
【AIアップスケーラー】 カクダイV1の詳しい解説 (Part 3/3)

AIアップスケーラーのデモ、背景の解説については、以下の記事に書きましたので、未読の方はご覧ください!
本記事では、カクダイV1について、開発者やクリエイターの方向けにより踏み込んだ解説を行っていきます。
様々なAIアップスケーラーと要素技術
せっかくなので、Hires.fixから始めて、Ultimate SD Upscaler、TiledDiffusionなどのお馴染みの手法から、Iterative Upscaler、Ultra Upscaler、CCSRモデルなどの最新かつややマニアックな手法まで一気に紹介していきたいと思います。
既知事項に関しては、適宜読み飛ばしながら進んでください。
Hires.fix
WebUIにbuilt-inで搭載されていたアップスケーラーで、知名度や利用者が非常に多いものです。ComfyUIのワークフローでは次のようになります。

txt2imgで画像を生成した後、潜在空間上で得られた出力を nearest-exact(最近傍法)や bicubic 法などの古典的な補間アルゴリズムを用いて拡大し、再度Stable Diffusionを用いて、img2imgを実行することで高解像度の画像を得ます。
ただし、この方法では古典的な補間アルゴリズムを経由せざるを得ないため、出力の品質はそれほどよくありません。そこで、より高品質な高解像度化を可能とするGANを利用するために、以下のようなバージョンも利用されています。

こちらでは、txt2imgの出力をVAEデコーダーを用いて、一度ピクセル画像に戻すことで、GANを利用できるようにします。GANを用いて拡大した後は、VAEエンコーダーでエンコードし、再度Stable Diffusionによるimg2imgを実行します。
こちらのバージョンでは、計算時間がよりかかる代わりに品質の高い高画質化が可能です。
補足:GANについて
Hires.fixに限りませんが、高画質化を行うGANとしては、2021年に提案されたReal-ESRGAN ベースのモデルが広く使われています。
様々なバージョンや重みが作成されており、AnimeSharpやRemacriやUniversalUpscalerV2など生成AI界隈で有名なモデルもほとんどReal-ESRGAN派生です。
ただし、CC-BY-NC-SA-4.0 ライセンス(つまり、商用利用不可)のモデルも多く、注意が必要です。
上記では、UniversalUpscalerV2のみWTFPLが付与されており、商用利用可能になっています。
Ultimate SD Upscaler
Hires.fixの欠点として、多大なGPUメモリを消費することがあげられます。さらに、非常にサイズの大きい画像にStable Diffusionを適用しているために、本来のポテンシャルが発揮されにくいという問題もあります。
そこで登場したのが、Ultimate SD Upscalerです。こちらは、WebUI、ComfyUIのワークフローともに広く用いられているAIアップスケーラーです。
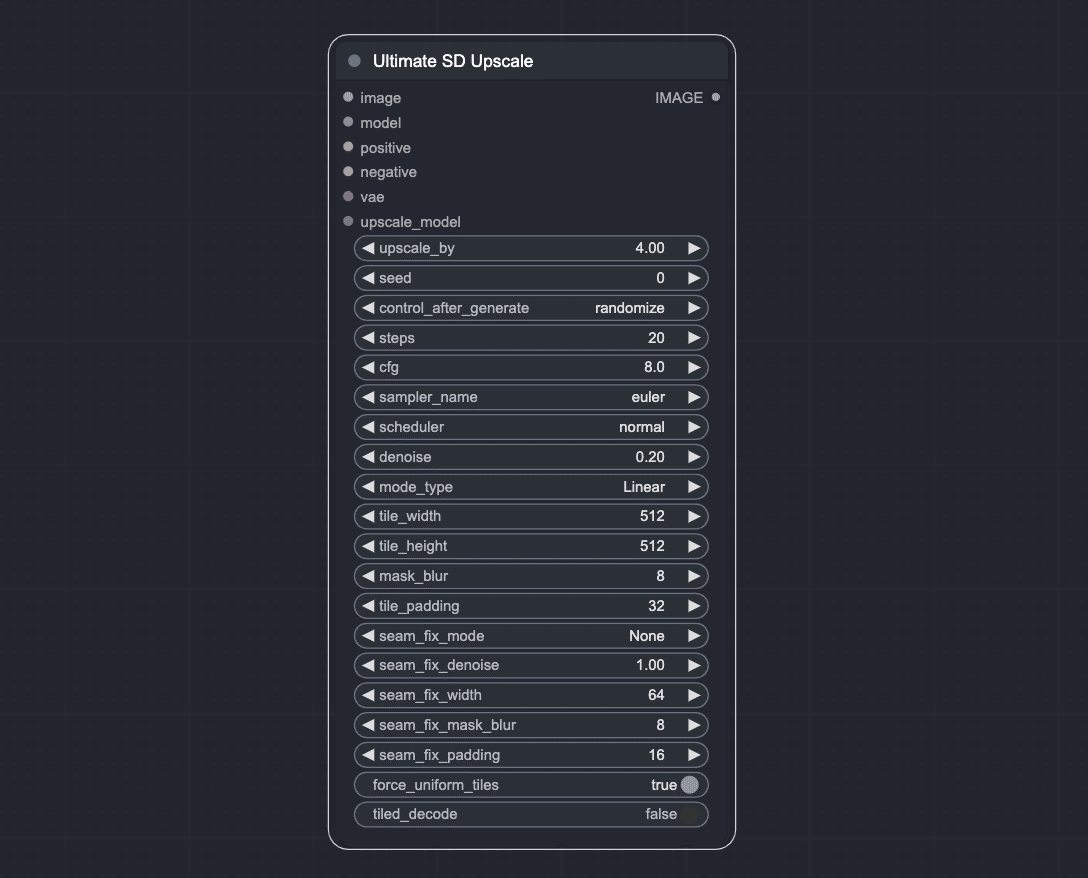
基本的なフローは次のとおりです。
Real-ESRGAN などのGANベースのアップスケーラーなどを用いて、画像をピクセル空間で拡大
その後、ベースモデルに合わせた画像サイズになるように分割(Stable Diffusion1.5なら512x512など)
各タイルに対して Stable Diffusion img2img による詳細化を行う
最後に各タイルを合成する(この際、タイル線が画像に入らないように工夫するオプションが用意されています)。
このようなタイル化処理によって、一度に消費されるメモリを削減しつつ、Stable Diffusionの得意な画像サイズに対してimg2imgを適用させることができ、Hires.fixの問題点が解決されています。この手法を連続で使えば、コンピューティングリソースの許す限りの倍率でアップスケールが可能です。
Tiled Diffusion
画像をタイルに区切って、Diffusionモデルにかける手法はいくつか提案されており、2023年の春時点でSOTAだったのが、Multi DiffusionとMixture of Diffusers です。Tiled Diffusionは、Web UIおよびComfyUIに実装された拡張機能で、上記の二つのモデルが利用できます。
ここでは、このうちの Multi Diffusion について軽く解説します。
難しいことはやっておらず、Ultimate SD Upscalerのタイル分割を、より逆拡散過程に密に行う、みたいなイメージです。
高解像度化においては、MultiDiffusionへの入力はUltimate SD UpscaleのようにGANなどでアップスケール済みの画像です。
そのもとで、逆拡散過程の時刻 t において、画像 Jt を Jt-1 にデノイズするとします。この際に、ランダムにクロップ Fi(Jt,t) を選んでいくだけです。

補足:Tiled Diffusionのライセンスについて
Tiled Diffusionに関しては、CC BY-NC-SA ライセンスが付与されているので、これを利用したワークフローそのものは商用利用不可であることに注意してください。ただし、生成画像にはCC BY-NC-SAは継承されません。
ControlNet Tile
Ultimate SD UpscalerやTiled Diffusionなどのタイルベースの手法のよく知られた弱点として、プロンプトが制限されることが挙げられます。例えば、タイルベースの手法に「1 girl」のようなプロンプトを適用したとします。すると、各タイル一つ一つに「1 girl」が効いてしまい、女性の顔があちこちに描画されてしまいます。

これに対処するのが ControlNet Tileです。ControlNet Tileは「1 girl」が効くべきタイルにはプロンプトを反映し、そうでない部分(背景のみのタイルなど)にはプロンプトの効果を抑制するように訓練されています。
Iterative Upscaler
ComfyUI Managerの作者である、ltdrdata氏が精力的に開発を行っているアップスケーラーで、カスタムノード ComfyUI-Impact-Packで利用できます。
PixelKSampleUpscalerProvider ノードと、Iterative Upscale(image)ノードを連結することで使用可能になります。

やっていることは単純で、いきなり画像を所望の倍率にするのではなく、何stepかかけて、徐々にその倍率に近づけていきます。ここのスケジューリングは色々設計しがいがある部分だと思うのですが、ComfyUI-Impact-Packの実装では 以下のようなスケジューラーがデフォルトで実装されています。
upscale_factor_unit = max(0, (upscale_factor-1.0)/steps)
scale = 1
for i in range(steps-1):
scale += upscale_factor_unit4倍・2stepであれば、はじめに2.5倍にして、その後4倍まで拡大します。
PixelKSampleUpscalerProviderノードのPixelの意味は、Latentの状態で画像をアップスケールするのではなく、Pixelに戻してGANなどのAIアップスケーラーを用いて拡大しているということです。
Iterative Upscaleは、海外のredditやdiscordなどでたまに名前を見かけます。ただ、カクダイV1に取り入れてみて実験したところ品質が不安定だったので、不採用にしています。その代わり、後述する別の ComfyUI-Impact-Packのノードを利用しています。
打倒Magnific AIの歴史
この章では、打倒Magnific AIを掲げて登場した様々なオープンソースのアップスケーラーを紹介します。その中で出てきた取り組みのうち、カクダイV1で採用したものについて、特に詳しく解説します。
2023年11月に圧倒的なアップスケーラーMagnific AIが登場し、開発コミュニティはにわかにざわつきました。登場以降redditで様々なスレッドが立ち、その性能について議論されました。
こちらのスレッドでは、Magnific AIが驚きを持って迎えられ、どのような技術に基づいているか、議論が交わされています。前章で解説したような技術に加えて詳細化用のLoRAなどを適用するだけでは、到底追いつかないというのがコミュニティの見方です。ただし、生成画像の特徴から、タイルベースの手法を用いていることがほぼ確実視されています。このような分析を受けて、Magnific AIを超えんと様々な工夫を凝らした手法が登場しています。
例えば、Magnifakeと名付けられた手法においては、BLIPを用いて画像キャプショニングを行い、プロンプトを自動生成しています。
他には、Unsamplerを用いたノイズインジェクションを利用する取り組みも行われています。こちらは非常に有望な手法ですが、チューニングが必要以上に複雑になり、汎用的に使ってもらうには適さないと思い、カクダイV1では不採用になっています。解説などは別の機会に行いたいと考えています。
また、年明けに提案されたこちらの UltraUpscaler はSelf Attention Guidanceを適用したStable Diffusionを複数回重ねがけすることで、高品質なアップスケールを可能にしています。

Self Attention Guidance(SAG)の解説
Self Attention Guidance(SAG)自体は2023年2月に公開された手法ですが、高画質化の文脈で再注目されています。
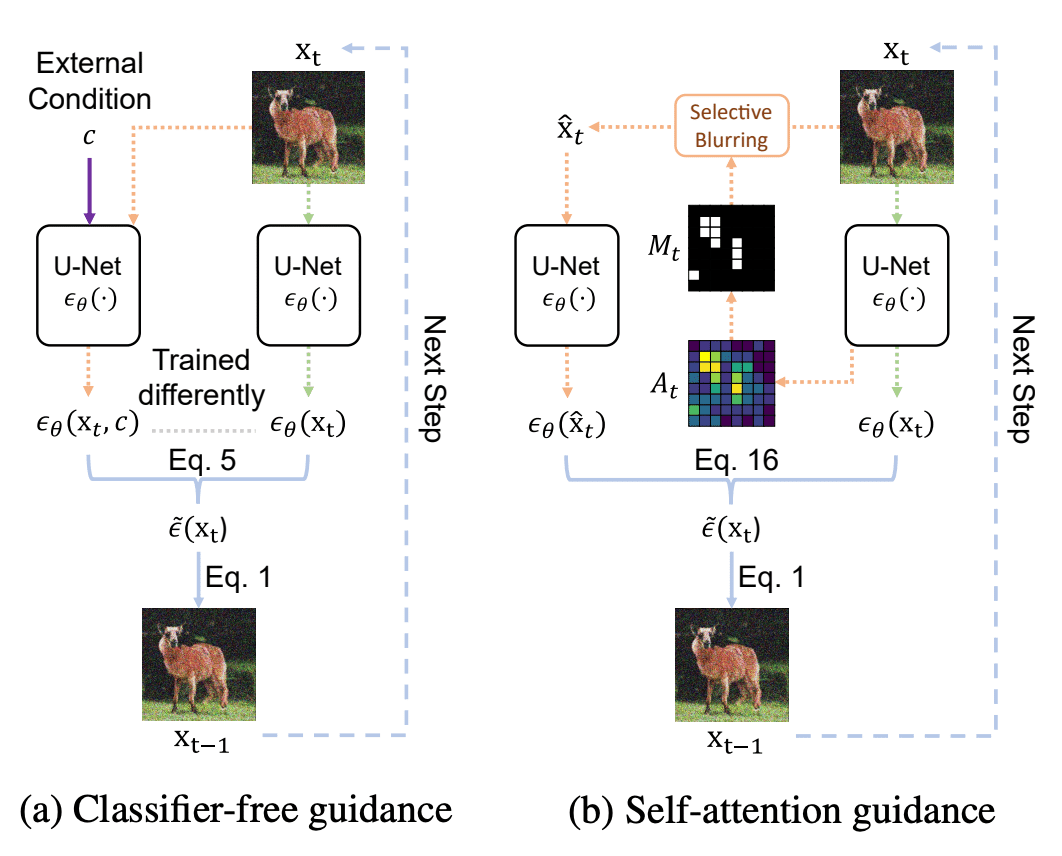
SAGはClassifier Free Guidance(CFG)に似た手法で、併用可能です。CFGでは、プロンプトによる条件付けありのUNetの出力と条件付けなしのUNet出力の差をとり、よりプロンプトが効く方向へ出力を誘導します。
SAGでは、推論時の画像のSelf-Attentionの値が高い部分ほど注意を払うべき重要な箇所であるということに着目します。まず、Self-Attentionの値が閾値以上の部分に対して、ガウシアンブラーでぼかしをかけます。これと、ぼかしなしのUNet出力の差をとり、よりぼかしが減る方向に出力を誘導します。これによって、画像の重要な部分がより鮮明になっていきます。
さらに、2023年12月にContent Consistent Super-Resolution(CCSR)という特別に訓練された、Stable Diffusionベースの超解像手法が公開されました。CCSRは既存のGANベースのアップスケーラーと比べて圧倒的な性能を誇り、これがすぐさまComfyUIのカスタムノードとして実装されました。
CCSRの解説
Content Consistent Super-Resolution とは、その名の通り一貫性をできるだけ保ちながらアップスケールする、Stable Diffusionベースの手法です。
Stable Diffusion 2.1 をベースに ControlNetとVAEデコーダーの重みのみを訓練しています。VAEデコーダーは拡大用に訓練されており、StableDiffusionによる画像超解像手法とGANを密に組み合わせたような構成と言えます。さらに、超解像のタスク用に特化したサンプリング戦略を用いることで一貫性を高めることに成功しています。非常に強力なこのモデルがApache-2.0で公開されたことは大変な吉報です。

カクダイV1について
長々と書きましたが、いよいよ本題のカクダイV1について説明します。
カクダイV1ワークフロー
使用したモデルは以下の通りです。
GPT4V
Stable Diffusion 1.5 checkpoint(cyber realistic)
LoRA(Detail Tweaker LoRA)
前章の部分までで要素技術の解説は終わっています。まず、言葉の定義を行います。
Model 1:Stable Diffusion 1.5 + LoRA + ControlNet Tile + FreeU
Model 2:Model 1 + Multi Diffusion + Self Attentnion Gudaince
ワークフローは以下のような構成になっています。

(備考)使用しているモデルの兼ね合いから、CC-BY-NC-SAライセンスでの公開となります。生成物に関しましては、その限りではありません。
1)Prompt Generator
GPT4Vを用いて、元画像のテーマ、元画像の詳細に言及するテキストプロンプトを生成
上記に対して、アップスケール用のプロンプト(very detailed, masterpiece, intricate details, UHD, 8K などの詳細化を指示するプロンプト)を連結して、Positive Promptとする
2)CCSR
CCSRを用いて元画像をアップスケールする(デフォルトでは4倍)
3)First SD Upscaler
CCSRで拡大した画像をMakeTileSEGSノードを使って、768x768pxでオーバーラップさせながらクロップすることで、複数のタイルに分割する
各タイルに対して、工程1で作成したプロンプトを Model 1 に入力し、img2imgを行い、詳細化を行う。ここではサンプリング処理にDetailerDebugノードを利用している。
4)Second SD Upscaler
工程3でアップスケールした画像をさらに Model 2 でアップスケールする(Multi Diffusion)
5)Color Matcher
Monge-Kantorovitch linear 法というカラーマッチの古典手法を用いて、CCSRでアップスケールした画像と工程4で仕上げた画像の色彩をマッチさせる
カクダイV1では、調整可能なパラメーターとして以下を設定しています。
Model 1 の denoise・Model 2 の denoise・ControlNet Tile の strength
カクダイV1の各工程の解説
Checkpoint Modelについて
本ワークフローでは、Stable Diffusion 1.5 のcheckpoint modelを利用しています。SDXLでも試しましたが、SD1.5の方が性能が結果が良かったので、カクダイV1ではSD1.5を採用しています。
LoRAについて
詳細化のためのLoRAはアップスケーラーの品質を高めるために強力に作用します。Magnific AIも高確率で強力な詳細化用のLoRAを備えていると考えられています。(Magnific AIはHDRというパラメータを指定できるのですが、これが LoRA Weightなのではないかという話もあったりします)。
カクダイV1では、有名な詳細化用のLoRAである Detail Tweaker LoRA を採用させてもらっています。
ただ、SDXLrender というLoRAを使った方が、より書き込みが増えます。こちらは civitai へのログインがダウンロードの条件となっており、採用を見送っていますが、civitaiにログイン済みの方はぜひ試してみてください。
Prompt Generatorについて
UltraUpscalerなどでは画像に対する具体的なプロンプトを与えずに、アップスケール用のプロンプトのみを与えています。しかしながら、カクダイV1では、GPT4Vを用いて画像をキャプショニングし、具体的なプロンプトを与える方策をとっています。
基本的に、既にある程度高画質の画像の高画質化については、アップスケール用のプロンプトで十分です。しかしながら、ぼやけた画像を高画質に変換するには、画像中のオブジェクトやドメインに関する具体的なプロンプトが必須と考えています。
ControlNet Tileについて
要素技術の解説で述べたとおり、タイルベースの手法に画像のオブジェクトに言及する具体的なプロンプトを入力する場合は、ControlNet Tileを用いて、タイルごとのプロンプトの効きを調整する必要があるため、導入しています。
ただし、ControlNet Tileには注意が必要です。というのも、ControlNet Tileの入力となる元画像が大きく崩れている場合は、そちらに引っ張られて、最終的な品質が劣化してしまいます。
カクダイV1では、最高品質の高画質化を行いたい場合には、ControlNet Tile Strengthを生成物を見ながら調整するように設計しています。この点は使用者の負担を強いてしまうので、今後修正していく予定です。
CCSRについて
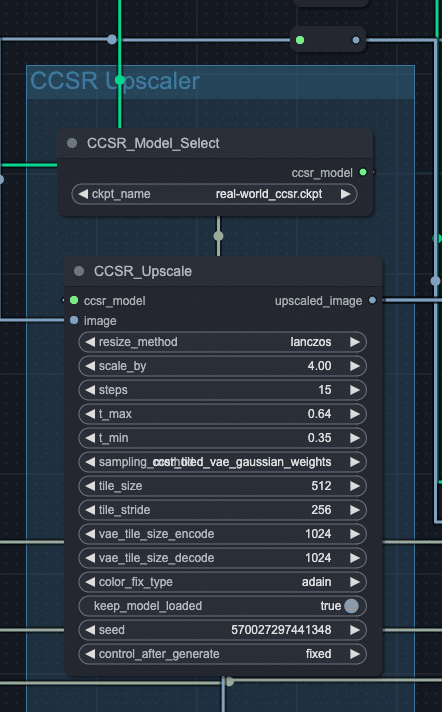
CCSRは非常に強力なアップスケーラーで、倍率も任意に拡大です。
カクダイ開発当初は、この部分にGANベースのアップスケーラーが用いられていましたが、CCSRに置換できてから、品質や安定性が一段と向上しました。
CCSRは4倍以上では、3 step でも 20 step でもぱっと見ほぼ変わらない出力を出すのですが、step数が小さいと微妙にタイル線が残ることがあり、後半のフローでこれが際立ってしまうので、論文にある通りの15 stepで設定しています。
First/Second SD アップスケーラーについて
CCSRの出力に対して、Stable Diffusionを重ねがけすることで品質がかなり向上します。また、denoiseパラメータを調節することで、高解像度化に止まらない画像美化が実現できます。
MakeTileSEGSとDetailerDebugノード
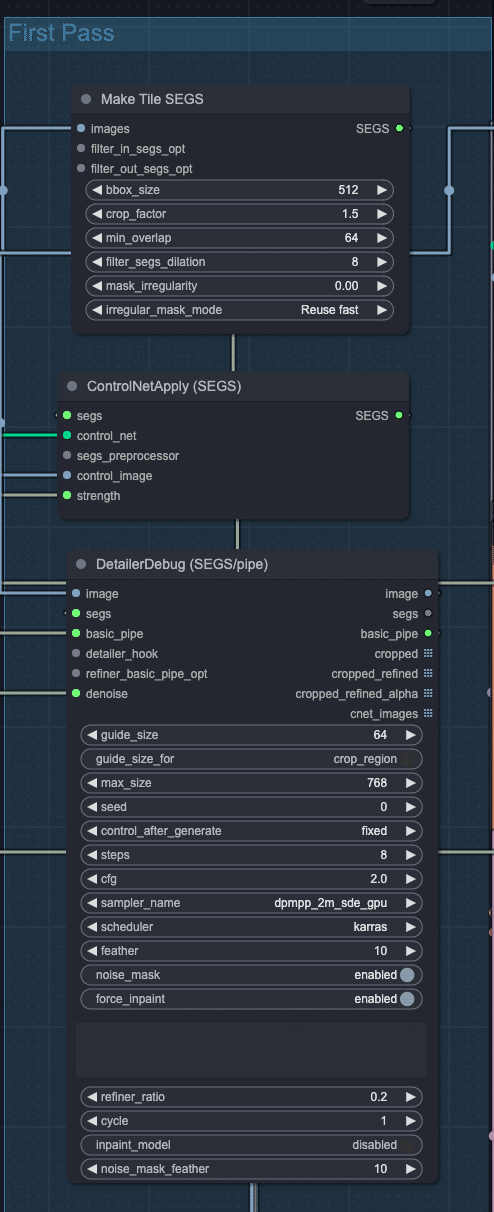
現状は単なるタイルベースのSDアップスケーラーとして利用しています。ただし、Comfy-Impact-PackのSEGSを利用して、背景と被写体を分離したアップスケールなどができるため、今後の応用を考えてこちらを利用しています。
Second SD アップスケーラー
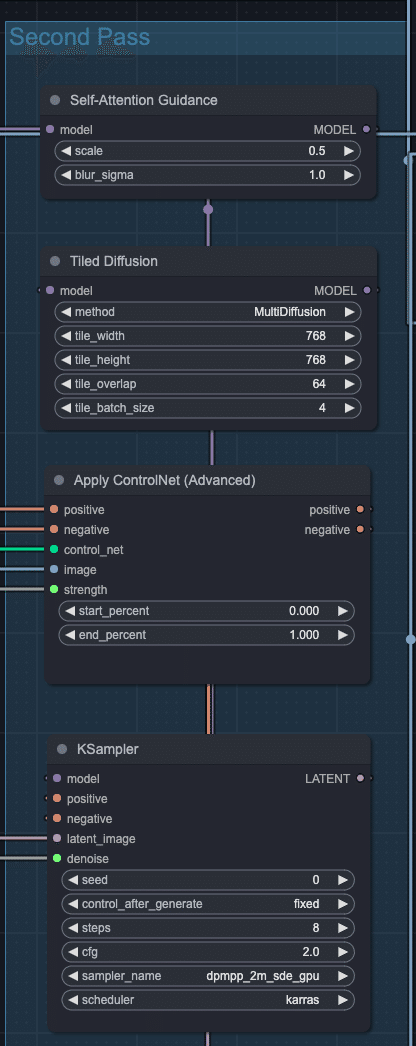
MultiDiffusionは各逆拡散過程でランダムにタイルを取るので、First SD アップスケーラーで生じる可能性のある規則正しいタイル線を打ち消す効果を期待しています。
また、Self Attention Guidanceは First SD アップスケーラーと Second SD アップスケーラーのどちらにも適用して良かったのですが、実験的に後者にのみ適用した方が高品質なケースが多かったため現在の構成になっています。
Color Matchについて
後半のパスで denoise を強くした場合には元画像と色味が変化してしまうケースが多いので、CCSRの出力と色味が一致するようにしています。
以上が カクダイV1 ワークフローの詳細な説明でした。本当にお疲れ様でした。
これから
長い記事にお付き合いいただきありがとうございました!
本記事が国内の生成AI開発の盛り上がりに何か寄与できたらとても嬉しいです。生成AIライブラリのdiffusersを用いた開発も楽しいですが、ComfyUIは感動的な体験だと思っているので、引き続き遊んでいきたいです。どうぞよろしくお願いします。
カクダイV1ワークフローですが、V1と銘打っている通り、まだまだやりたいことががたくさんあります。例えば、
画像キャプショニングモデルを使って、タイルごとにプロンプトを動的に生成して生成する(やや不安定になりそうですが、ControlNet Tileも使わなくて済みますし、品質向上が期待できそう?)
今回はcheckpointやLoRAを固定していますが、これを画像やプロンプトに合わせて動的に決定するノードを作成する
また、SAM(Segment Anything Model)を利用した特化型のフローなども組む
あたりです。これらの開発過程やアップデート情報などは無料ニュースレターで配信していく予定ですので、ぜひ登録よろしくお願いします。
また、こちらの我々が運営するAIメディア sayhi2.ai の無料登録時に同時にニュースレターに登録することが可能です!ぜひ登録よろしくお願い致します。