
iOS による姿勢推定

以下の記事を参考にして書いてます。
・Detecting Human Body Poses in an Image
1. はじめに
このサンプルは、PoseNetモデル を使用してカメラ画像から姿勢推定を行う方法を示しています。PoseNetモデル は、17の異なる身体パーツまたは関節(目、耳、鼻、肩、腰、肘、膝、手首、足首)を検出します。
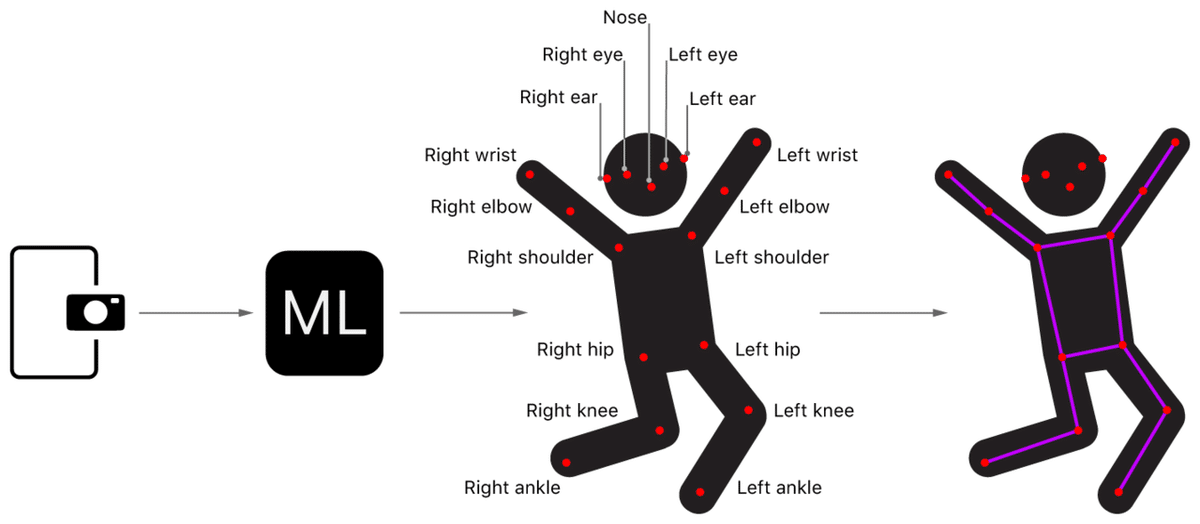
サンプルは、画像内の各人の17関節の位置を見つけ、その上にワイヤーフレームを描画ています。
【注意】
「iOS 13以降」が必要です。
2. キャプチャセッションの設定
サンプルは、AVCaptureSession を使用してカメラ映像を取得することから始めます(キャプチャセッションを参照)。
if captureSession.isRunning {
captureSession.stopRunning()
}
captureSession.beginConfiguration()
captureSession.sessionPreset = .vga640x480
try setCaptureSessionInput()
try setCaptureSessionOutput()
captureSession.commitConfiguration()3. キャプチャした画像の取得
キャプチャセッションは、各画像を VideoCapture の captureOutput(_:didOutput:from:) に送信します。サンプルは、受信した CMSampleBuffer を CGImage に変換してから、VideoCapture に割り当てられたデリゲートに渡します。
// メモリにアクセスするため PizelBuffer をロック
guard CVPixelBufferLockBaseAddress(pixelBuffer, .readOnly) == kCVReturnSuccess
else {
return
}
// CGImageのプレースホルダの準備
var image: CGImage?
// PixelBuffer から CGImage を生成
VTCreateCGImageFromCVPixelBuffer(pixelBuffer, options: nil, imageOut: &image)
// PixelBuffer を解放
CVPixelBufferUnlockBaseAddress(pixelBuffer, .readOnly)
// デリゲートに渡す
DispatchQueue.main.sync {
delegate.videoCapture(self, didCaptureFrame: image)
}4. PoseNetモデルの入力準備
キャプチャされた画像を受け取った後、サンプルはそれを PoseNetInput にラップして、指定されたサイズにリサイズします。
// 画像のリサイズ
let input = PoseNetInput(image: image, size: self.modelInputSize)5. PoseNetモデルの入力
次に入力を PoseNet の prediction(from:) に渡して、姿勢検出の出力を取得します。
guard let prediction = try? self.poseNetMLModel.prediction(from: input) else {
return
}次にサンプルは、モデルの入力サイズと出力ストライドと共に、PoseNetモデルの出力を PoseNetOutput にラップしてから、分析のために割り当てられたデリゲートに渡します。
let poseNetOutput = PoseNetOutput(prediction: prediction,
modelInputSize: self.modelInputSize,
modelOutputStride: self.outputStride)
DispatchQueue.main.async {
self.delegate?.poseNet(self, didPredict: poseNetOutput)
}6. PoseNetの出力を分析して関節を特定
サンプルでは、2つのアルゴリズムのいずれかを使用して、1人または複数人の関節を検出します。
単一人物アルゴリズムは、最も単純で最速で、画像内の最も目立つ関節を見つけ、これらの関節を使用して姿勢検出を行います。
var pose = Pose()
// 各関節の最も大きいセルを検索して位置と信頼度を検出
pose.joints.values.forEach { joint in
configure(joint: joint)
}
// 姿勢の信頼度を計算
pose.confidence = pose.joints.values
.map { $0.confidence }.reduce(0, +) / Double(Joint.numberOfJoints)
// 関節の位置を元画像にマッピング
pose.joints.values.forEach { joint in
joint.position = joint.position.applying(modelToInputTransformation)
}
return pose複数人物アルゴリズムは、最初に開始点となるルート候補を検索します。ルート候補を使用して隣接する関節を見つけ、各人の17の関節すべてが見つかるまで処理を繰り返します。たとえば、アルゴリズムは信頼度の高さで左膝を見つけて、その隣接する関節で左足首と左腰を検索します。
var detectedPoses = [Pose]()
// 信頼度の高いルート候補を反復
for candidateRoot in candidateRoots {
// 既存の姿勢に割り当てられている関節は無視
let maxDistance = configuration.matchingJointDistance
guard !detectedPoses.contains(candidateRoot, within: maxDistance) else {
continue
}
var pose = assemblePose(from: candidateRoot)
// 既存の姿勢からの重複しない関節の合計を関節の総数で割ることにより姿勢の信頼度を計算
pose.confidence = confidence(for: pose, detectedPoses: detectedPoses)
// しきい値より信頼度が低い姿勢は無視
guard pose.confidence >= configuration.poseConfidenceThreshold else {
continue
}
detectedPoses.append(pose)
// 十分姿勢が検出された場合は終了
if detectedPoses.count >= configuration.maxPoseCount {
break
}
}
// 事前に計算された変換行列を使用して関節の位置を元の画像にマッピング
detectedPoses.forEach { pose in
pose.joints.values.forEach { joint in
joint.position = joint.position.applying(modelToInputTransformation)
}
}
return detectedPoses7. 検出された姿勢を可視化
サンプルは、検出された姿勢ごとに、入力画像の上にワイヤーフレームを描画し、関節間の線を接続してから、関節自体の円を描画します。

let dstImageSize = CGSize(width: frame.width, height: frame.height)
let dstImageFormat = UIGraphicsImageRendererFormat()
dstImageFormat.scale = 1
let renderer = UIGraphicsImageRenderer(
size: dstImageSize, format: dstImageFormat)
let dstImage = renderer.image { rendererContext in
// 現在のフレームを新しい画像の背景として描画
draw(image: frame, in: rendererContext.cgContext)
for pose in poses {
// セグメント線を描画
for segment in PoseImageView.jointSegments {
let jointA = pose[segment.jointA]
let jointB = pose[segment.jointB]
guard jointA.isValid, jointB.isValid else {
continue
}
drawLine(from: jointA, to: jointB,
in: rendererContext.cgContext)
}
// セグメント線の上の円として関節を描画
for joint in pose.joints.values.filter({ $0.isValid }) {
draw(circle: joint, in: rendererContext.cgContext)
}
}
}