Python初心者がcookpadのレシピデータで、料理カテゴリの分類モデルを作成してみた

はじめに
初めましてsatoと申します。私は製造業の会社で働く会社員で、材料の開発を担当しています。薬品の扱いには慣れていますが、Pythonやその他プログラミングには全く触れてきませんでした。
業務を行う中では、色々な実験データを扱う機会が多くあります。そのため、統計的な処理やデータ整理の効率化のためのプログラミングのスキルを身に着けたいと思い、Aidemyの「データ分析講座」を受講することにしました。
本記事の概要
本記事では、「データ分析講座」のカリキュラムを終え、最後の成果物として取り組んだ内容についてまとめます。
今回は料理レシピサイトcookpadのデータをもとに、使用されている材料から「和食」、「中華」、「洋食」の分類モデルをPythonで作成することにチャレンジしました。
開発の仕事では様々な材料を組み合わせて新規の材料を作ります。作業としては料理のイメージに近いと考え、このようなテーマを設定しました。
こちらの記事では、自然言語処理のデータの前処理(単語分割)や単語のベクトル化、分類モデルの学習をトピックとして扱っています。
同じような初心者の方にも参考になればうれしいです。
作成したプログラム
モデル作成の流れ
モデル作成の流れは下記の通りです。
①データのスクレイピング
②データの前処理
③ベクトル化
④分類モデルの作成
⑤学習していないデータの分類予測
実行環境
実行環境は以下です。Google Colabolatoryでコードを記述しました。
OS:windows OS
環境:Google Colabolatory
Python ver : 3.7.13
①データのスクレイピング
まずは必要なデータのを集めるためにスクレイピングを行います。スクレイピングには無料でも利用できるScrapeStormを用いました。
普段通り、レシピを調べる要領でcookPadのページで「和食」と検索します。

このページのURLを取得し、ScrapeStormでスクレイピングを実行します。するとこのようにデータが抽出されます。「和食」での検索結果を100件取得することができました。

同じように、「中華」と「洋食」も100件ずつデータをスクレイピングで取得して、合計300件のデータとします。
このデータをそれぞれcsvとしてエクスポートし、google colabolatoryにアップロードします。
②データの前処理
アップロードしたcsvデータを読み込むために、下記コードでマウントを実行します。また、単語分割で使用するjanomeをインストールしておきます。
文書を形態素解析(意味を持つ最小の言語単位に分割し、品詞などの情報を)するライブラリにはjanomeとMeCabがあり、MeCabの方が精度や実行速度で優位とされています。一方で、janomeは!pipコマンドで簡単に利用できるという利点があり、今回はjanomeを利用しました。
#アップロードしたデータのマウント
from google.colab import drive
drive.mount('/content/drive')
#janomeのインストール
!pip install janome次に、DataFrameを作成して読み込みます。欠損値を削除し、和食、中華、洋食のデータを結合します。
import pandas as pd
import csv
#DataFrameの作成
all_df = pd.DataFrame()
#len関数で要素を確認するためのリスト
len_data = []
#file_pathsとして和食、中華、洋食のfile pathを指定
file_paths = ['/content/drive/MyDrive/recipe/japanese.csv', '/content/drive/MyDrive/recipe/chinese.csv', '/content/drive/MyDrive/recipe/western.csv']
#recipe_dfとしてデータを読み込み、欠損値を削除、all_dfとして結合
for file_path in file_paths:
recipe_df = pd.read_csv(file_path, encoding='utf-8')
recipe_df = recipe_df.dropna()
len_data.append(len(recipe_df))
all_df = pd.concat([all_df, recipe_df])
単語分割に必要なTokenizerメソッドをインストールし、単語の出現回数を記録するためにdefaultdictにより辞書を作成します。引数にintを指定すると初期値は0となります。
from janome.tokenizer import Tokenizer
from collections import defaultdict
#Tokenizerのインスタンスを作成
t=Tokenizer()
#辞書vocab_dictにリストの各要素の出現回数を記録
vocab_dict = defaultdict(int)次に「和食」「中華」「洋食」にそれぞれ列番号に対応する「0」「1」「2」をラベルとします。
import numpy as np
y = np.array([0]*len_data[0] + [1]*len_data[1] + [2]*len_data[2])
y分類モデルに学習させるため、訓練データとテストデータに分割します。引数にtrain_size=0.7と指定し、7割を訓練データ、残り3割をテストデータに分けます。
import random
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(all_df['ingredients'],y, random_state=0,train_size=0.7)訓練データの数を確認してみるとdropna関数で欠損値を除去した後のデータの数は267で、7割は186.9なので、分割できていることがわかりました。
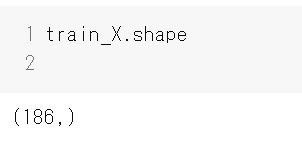
ここで元の抽出したデータを見てみると、材料データの文字列には、( )や句読点、記号などが含まれています。

これらはベクトル化するときに不必要なデータなので、単語分割するとともに、1文字である( )や句読点や記号を拾わないよう、2文字以上となる条件を加えます。
def tokenize1(text):
tokens = t.tokenize(text)
noun = []
for token in tokens:
if token.part_of_speech.split(",")[0]=="名詞" and len(token.surface)>1:
noun.append(token.surface)
return noun 分割したデータを表示してみます。
for vocab_dict in vocab_dict.keys():
print(vocab_dict)
まだ意味のある単語以外の文字列が少し残っていますが、概ね名詞のみに分けられています。
③tf-idfによるベクトル化
単語分割ができたので、これをtf-idfによりベクトル化を行います。
ベクトル化とは、 文書中に単語がどのように分布しているかをベクトルとして表現することです。日本語をそのまま学習に用いるのではなく、コンピューターが得意な数値に置き換えることで処理を行うことができます。
tf-idfは単語の出現頻度である tf (Term frequency) と、その単語がどれだけ珍しいか(希少性)をしめす逆文書頻度 idf(Inverse Document Frequency) の 積で 表される統計量です。
今回の目的は、和食、中華、洋食で使用される材料の単語頻度から、それぞれの傾向を読み取ることです。そのため今回のような場合は頻度のみを考慮したBag of words(BOW)でもよいかもしれません。
ただ、先述のようにまだ少し不要な文字列があるため、ここではTf-idfを用いてベクトル化を行ってみます。
# tf-idfを用いてベクトル化
vectorizer = TfidfVectorizer(tokenizer=tokenize1)
train_matrix = vectorizer.fit_transform(train_X)ベクトル化したデータを表示してみる数値に変換できていることがわかります。

④分類モデルの作成
ここまでで、cookpadのレシピデータから材料の単語を抽出し、ベクトル化により数値化することができました。
最後に分類を行います。分類器にはナイーブベイズとランダムフォレストを用いました。
ナイーブベイズはいくつかの推定が考えられるとき、どれが最もらしいかを推定するベイズの定理に基づいた手法です。
ランダムフォレストは決定木(樹形図)の分類モデルを複数作り、ランダムに変数に決められた変数を用いてデータの分類を行います。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier
from janome.tokenizer import Tokenizer
# ナイーブベイズを用いて分類
clf = MultinomialNB()
clf.fit(train_matrix, train_y)
# ランダムフォレストを用いて分類
clf2 = RandomForestClassifier(n_estimators=100, random_state=0)
clf2.fit(train_matrix, train_y)
# テストデータを変換
test_matrix = vectorizer.transform(test_X)結果を表示してみます。ランダムフォレストに比べ、ナイーブベイズの方が高い正解率で分類できていることがわかりました。
# 分類結果を表示
print("ナイーブベイズ")
print("訓練データの正解率:", clf.score(train_matrix, train_y))
print("テストデータの正解率:", clf.score(test_matrix, test_y))
print()
print("ランダムフォレスト")
print("訓練データの正解率:", clf2.score(train_matrix, train_y))
print("テストデータの正解率", clf2.score(test_matrix, test_y))
⑤学習していないデータの分類予測
次に、作成した分類モデルに対して、学習していないレシピデータを渡して、分類をしてみます。今回は料理のカテゴリ分類がわかりにくいであろう「創作料理」のデータを抽出して予測させます。
cookpadで「創作」と検索し、創作料理のレシピデータを10件、同様の手順スクレイピングしてcsvを取得しました。
データの前処理も同様の手順で行いました。
#DataFrameの作成
sosaku_df = pd.DataFrame()
#len関数で要素を確認するためのリスト
len_data = []
#file_pathsとしてsosakuのfile pathを指定
file_paths = ['/content/drive/MyDrive/recipe/sosaku.csv']
#recipe_dfとしてデータを読み込み、欠損値を削除、all_dfとして結合
for file_path in file_paths:
sosaku_df = pd.read_csv(file_path, encoding='utf-8')
sosaku_df = sosaku_df.dropna()
len_data.append(len(sosaku_df))sosaku = sosaku_df['ingredients']
#Tokenizerのインスタンスを作成
t=Tokenizer()
def tokenize1(text):
tokens = t.tokenize(text)
noun = []
for token in tokens:
if token.part_of_speech.split(",")[0]=="名詞" and len(token.surface)>1:
noun.append(token.surface)
return noun dropna関数で欠損値のあるデータを削除しているので、削除後のデータ数はこちらの7件となりました。
sosaku_title = sosaku_df['タイトル']
print(sosaku_title)
データを変換して、ナイーブベイズとランダムフォレストの分類器にデータを渡し、predict関数で分類予測結果を表示します。
# ナイーブベイズを用いて分類
clf = MultinomialNB()
clf.fit(train_matrix, train_y)
# ランダムフォレストを用いて分類
clf2 = RandomForestClassifier(n_estimators=100, random_state=0)
clf2.fit(train_matrix, train_y)
# データを変換
sosaku_matrix = vectorizer.transform(sosaku)
# 分類予測結果を表示
print("ナイーブベイズ")
print("創作の分類:", clf.predict(sosaku_matrix))
print()
print("ランダムフォレスト")
print("創作の分類", clf2.predict(sosaku_matrix))
分類予測結果が出ましたが、これだけだと数字なので少しわかりにくいかと思います。
最初にラベル付けした時、0を「和食」、1を「中華」、2を「洋食」と置き換えているので、その数値を置き換えて表示してみます。
import pandas as pd
from IPython.display import display
#創作料理タイトルと分類予測結果を変数に代入
sosaku_title = sosaku_df['タイトル']
array_NB = clf.predict(sosaku_matrix)
array_RF = clf2.predict(sosaku_matrix)
#分類予測結果を(7,2)の配列に結合
array_stack = np.stack([array_NB, array_RF], axis=1)
#カラム名のリスト
column_names = ["NaiveBayes", "RandomForest"]
#DataFrameの形にまとめる
class_df = pd.DataFrame(array_stack, index=sosaku_title, columns=column_names)
#o,1,2を料理カテゴリーに置き換えdisplay関数で表示
display(class_df.replace([0,1,2],["和 食", "中 華", "洋 食"]))
学習していない「創作料理」のレシピデータを用いて、料理カテゴリの分類をすることができました。結果を見るとナイーブベイズとランダムフォレストで予測結果が異なることがわかります。
明らかに洋食だと思われる「Caesar salad」が共に「和食」に分類されていたり、「和風パスタ」は「和食」と「洋食」で意見が分かれました。
実際に材料のデータを見てみると、今回抽出したデータには「醤油」など特徴的な材料があまり使われていないものが多いようでした。また「卵」はどの料理でも使用される食材なので、分類結果が分かれたのではないかと思います。
今回記述したプログラムでも、比較的高い正解率のモデルが作成できましたが、より不要な文字列を除去したり、表記を統一(”たまご”と”卵”など)することで、精度を上げられるのではないかと思っています。
今後の活用
このモデルでは、扱ったのがレシピデータという日本語の文字列だったので、自然言語処理でプログラムを作成しました。
分類モデル自体は文字列だけでなく、いろいろデータで活用できるので、実際に仕事で扱っている分析データなどにも応用してみたいです。
正直なところ、思った以上に仕事に圧迫されてしまったり、思うようにカリキュラム進められなかった面もありました。
特に、今回のモデル作成に取り組む際は、分からないことを調べるとさらに分からないことが芋ずる式に出てきて、独りでは解決できないことばかりでした。技術カウンセリングを通じて、講師の方にいろいろと助けていただきました。
この受講期間で学んだことを、より使いこなせるようにするために、引き続き勉強を続けていきたいと思います。
最後までお読みいただきありがとうございました。