
資格試験の勉強で「過学習」が起きていませんか?

以前、縁あって機械学習やそれに関するプログラミングを1年ほど勉強したことがあるのですが、その際に登場した機械学習における重要な概念「過学習」が、実は人間の試験勉強でも起きているのではないか?と思い、私なりの考えをまとめてみました。
ちょっと分かりにくいところがあるかもしれませんが、思い当たる節がある方にとってのヒントになれば幸いです。
(機械学習における)過学習とは
過学習は最近流行りの機械学習で登場する概念で、Wikipediaでは以下のように説明されています。
訓練データに対して学習されているが、未知データ(テストデータ)に対しては適合できていない、汎化できていない状態を指す。
AI(人工知能)で着目される機械学習では、あらかじめ大量のテストデータ(学習データ)を学ばせ、データの傾向などをコンピューターが学ぶことで、新たなデータに対しても的確な答えや予測を導き出そうとします。
(ここから先は、イメージしやすい架空のデータを用いて説明しています。あらかじめご了承ください。)
例えば、アイスクリームの売上は気温に大きく影響されるらしく、気温が25℃を超えると売上が急激に伸びるそうです。ただし、気温が32℃を超える辺りから、「そもそも買い物に出かけたくなくなる」「暑すぎて食欲がなくなるためにアイスクリームより氷菓子が好まれる」といった理由から、売上が減少するそうです。
(上述の通り、あくまでもイメージですが)あるコンビニエンスストアの気温とアイスクリームの売上を、気温を横軸、売上を縦軸にとったグラフにプロットすると以下の図のようになったとしましょう。
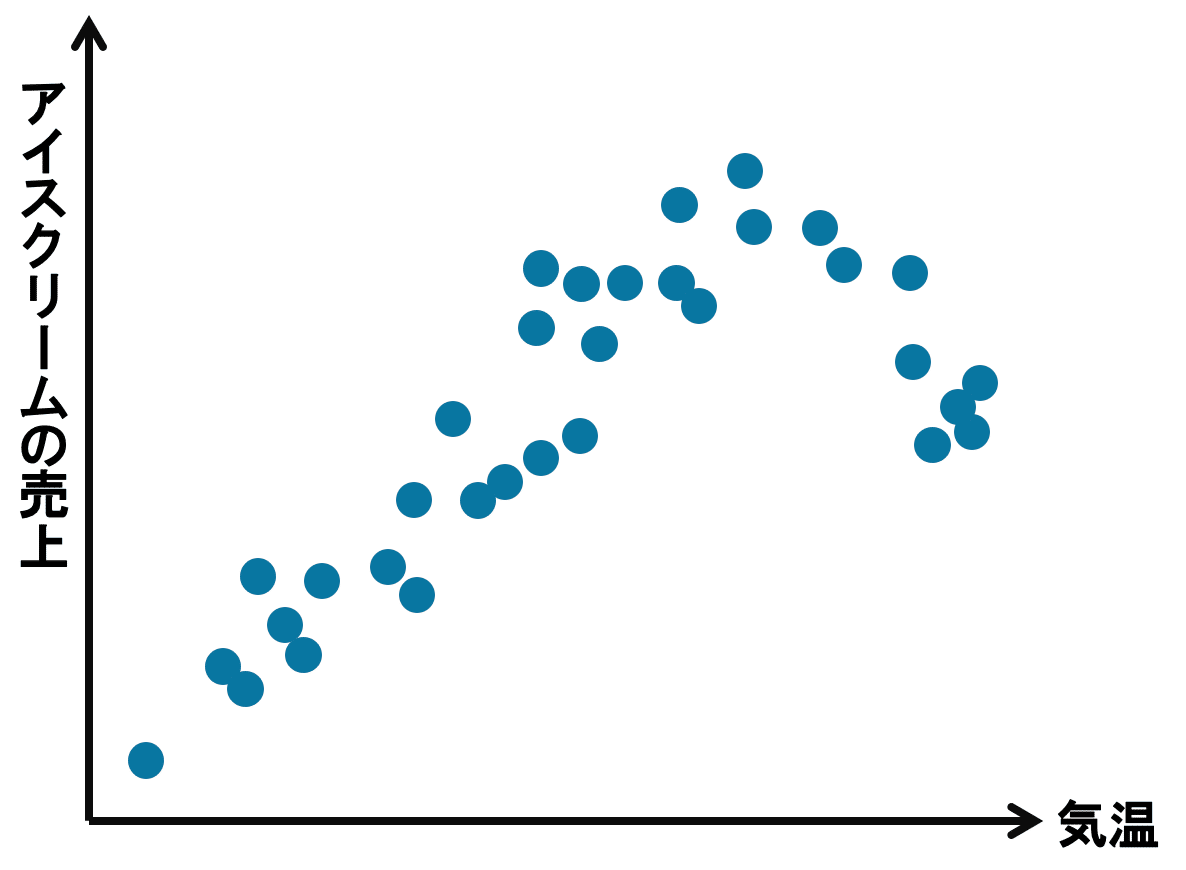
気温が高くなるにつれて売上が増えていますが、気温がある温度よりも高くなると段々と売上が減っています。
この結果から分かる"傾向"をフリーハンドで示すと、以下のような曲線になるはずで、おそらくこの感覚は多くの方にとって最も自然と受け入れられるでしょう。

機械学習では、このような傾向を大量の学習用のデータと高速で計算できるコンピューターで学習し、適切な傾向を掴んで未来の予測などを行う訳ですが、上記のような傾向線を導き出したとしても、個々のデータと傾向線の間にそれなりの誤差が生じてしまいます。
ただし、その誤差はある程度許容した方が、適切な傾向を掴んで将来の予測に役立つとされています。
それもそのはずで、この例で言えば、アイスクリームの売上について気温という1つの要素しか考えていないために誤差が生じていると考えるのが自然だからです。
いくら気温が(ちょうど良い感じで)高くてアイスクリームが食べたくなる気候でも、雨が降っていれば面倒くさくて買いに出かける人が減ってしまえば、売上も減ってしまうはずで、そういった事情が誤差として現れるのは当然のものと言えます。
例えば、気温が30℃の日の売上が50個であるのに対し、30.5℃の日の売上が20個しかなかったとしましょう。
気温だけ見ると違和感しかありませんが30.5℃の日が大雨で、そもそもの来店者数が少なかったといった理由があるかもしれません。
では、もし誤差をもっと少なくしようとすると、どんな傾向線となるのでしょうか。
例えば、「もっと誤差がもっと小さくなるようにして分析して。もっと複雑でいいから。」と言う前提でコンピュータに解析させると、次のような傾向線とグラフの数式をコンピューターが導き出すことがあります。

こうすると、その前に示したグラフよりも個々のデータと傾向との間の誤差が小さくなり、数式的には「より適切に傾向を捉えている」ことになるのですが、果たしてこの傾向線で、将来を適切に予測したり、新たに追加したデータに適切に対応できるでしょうか?
その答えはNOで、仮に学習用のデータでは上手く傾向を説明できたとしても、その分析結果自体は将来の予測や現実の分析には全く役立たないものになります。
上述のように、気温が30℃の晴れの日の売上が50個であるのに対し、30.5℃の雨の日の売上が20個しかなかった場合に、無理して気温だけで売上が減った原因を説明できるようにしようとすると、複雑な算式でチグハグな傾向線を導き出そうとそてしまいます。
こうして気温だけで説明がつくようにした結果、現実離れした仮定となってしまうため、学習した傾向に基づいて予測をしたり、将来に備えようとしても、まったく参考にならない学習となってしまいます。
このように、学習データの誤差が小さくなることを重視しすぎた結果、学習の場面では上手く行っているように見えるのに、正しく傾向を捉えることができずに、その後の分析や解析に役立たないような学習をしてしまうことを『過学習』というのです。
(受験勉強における)過学習の存在
上で書いたのは機械学習でコンピューターが(本当はその機械学習のプログラムをしたプログラマやエンジニアが)陥る過学習ですが、受験生の方々のご質問やご相談に対応していると、私たち人間の受験勉強においても、同じような過学習があるように思うことがしばしばあります。
特に「過去問題集を中心とした問題集ばかり解いている」という勉強スタイルで、この過学習"的な"状況になってしまっているようなケースが散見されています。
もちろん、問題集を解くこと自体がダメという訳ではなく、問題を解いて答えや解説を見ているものの、認識している範囲が解いた問題だけになっていて、俯瞰で見たような本質が見えていない場合に、このような過学習"的な"状況ってしまうように見ています。
このような状況になってしまうと、機械学習したコンピューターが新たに追加されたデータに対して適切な予測や分析ができないのと同じように、新たに解く問題に対して適切な解答が導けなくなってしまうことになってしまいます。
よくある「問題の答えを覚えるくらい解いたのに、本試験で見たことがない問題には対応できずに点数が伸びない」というお悩みの原因は、この過学習”的な"状況ではないかと考えています。
前述のように、例えば、気温が30℃の日の売上が50個であるのに対し、30.5℃の日の売上が20個しかなかった場合に、「30℃から30.5℃に気温が上がるときだけ売上が減ってしまうから、注意しておこう」のような誤った捉え方をする上に、覚えるべきこと、注意すべきことを自ら増やしてしまっているのかもしれませ。
もし、このような状況になってしまっている方は、コンピューターと同じような過学習"的な"状況になっていないかを、冷静に分析してみるとよいでしょう。
基本を正しく押さえることの大切さ
問題演習をすることは必要不可欠で大切なことですが、問題のレベルや性質によっては、解いている問題の条件や指示、内容が必ずしも基本通りとは限りません。
しかし、そうした違いを考慮せずに、すべての問題に無理やり当てはまるものを考えようとするのは、下記の図ように、ぱっと見ではおかしく見える傾向を「基本的な考え方だ」と捉えてしまうような状況に陥っているのかもしれません。

図で考えると「あり得ない」と思われるかもしれませんが、受験生の方のお悩みを聞いていると、解いた問題の条件や計算の内容を整理するために、このような状況になってしまっているようなケースがたまに見受けられます。
ただ、実際にはそんなことはなく、基本的な考え方や計算はもっとシンプルだけれども、実際の試験問題は「未処理や誤処理」を付け加えたり、「その問題特有の事情」を付け加えたりして、シンプルな基本からわざとズレているような状況を作っているだけだったりします。

問題を解いていると、テキストなどに載っている基本的な仕訳例や計算例とズレているように見えることもありますが、現実世界でも、いろんな条件や状況が加わったり、別の要素も加味する必要があったりして、基本通りにいくことばかりではありません。
試験問題も、(特に級やレベルが高くなると)基本を押さえていることを前提に、状況による対応力や応用力を試すために敢えて基本から少し外れた問題を出すこともありますが、それを「基本」だと勘違いして過学習"的な"状況になってしまうと、段々と迷子になってしまい、「問題を解いても解いても、初見の問題への対応力がつかない」という悩みにつながってしまうのではないかと考えています。
機械学習の場合は、コンピューターによる計算で未知の傾向を導き出そうとするため、どうすれば過学習を回避できるのかということもあらかじめ考えなければなりませんが、試験勉強の場合、ここまで見てきたグラフの事例のようなシンプルな傾向線は「テキスト」や「基本問題集」などに既に載っているものと考えることができます。
上記のような悩みを抱えている方は、本試験レベルの問題を解いたあと、その内容が「基本どおり」または「基本に近い」内容なのか、それとも基本から「わざとかけ離れている」問題なのか、テキストなどとも照らし合わせながらきちんと見極めることを試してみてはいかがでしょうか。
私が担当している日商簿記1級WEB講座に興味がある方は、以下のリンクから講座の詳細をご確認頂けると嬉しいです。