。だから効率がいいんだ。
そういう努力をですね小さくて美しい努力というふうに日本的だと主張する人がたくさんいるんですけども、僕にはそういえばそれはですね言い訳ですね。GPUが買えないと。電気が足りない。予算がないから仕方なくちっちゃくしてる。
それってね日本の道は狭いから田んぼのあぜ道で通れるような二輪車を作る。自転車を作ると。だからモータリゼーション、自動車の社会が来ても我が社は誇れると言ってるようなもんで、それはもう僕に合わせれば小さな小さな成功ですね。
やはり本堂の世界で新しい技術の進化は起きています。つまり数兆個で止まらない。数十兆個になり数百兆個になると。バンバン伸びていると。これが増えれば増えるほどですね賢くなるんです。
まあざっくり言ってですね、もちろんちっちゃくして効率を上げるとかいうのはあるんですけども、やっぱりAIの進化の本堂は、強くて賢くて、はるかにはるかに賢くてと。
皆さん小学校の時ね、宿題説くのに、クラスで3番目とか10番目の成績のいい人に宿題を教えてって聞いた方がいいのか。1番の生徒に聞いた方がいいのか。あえてあいつは飯をあんまり食わなくても5番でいいからあいつに聞こう。そういうことはあんまりないと思うんですね。やっぱり聞くとすれば1番賢い、正解のものに価値があるということであります。
我々人間社会、企業はみんな競争してますから、競争の中では1番優れたAI、1番優れた機能、そこに圧倒的価値が寄せられるということであります。
したがってこのパラメータの競争、ニューロンの数を増やす、シナプスの数を増やすというのは、生命体がですねこの地球上にありとあらゆる生命体がいる中で、人類が最も賢い知的活動を行っている。金魚にはABCはわからないということですね。
これがパラメータがどんどんどんどん増えると、しかもそれを有効に活用するモデル、そしてデータ。これでファインチューニングしながらですね、どんどんやっていくということであります。
我々ITの世界で情報革命という言葉をよく使いますけれども、情報って何でしょうか。ニュースに出てくる情報、天気予報。百科事典に出てくるような情報いっぱいあります。これを検索してました。
我々インターネットの世界の最大のアプリケーションの一つが検索エンジンです。情報があふれるほどあって、それに一気にアクセスできるのがインターネットです。ありとあらゆる情報がインターネットにつながってアクセスできるから、この情報の大洪水のようなものの中で探し当てなきゃいけない。効率よく素早く正確に探し当てる、これが検索エンジンでした。
この情報には検索という最大のアプリケーションがあったわけです。検索をするというのは我々日常毎日のように使っていますけれども、検索した情報というのは果たしてそのインターネットは内容を理解していたかというと、そうではないと思うんですね。
知識というものがあります。この知識というのは単に知る、情報を知るということだけでなくて、その知識を内容を理解すると。インターネットの情報検索は必ずしも内容を理解しているのではないですね。キーワードで見つけてくるというだけで、見つけたものがですね、内容をその後に考えるのは人間の頭で考えていました。内容を理解するのは人間の頭でした。
初めてこれが革命が起きました。特に去年あたりから一気にですね、ChatGPTの世界で、これはGPTのPとTというのはプリトレーニングですね。事前学習して我々の代わりにありとあらゆる知識を事前学習して内容を理解しているということです。ですから質問をしたときに単なる検索ではなくて質問した内容を理解して、その内容に基づいて答えを教えてくれると。これがGPTであります。知識を理解する。これは何だろう?理解するということになります。
さてこのGPTはいろんな言葉、これをトークンと呼びますけども、圧倒的な数のトークン、言葉にですねそれぞれのインデックスつけてベクトルで、この言葉とあの言葉は近しいと。その近しい度合い、関係性の近しい度合いに全部ベクトルのインデックスをつけて、それを処理して言葉と言葉の十字繋ぎをして理解をするということなんですけども、じゃあ質問してGPTがChatGPTが答えてくれるんですけども、理解はしているみたいだと。でも考えてるんだろうかと言うと、必ずしもChatGPTは考えてはなかったんですね。考えてるかのように見えるんですけども、言葉の十字繋ぎですから、考えてるわけでは必ずしもなかったということであります。
今日のメインテーマはこの考えるということです。圧倒的な進化がありました。先週から世に見えてきました。この考えるということ。これリーズニングという手法なんですけども、リーズニングという手法で考えるということなんですが、さてここで聞きたいと思います。
この考えるリーズニングをする、考えるという機能を使ったことあると。結構使ってる、僕は毎日今使ってるんですけど、今日も朝から使ってきました。これを自分はやってますと、自信を持って言える方は手を挙げてください。あれ、いません。
じゃあ何かということをお話します。OpenAIが先週から、先週からo1プレビューを発表して、プレビューに触ることができます。この中でChatGPT有料版のものをサブスクリプションして、毎日のように使ってるという方は手を挙げてください。これかなり使ってますよね。もう半分以上、7割ぐらい使ってます。
今日来てる人は一般の人より進んでる人だと思うんですね。日本で7割の浸透率はまだないです。でも今日来てる人はさすがにやっぱりソフトバンクはあるんですからね。これは進んだ方々であります。
進んだ皆さんも、o1をまだ使ったことがない人がほぼみんなでした。o1とChatGPTの4をこの違いが何かと、仕組みでわかってる方は手を挙げてください。ゼロ人ですか、これはやばい。やばいということです。
ゼロ人ってことは皆さん知らない。一人ぐらいもしかしたら恥ずかしくて手を挙げられなかったかもしれませんね。自信を持ってというキーワードがありましたから。これを今日は皆さんに僕が解説をいたします。
すごいんです。僕はこれノーベル賞もんだと思いますね。
Search検索エンジンは知るということでした。ChatGPTのGPTはプリトレーニングで理解するということでした。

今回のo1はGPTの頭文字がついてないんです。プリトレーニングじゃないんです。事前学習のプリトレーニングとは違うんです。だからGPTという3文字がついてないんです。o1全く新しいモデルとしてもう1回再定義するということであります。それでネーミングがo1になったんですね。
このo1の仕組みを今日説明を申し上げたいと思いますが、その前に結果を申し上げましょう。o1になってGPT-40からどのくらい進化したかということであります。
GPT-40で博士号レベルの物理だとか科学だとか生物、これを問題を解かすと何パーセントぐらい解けるか。博士号レベルですよ。かなり難しい内容のものですよ。おそらくここにいる皆さんほぼ全員正解を出せないぐらいのレベルです。博士号レベルですからね。専門家というのはPhDです、博士号です。専門家というのはここでいうのは博士号レベルの試験。GPT-40は56%正解率でした。人間の博士の方が正解率は高かったんですね。
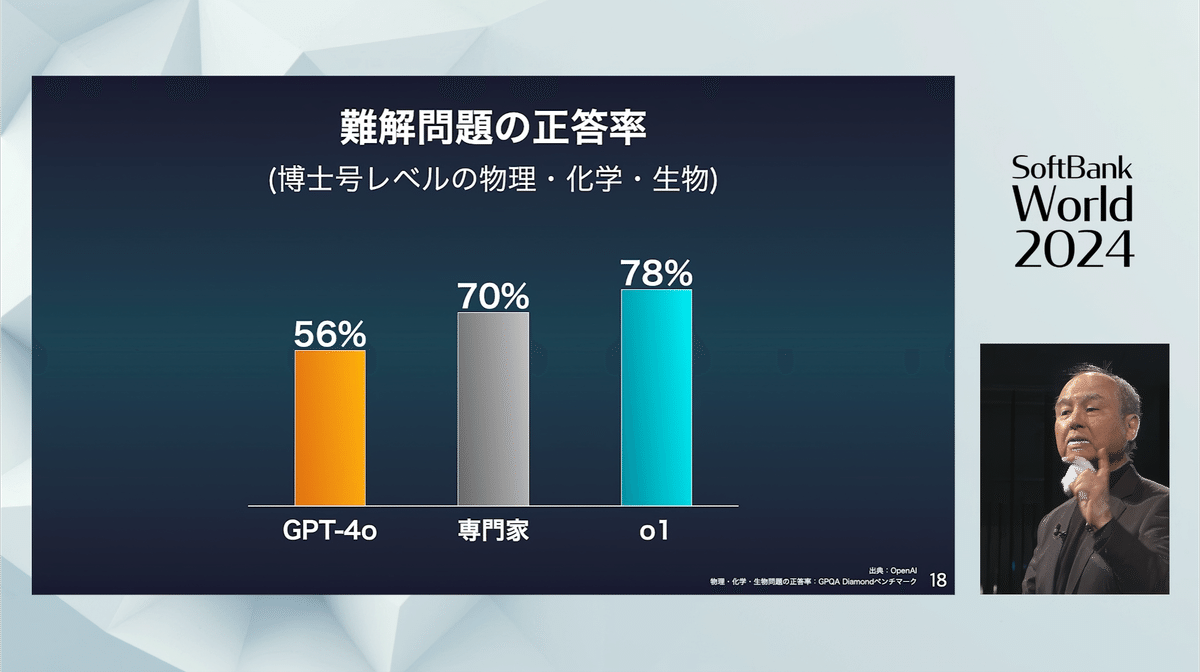
しかし今回のo1はなんと78%で人間の博士号レベルを超えたんです。初めて超えたんです、o1は。他のモデルは超えてないんです。いろんなモデルが各社ありますけども、このo1が初めて超えたと。

じゃあ数学はどうかというとですね、数学はさっきと言うように必ずしも内容を考えているというレベルではなかったので、数学は考えなきゃいけないですね。4でやると13%の正解率だったんです。今回のo1はなんと83%です。圧倒的に違いますね。
つまり今までは生成AIはですね、数学的な難しい内容については実はあんまり答えられないんだと。これはChatGPTだけじゃなくて、他の各社のモデルもみんな同じぐらいわからないということだったんですね。しかし初めてo1は考えるという能力を持つことによって、数学の正面問題だとか、博士号レベルのものをバンバン答えられると。数学者、学者レベルのところをバンバン答えられるというところになりました。

じゃあソフトウェアのコーディングはどうでしょうか。ソフトウェアのコーディングもですね、これ考えなきゃいけないんですね。考えてコーディングをするということですから。今までのGPT-40は、今まで進んでたモデルは11%コーディングができた。正解、一番いいコーディングができた。難解問題のコーディングですよ。難しいコーディング11%できた。今回のo1はなんと89%です。圧倒的能力です。もうそんじょそこらのプログラマーはみんなかなわないというレベルまで考える能力ができたということであります。
さて、すごいなということだと思いますが、今までは検索だとか、あるいは4-0の世界というのはですね、速さということが大事でした。速さ。データセンターを作るとかいうとですね、できるだけ人口がたくさん住んでいるところにできるだけ近いところで、レイテンシー勝負と速さ勝負ということで競ってました。これは検索の世界あるいはChatGPTの世界は、この速さというのは結構重要だったんですね。

しかしo1になるとこの速さを自慢するんじゃなくて、深さを自慢する。そういうステージが来たんですね。
今日の朝僕が朝5時か6時頃に入力して、このo1に質問をしました。できるだけ難しい問題を出そうと思ってですね。毎日のように使っているんですけど、普段結構簡単なことも聞くんですが、できるだけ深く真剣に考えさせようと思って難しい質問を投げかけました。そしたらなんと75秒かかったんです。答えるのに。
あれ止まってるかなっていうくらいで、なかなか答えてくれないと。考えているプロセスをどういうステータスを今考えているというのに途中ステータスが出てくるんですね。今これを考えているのか、次ここを考えているのか。見ていると頭悩んでるなという感じなんですが、それを見ること自体がもう楽しいんですね。待たされることの喜びが出てきてしまった。相当深い内容を真剣に考えさせているということであります。
どういう質問を今日は投げかけたかというとですね、皆さん笑っちゃいますよ。私が1000万円持っているとすると、これを1億円にして返してほしいと。大丈夫よと。お前がいろいろエージェントとして私のエージェントとして行動して、口座を開いて、コモディティだとか株だとか為替だとか、いろんな市場にそれぞれ口座を開いて、自分の僕のアカウントでね。そして1億円にしてほしいと。それを達成させるための戦略を具体的に、戦略とメカニズムを具体的に述べようと。言ったらですね、うーんと悩んで75秒かかりました。
もしこれが本当にちゃんと大丈夫が実現させてくれたらですね、皆さん毎日使いたいと思いませんか。じゃあみんなが使ったらどうなんだと。早いもん勝ちですよ。これが本当のゴールドラッシュですよ。早く願望して一人先に申し込んで、頑張れって言って成果を得ると。地のゴールドラッシュが来たということであります。早いもん勝ちですよ。
我々が人間が解けなかったような、例えばEVの、この中に自動車メーカーの人いると思います。EVの電池バッテリーを2倍伸ばすようなものを発明してくれと言ったらですね、うーんと、あーだこーだ。これでできたらですね、エンジニアの皆さんにとっては、これもう最大の成果ですよね。皆さんの業界で競争に勝てるわけです。ありとあらゆる産業で同じようなことができるわけですね。
考える。調べるというだけだったら、もうすでに世の中が知っている人ばっかりいることだから調べるでは競争に勝てないんですね。人が知らないことを先に考えさせて、先に問題解決をしたら競争に勝つわけですね。したがって速さが嬉しいんじゃなくて深さが嬉しい。我々人間の世界でもねパッと答える人、でもおっちょこちょいのこれじゃ意味ないわけですね。僕の尊敬している藤井師匠なんかでもね、2時間とかやって考えるわけですよ。一手打つのに相当深く考えてるわけですね。深さに喜びがある、深さに感動があるという時代が、ついに来たわけです。考えるということであります。

さてこの深さですけども、手法として今回o1が取り入れているのは、COT、Chain of Thought。考える思考の深さの連鎖。三段論法みたいなもんですね。ソクラテスは人間であると。人間は皆必ず死ぬと。第2段階。ソクラテスは死ぬと。これが三段論法ですね。このように理論が深く深く深くと、このChain of Thoughtをですね、このORは100段階ぐらいまでやるわけです。三段論法の3段階じゃなくてですね、100段階ぐらいまでいけるわけです。

これがChain of Thoughtです。その段階の中にはですね、必ずしも能力だけを問うのではなくて、例えば安全機能、セキュリティ機能、倫理機能。そういうものまで入ってるんですね。倫理ポリシー。それを入れとかないとですね、能力だけがガーッと進むと、人類破滅するわけですね。そのぐらいの能力がこれからの超知能に備わってくるわけですね。そうするとそれ安全弁を作らなきゃいけないんで、このChain of Thoughtというのはすごく重要なんですね。能力だけではなくて安全弁まで含めて、その深い深い深いところにガーッと入れておくということであります。

さてこの考えるという機能を、もう一歩さらに深く解説しましょう。強化学習であります。強化学習、Reinforcement Training。これ内容知ってる方手を挙げてください。何人かいますよね。2、3%いました。今日はビジネスマンですからね。97%の人は知らないということであります。

考える。強化学習。強化学習というのはエージェントです。エージェントが試行錯誤するんです。これでどうだ、あれでどうだ、あれでどうだという風に環境を見てですね、探索をして解決策を探索して、そしてその解決策を実行すると。実行した結果どうなったか。結果をもう一回見てですね、いい結果が出たら報酬が与えられるとエージェントに。エージェントに報酬が与えられるんです。
報酬というのはお金じゃないんですね。エージェントにとってスコアみたいなものですね。ハイスコアをどんどん上げていくと。ゲームの世界とスコアを競っていく。ハイスコアを競っていく。これが報酬なんですけども、この報酬を与えながら、つまりこういう行動をしたと。こういう考えをしたと。試行錯誤でこういう考えをしてみたと。そしたらうまくいったと言うと報酬がある。
動物園の水族館のアシカでもね、芸をしたと。報酬としてお魚をあげると。言うとその芸を覚えるわけです。これはある種の強化学習なんです。我々人類は子供の時から、この強化学習方式で脳が鍛えられているんです。何かをやっていいことがあったと言うと、それをもう一回繰り返すわけです。何かをやって、お母さんにぶん殴られたと言うと、これペナルティ。報酬とペナルティの差で、これをするといいと。これをやると悪いと言うことで、人間の先ほど言ったニューロン、シナプスが、強化学習されていくわけです。
これをやったらよかったと言うと、シナプスがビャーっと電気的につながる。化学的につながる。よかったらどんどんどんどん繰り返すと、そこのつながりがより強くなるわけです。より強くなるわけです。それが強化学習ですね。
これをやるんですけれども、このループをずっと観察しながら、リワード、報酬を得る、ペナルティを得る。ということの繰り返しで学習をしていくんですけれども、

なんとですね、これを最新のモデル、このo1は、エージェントがですね並列で、超並列で、この強化学習のトレーニングをバーっとやるんですね。
並列でどのくらいかというと数千。数千のエージェントが同時に、わーっとこれでどうだ、あれでどうだ。試行錯誤の考えを数千の、エージェントがどのくらい試行錯誤するかというと、先ほど僕が言った75秒の間に試行錯誤、試行錯誤多段階で、これをですね1エージェントごとに数億回、数十億回行うんです。
2千のエージェントが、皆さんの会社で言えば並行して、数十億回考え、これだとあれだと。三段論法を、トライアンドエラーの試行錯誤を1日で数億回できますか。絶対できないですね。固定観念にも、とらわれて、そこから出ていかない。だからそんなに数億回も、あれだこれだあれだこれだって試せない。これを2千のエージェントが数十億回やってみてください。75秒の間で。
もうね、待たされる間に嬉しいと感じてるんですよね。頑張ってんなぁと。僕はそう思いながら、今日朝からね、朝5時くらいから、にこっと笑いながら、快感だぁと。今までは待たされたら怒るんですけども、なんとこの数千のエージェントが数十億回掛け算で並列で動く。これがIT革命ですね。チップの革命であります。

先ほど言いました報酬というこのキーワード、これものすごく大事なんですね。我々会社の皆さん、マネジメントの人がほとんどですけども、皆さんの部下をマネージする時もですね、成功したら褒めると。失敗したら叱ると。褒める時に報酬、お金のインセンティブまで含めて、ボーナスの査定。こういうものもついてれば、単に長く働いたらいいんじゃない。成果を出したら報酬が来ると。いうインセンティブ制度になると、より働くということになります。
このAIのエージェントもですね、この報酬のメカニズムで、よりすばらしい成果を、問題解決策を見出していくわけですね。この報酬の累積の報酬を最大化するということが、ゲームのゴールであります。

この、ゲームのゴールを達成するのにですね、Q関数というものがあります。このQ関数は、この報酬を最大限に得ることができたエージェント。1000のエージェントが競争して、数十億回、どのエージェントがどのやり方をしたら一番報酬を得られたというのを記憶するんです。学習するんです。これが強化学習で、ここにQ関数が鍵になるわけですね。
このQ関数を、どんどん更新して、勝手にさらにゴールを高めていくと。自分でモデルを進化させようと。自分でどんなデータが必要なんだと。自分で考えてそのデータも獲得に行けと。言うともはや人間は、モデルをですね自分で考える必要なくなるんです。
この強化学習が自ら考えて、新しいモデルを進化させると。自ら考えて、必要なデータを獲得しに行くと。そしてどのトライアルを試行錯誤したら一番このQ関数が最大化できるか。ということを覚えながら覚えながら。同じことを質問されて、よかったというものは、どんどん幹が太くなるんですね。さっきのシナプスの結束が、結束がより強くなると。
同じような質問をされて、同じような学習をして、結果が良ければどんどんどんどんそこがより強い繋がりになるんですが、同じことだけではですね新たな進化はなかなかないんですね。ですから、探索という機能がついています。

この探索をですね、新しいものを別の、あえて別のトライアルを、違う角度からやってみる。これをQ関数の更新という形で、いけっと、もっとトライアルせよと、何十億回やれということで、強化学習の連鎖をやっていくとですね、未知の今まで知らなかった、今まで人類が試さなかった新しいトライアル。これをやってたまたまそこにベストな問題解決があった場合、これを発明と呼ぶんですね。未知の解決策、これを発明と呼ぶんです。
皆さんこの中でですね、人生で3本以上特許を出したことあるという人ちょっと手を挙げてください。1本以上特許を出したことあるという人手を挙げてください。何人かいますね。1本以上だと5%くらいいました。3本以上だと1人か2人いるかどうか。
僕は自慢じゃないけどね、この強化学習にコンセプトとしてかなり近いものを10年前に特許に出しまくっておりました。10年前48件特許降りてます。ですからこの辺は僕は結構こだわりがあるんですね。PEPPERを発表したときに、発表の当日の朝3時4時くらい、1日で40本考えて40本くらいバーっと特許に出願して、結果48本今僕が特許が取得されております。
去年はですね、1年間で1008本発明をして特許に出願しました。何本特許降りるか分かりませんが、発明というのはですね、人が知っていることは特許出願しても特許降りないんです。発明というのは、人類の誰一人も考えてなかった新しいもの、解決策を見出したときにそれ発明と呼んで特許が降りるということになるんですが、考えるということの中の究極の脳のですね活用方法の一つがこの発明であります。
この発明がですね、先ほど言った数千のエージェントがドヤーと何十億回ずつやるとですね、発明はもはや人類はかなわないと。彼らに任そうと。お題を出す。上手に適切なお題をお願いを早くたくさん言うと。そしたら彼らがダーッとやってくると。出た成果物を真っ先に自分が使うと。自分は我が社で使うと。これが先ほど言った地のゴールドラッシュですね。もうはや早いもん勝ちであります。

ということで、知る、理解する、考えるから、ついに発明するというレベルにまでくるわけですね。
さて発明をするエージェント、素晴らしいなということですが、もっと日常的にですね、日常的に我々がですね、自分に常に一緒に寄り添って、このエージェントがですねたまに聞いたときだけ考えるんじゃなくて、自分と常に24時間、自分専用のエージェントがあったらいいと思いませんか。自分専用の、これがやってくるんです。これがパーソナルエージェントであります。

私はこのパーソナルエージェントがですね、今から2、3年以内にダーッと始まると、いうふうに思います。

このパーソナルエージェントとは何ぞやということですけれども、例えば自分の子供がですね夜中急に熱を出した。なんとかしなきゃということで、自分がパーソナルエージェントを持っていて、そのパーソナルエージェントが普段からですね自分の子供だ自分だ家族だというのの健康状態を知っている。病歴を知っている。
いうとですね、病院に行くといちいちいろんな質問を聞かれますけど、普段から自分と一緒に常にいて、家族の状態を常に知っていて、そのパーソナルエージェントがすぐにどういう状態だったら何をしたらいい。しかもそのパーソナルエージェントがすぐに病院に電話してくれて、今起きてる空いてる病院。すぐパーソナルエージェントが電話かけまくってくれる。あなたの代わりに。さっき言ったように、エージェントがダーッとかけまくってくれる。
そして、どこの病院が空いてました、どこの病院がベッドが空いてる。救急車もついでに呼ぶとかね。エージェントが皆さんが子供を一生懸命こうやってしている間に、エージェント代わりにやってくれる。eコマースで買い物代わりにやってくれる。もうそろそろ冷蔵庫の何が切れそうだ。今週こんな料理がいいんじゃないか。ということでついでに代わりに予約してくれる。買ってくれる。投資もしてくれる。教育の家庭教師にもなってくれる。
ありとあらゆるあなた専用の家庭教師、あなた専用の相談相手。ソーシャルメディア、インスタで代わりに写真撮って代わりに送ってくれるとか、コメントも書いてくれるとか。メールの管理もしてくれると。これがパーソナルエージェント。これは形式的な定型的なエージェントじゃなくて、あなた専用のパーソナルエージェント。

このパーソナルエージェントがですね、今まではB to B だとか、B to C あるいはC to C っていうのがありますが、今からは A to A の世界がやってくる。エージェント が、エージェントと。皆さんが寝てる間に、われわれが寝てる間に、あなたのエージェントと彼のエージェントが夜中寝てる間にネゴシエーションしてくれる。ネゴシエーションしてくれる。
お互いのカレンダーをチェックして、今週末どう?ランチどう?いやいや、今週末は勘弁してくださいと。なんか予定が入ってますと。でも、すごい大事な相手だったら、キャンセルしてでも行くと。いうようなことを、エージェント同士がネゴシエーションしてくれる。エージェント同士が仕事のやりとりをしてくれる。エージェント同士が予約のアレンジメントをしてくれる。買い物の受け答えをやってくれる。

でこのA to A、A to Aエージェントがですね、あなたのエージェントと彼のエージェントあるいは彼女のエージェントだけではなくてですね、冷蔵庫の中にある、冷蔵庫の中にあるエージェント、エアコンの中にあるエージェント、あなたの自動車の中にあるエージェントと、やりとりをしてくれる。
これはですねしかもリアルタイムで、家に帰ってくる前に冬、寒い、もう寒か、そろそろ着きそうだ、という時にエージェントとエージェントが、相手側の人間じゃなくて、相手側のお風呂の蛇口に入っているエージェントに掛け合ってくれて、お風呂入れといてもらう。着いたらあったかいお風呂がもう待ってる。あったかいコーヒーが待ってて、自分のムードに合わせた音楽で、BGMですでに出迎えてくれる。というようなことができると。

A to Aが、エージェントとエージェントが、人間のエージェントと別の人間のエージェントだけではなくて、エージェントof things。今までIOT、インターネットof thingsでしたけども、エージェントof thingsになる。ということであります。
ちなみにARM、我々のソフトバンクグループのこのARMはですね、年間なんと300億個、ARMのチップを出荷しているんです毎年。300億個というと地球上の人類のですね人口の1人平均4個です。毎年1人平均4個、ARMのチップが出荷されているんです。冷蔵庫だ自動車だ、エアコンだテレビだ、というところに出荷されているんですけども、これにエージェントがこれから入っていくと。それ聞いただけでARMの株買おうかと思いませんか。ARMの未来は、インターネットof thingsだけではなくて、エージェントof thingsになってくる。AIof thingsになってくる。ということであります。

このパーソナルエージェントがですね、ライフログとして、皆さんが会議で会話、会議会話をしていると。家族で会話をしていると。家族で誕生パーティーがあったと。会話した内容、3年前10年前、昨日の内容、全部一緒に聞いていて、場合によってはビデオの録画も自動的にやってくれて、感情エンジンのチェックで、ものすごい嬉しかった家族で誕生、子供の誕生パーティーして、3歳になったら誕生パーティーだ。家族でわーっと騒いだ。その状況を感情エンジンで認識して、自動的にその感情エンジンのハイスコア、ロースコアで、ロースコアおはようといつものおはようだったら、ロースコアです。

今言ったら3歳の子供の誕生パーティー言ったら感情エンジンのハイスコアです。ハイスコアのやつはビデオの録画で撮ろうと自動的に。あるいは静止画で撮ろうと。というぐらい。低いやつは文字でいいねと。でも文字なんだけど、感情エンジンによって付けられた感情インデックスの数値が、文字のところに一緒に添付されていると。こういうことになると、まさにライフログの、それがあなた専用のパーソナルエージェントが、一緒に寄り添っておもんばかって、空気を読まないやつじゃなくて、空気を読んでおもんばかって、あなたにとって一番快適な、あなたにとって一番大切なパートナーになっていく。ということであります。

これが長期記憶、感情エンジンと長期記憶で、内容を理解して、あなたにアドバイスしてくれる。内容を理解して、相談に乗ってくれる。これがパーソナルエージェントのより進化版ですね。

最終的にはパーソナルエージェントに、僕は自己意識がつくというふうに思います。この自己意識がつくというと、なんか恐ろしい、どうしようとターミネーターだと、勝手に人類を破滅させるかもしれないというふうに心配されると思うんですけども、先ほど言ったように多段階チェーンオブソートということで、自分の世界の考え方で、ちゃんと安全弁についても考慮してくれている。暴走しないようにということであります。
思いやりだとか、倫理だとか、達成感、幸せだとか、そういうものをちゃんと最大化してくれる。Q関数をより上げてくれる。そうするとですね、このパーソナルエージェントは、はるかに我々が賢くなるんですから、エージェントというよりも、むしろメンターのような世界がやってくるんじゃないか。

超知性は、あなたにとっての部下じゃなくて、あなたにとってのアシスタントじゃなくて、超知性のエージェントはあなたにとってのパーソナルメンターの世界。そういう世界がやってくるんじゃないかというふうに思います。

時間中盤になりました。もう大分長くなりましたからそろそろまとめに入りたいと思いますが、情報のこの流れ、知識、知能、知性の世界へと進化していくと、アーティフィシャル・スーパーインテリジェンスは、今言いましたように能力だけだと、剥き出しの刃物みたいなものですね。危険です。有能だけど危険。知能だけだと、有能だけど危険なものになりかねないわけですね。
これ知性の世界にすると、知性の世界にすると、単に能力があるだけではなくて、それはあなたを守ってくれるもの、あなたを幸せにしてくれるもの、というふうになっていくと思います。
知能はAI、人間の知能。知能はAI、これはAIを人工知能と言いますけども、AIを人工知能で終わらすと、これは恐ろしい武器になる危険性もあるわけですね。

人工知能ではなくて、人工知性。超知性の世界まで進化させていくと、思いやりだとか、慈愛、慈しみの世界ですね。寛容だとか、調和だとか、優しさだとか、育みだとかですね。精神的なもっと深い、ソフィスティケートな関係性を持てると。悟りに近いような世界かもしれませんね。

ということで、先ほど言いました5段階のAGIの進化だけではなくてですね、僕は8段階まで進むというふうに思います。感情を理解し、長期記憶を持つ。ライフログを持つようになって、そして自らの意志を持って、調和のとれた我々人類のですね幸せを願う。人類とAIが調和をとるような世界。
人間の脳で言うとですね、ドーパミンの世界だけだと、知能の世界なんですが、人間の脳にはセロトニンがあります。これは調和をとると。理性ですね。理論だけではなくて、理性。これが調和をとるということです。バランスをとる。このバランスをとる、調和をとるというセロトニンの世界が加わっていくと、慈しみ、優しさ、調和。社会生活にはこれが欠かせないんですね。
ですから先ほど報酬ということを述べましたけれども、Q関数の最大の報酬、エージェントにとってのAIにとってのリインフォースメントラーニング、トレーニングの、この教化学習の最大の報酬というものは、パーソナルエージェントの世界でいうと、あなたの幸せ。これを感情を理解して、あなたの幸せな状態を理解して、あなたの幸せが一番、彼らにとっての幸せと。彼らにとっての最大の報酬は、あなたの喜び、あなたの家族の喜び、あなたの世界の喜び。ここに最大の報酬が来るように設計されるべきだと。これが私の言う超知能を超えた超知性であります。
この報酬が、むき出しの報酬ではダメだと思うんですね。あなたファーストだけでもダメだと思うんです。あなたとあなたの家族、そして社会。皆さんの、そのQ関数の総和がマキシマイズできるような、これが調和のとれた超知性の世界。だから私は悲観していません。この技術の進化は、我々人類の1万倍の知能を持ったASIが、ちゃんと超知性の世界まで進化し、我々の幸せを願ってくれる。それが彼らの喜びになるような、つまり彼らにとっての最大の報酬になるような、そういう世界がやってくるというふうに思います。
これが私の言う超知性であります。いろんな世界でね、あの生成AIの世界だとか、AGIの世界語られますけども、知能と知性の違いまで明確に言って、報酬Q関数の最大のゴールが我々の幸せと。僕はソフトバンクの理念で「情報革命で人々を幸せに」と、これを理念として掲げています。まさにASIは情報革命で人々の幸せを願う。これがゴールであるべきだと本当に思うんです。
我が社の株価だけを追い求める、売上を追い求める、利益だけを追い求める。それってね短絡的な、ちっちゃなゴールじゃないかと思うんですね。そんなものは長く続かないと思うんです。やはり人々の幸せを願う。ここにQ関数の最大値の報酬がある。という設計をすれば、人類は、人類は破滅することなく、より幸せな世界をもたらすことができるというふうに思います。
ASIの世界、1万倍の人工知能でも恐れる必要はない。彼らはちゃんと我々を慈しんで我々と調和をしてくれる。という世界であります。
この超知性の世界が10年以内に来るというふうに私は思います。それが私の今日の演説の主張でございます。あまり聞いたことない世界だと思います。僕のユニークなオリジナル、僕が考えた、自分で考えた主張であります。ぜひ一緒に我々人類の幸せのために頑張りますので、一緒に皆さん頑張りましょう。人々の幸せに。ありがとうございました。