tweetを感情分析して株価予測してみる

プログラム関係超素人な私が
Pythonを勉強してみて
最初は全く意味が解らず???で。
異次元言葉を学んでいる感覚で
とりあえずやっつけ仕事する感じ‥
かなり苦労していました。
終盤で表記課題に取り組んだ時、
初めて「非常に面白い!奥深い!」と感心しました。
Aidemyで学習した内容の振り返りとして、
感情分析を利用した株価予測(上下変動)
をしてみたいと思います。
※ 実行環境
windows 10
Google Colaboratory
Python 3.7.12
手順概要
1.TwitterAPIで ツイートのデータを取得する
2. 極性辞書を用いて
日毎のツイートの感情分析を行う
(PN値が適切でなければ標準化で整える)
3. 日経平均株価の時系列データを取得する
4. 各々のデータを合体する
5. 訓練データと検証データに分割
6. 特徴量の作成を行う
7. 予測モデルを構築し、予測精度を計測する
使用するライブラリ
(下記内容:この先説明のあるものは省略)
import tweepy
import csv
import pytz
import pandas as pd
import MeCab
import re
import numpy as np
import urllib
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC1. ツイートのデータを取得する
株価は情報によって左右されます。
その意図(いわゆる情報源)と関係性がある
Twitterのデータを使ってCSVに落とし込みます。
今回は日経電子版 マーケット(@nikkei_market)さん
ツイート内容をデータとして取得していきます。
※ ツイートを取得するためには
事前にTwitter APIの申請を行います。
(アクセストークンが必要となります。)
#twitterからのツイートを取得する際に必要なアクセストークン
# Twitterの認証
# 取得したキーを格納
API_KEY = "" # API KEYをご記載ください
API_SECRET = "" # API SECRETをご記載ください
ACCESS_TOKEN = "" # ACCESS TOKENをご記載ください
ACCESS_TOKEN_SECRET = "" # ACCESS TOKEN SECLETをご記載ください
# Tweepy設定
auth = tweepy.OAuthHandler(API_KEY, API_SECRET) # Twitter API認証
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) # アクセストークン設定
api = tweepy.API(auth) # APIのインスタンス生成
#ツイート取得
tweet_data = []
#Cursorを使用し、大量のツイートを取得する
tweets = tweepy.Cursor(api.user_timeline,screen_name = "@nikkei_market",exclude_replies = True)
#Twitterのid、ツイート日時、ツイート本文、いいね数、リツイート数の情報を格納
for tweet in tweets.items():
tweet_data.append([tweet.id,tweet.created_at,tweet.text.replace('\n',''),tweet.favorite_count,tweet.retweet_count])
# tweets.csvの名前で保存
with open('./tweets.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(["id", "created_at", "text", "fav", "RT"])
writer.writerows(tweet_data)TwitterAPI申請方法については
私は下記サイトを参考にしております。
https://toxublog.com/blog/twitter_api_apply/
2. 極性辞書を用いて日毎のツイートの感情分析を行う
単語感情極性対応表(岩波国語辞書:岩波書店)
を使って、ツイート内容がポジティブ、
もしくはネガティブかを
単語ごとに判断して分析を行います。
(PN 値として数値化=極性辞書といいます)
※Google Colaboratory では、
感情分析ツール mecabは初期搭載しておりません。
下記のインストールが必要です。
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7上記のインストールの上、極性辞書を取り込みます。
#表の出力の準備
%matplotlib inline
# 岩波国語辞書のダウンロード
import urllib.request
import zipfile
# URLを指定
url = "https://storage.googleapis.com/tutor-contents-dataset/6050_stock_price_prediction_data.zip"
save_name = url.split('/')[-1]
# ダウンロード
mem = urllib.request.urlopen(url).read()
# ファイル保存
with open(save_name, mode='wb') as f:
f.write(mem)
# zipファイルをカレントディレクトリへ展開
zfile = zipfile.ZipFile(save_name)
zfile.extractall('.')単語感情極性値対応表については
こちらのサイトを参照しました。
日本語文の感情値分析[単語感情極性値対応表]
https://qiita.com/y_itoh/items/8e63334058659fe2b4d3
ツイート内容を形態素解析し、実装します。
# MeCabインスタンスの作成(IPA辞書)
m = MeCab.Tagger('')
# ツイート内容を形態素解析し辞書のリストを返す
def get_diclist(text):
parsed = m.parse(text) # 形態素解析を実施
lines = parsed.split('\n') # 解析結果を全て分けてリスト化
lines = lines[0:-2] # 後ろの2行不要→削除
diclist = []
for word in lines:
l = re.split('\t|,',word) #タブとカンマを分ける
d = {'Surface':l[0], 'POS1':l[1], 'POS2':l[2], 'BaseForm':l[7]}
diclist.append(d)
return(diclist)
#形態素解析結果の各単語dictデータにPN値を追加
def add_pnvalue(diclist_old, pn_dict):
diclist_new = []
for word in diclist_old:
base = word['BaseForm']
if base in pn_dict:
pn = float(pn_dict[base])
else:
pn = 'notfound' # PN Tableに無い場合
word['PN'] = pn
diclist_new.append(word)
return(diclist_new)
#各ツイートのPN平均値を求める
def get_mean(dictlist):
pn_list = []
for word in dictlist:
pn = word['PN']
if pn!='notfound':
pn_list.append(pn)
if len(pn_list)>0:
pnmean = np.mean(pn_list)
else:
pnmean=0
return pnmean
#取得したツイートの読込み
df_tweets = pd.read_csv('tweets.csv', names=['id', 'date', 'text','fav', 'RT'], index_col='date', header=1)
df_tweets.index = pd.to_datetime(df_tweets.index)
df_tweets = df_tweets[['text']].sort_index(ascending=True)
#岩波国語辞書の読込み
pn_df = pd.read_csv('./6050_stock_price_prediction_data/pn_ja.csv', encoding='utf-8', names=('Word','Reading','POS', 'PN'))
word_list = list(pn_df['Word']) #word_listにリスト型でWordを格納
pn_list = list(pn_df['PN']) #pn_listにリスト型でPNを格納
pn_dict = dict(zip(word_list, pn_list)) #pn_dictとしてword_list, pn_listを格納した辞書を作成
#means_list(=空リスト)を作成し、解析したツイートごとの平均値を求める
means_list = []
for tweet in df_tweets['text']:
dl_old = get_diclist(tweet)
dl_new = add_pnvalue(dl_old, pn_dict)
pnmean = get_mean(dl_new)
means_list.append(pnmean)
df_tweets['pn'] = means_list形態素解析については
下記サイトでも再度確認をしてます。
形態素解析に代表される自然言語処理の仕組みやツールまとめ
https://www.cogent.co.jp/blog/morphological-analysis-natural-language-processing/
ここで、PN値がどのようになっているのか一度確認してみます。
#PN値 確認用出力
print(df_tweets['pn'])
x = df_tweets.index
y = df_tweets.pn
plt.plot(x,y)
plt.grid(True)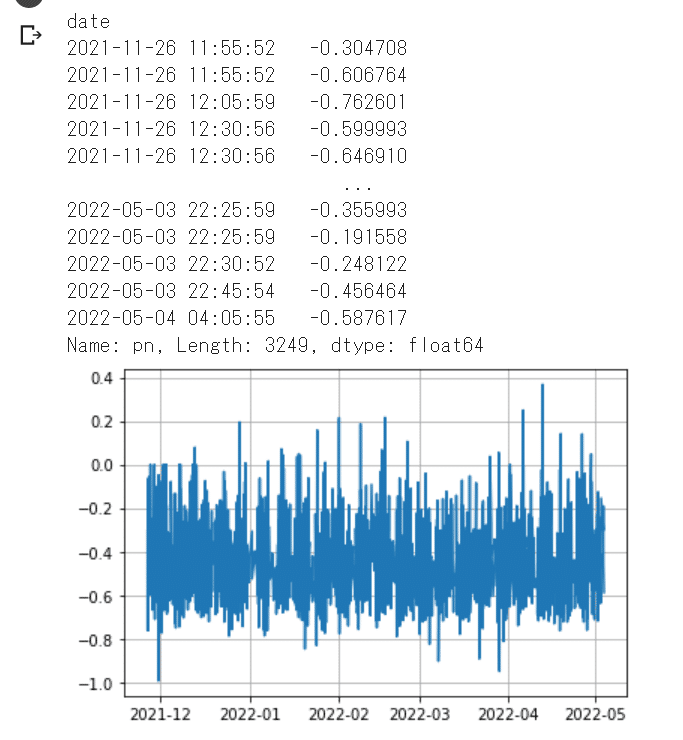
グラフを見ると
全体的にマイナス値が多いことに気がつきます。
数値に偏りがあるということ自体を
調整するために「標準化」を行っていきます。
(統計学内容なので…混乱するのですが)
簡単に説明すると‥
各値が平均からどのくらい離れているか‥
平均値をゼロに置き換えて表現しなおす、
ということです。
# means_listをnumpy配列に変換
means_list = np.copy(means_list)
# means_listを用いて標準化を行う
x_std = (means_list - means_list.mean()) / means_list.std()
df_tweets['pn'] = x_std
# またPNを日付ごとの平均に変え、プロット
df_tweets = df_tweets.resample('D').mean()
x = df_tweets.index
y = df_tweets.pn
plt.plot(x,y)
plt.grid(True)
# df_tweets.csvという名前でdf_tweetsを再び出力。
df_tweets.to_csv('./df_tweets.csv')グラフは下記の通りになりました。
だいぶゼロ中心になりました。
先ほどのグラフ形状とは少し
異なりますがこの数値を代用活用します。

「標準化」については
非常にわかりやすい内容が記載されていました。
下記サイトが参考になるかと思います。
3.日経平均株価の時系列データを取得する
pandas dateraderを使用して
データを取り込みます。
Twitter APIで取り込めたのが
2021/11/26~だったので
日付をなるべく合わせてみました。
#ライブラリのインポート
from pandas_datareader.stooq import StooqDailyReader
from datetime import datetime
import matplotlib.pyplot as plt
#株価取得範囲を設定
start = datetime(2021, 11, 26)
end = datetime(2022, 5, 3)
#銘柄コードを入力(日経平均株価)
stock = '^NKX'
#株価取得
df = StooqDailyReader(stock, start=start, end=end)
#終値の身をクローズアップ
df_stock = df.read()['Close'].sort_index() #降順→昇順へ
#確認用出力
print(df_stock)
#CSVとして保存
df_stock.to_csv("Nikkei_Heikin.csv", encoding="UTF-8", index=True)
日本では只今大型連休。
今は株価レートもお休みですね。
上記をグラフ化
‥余談 個人的感想‥
グラフが大きく変動してますね。
#matplotlibで株価をグラフ化
df_stock.plot(figsize=(16,8),fontsize=18)
plt.legend(bbox_to_anchor=(0, 1), loc='upper left', borderaxespad=1, fontsize=10)
plt.grid(True)
plt.title('N225 graph',fontsize=10)
#plt.ylim(0, 30000)
plt.savefig("N225 graph.png")
plt.show()
df_stock.to_csv("N225.csv", encoding="UTF-8", index=True)
pandas dataraderに関しては
下記のサイトを参考にさせて頂きました。
「Python」と「Google Colaboratory」で株価データ分析に挑戦
※ 会員登録(無料)で全てが閲覧可となります。
https://atmarkit.itmedia.co.jp/ait/articles/2107/27/news006.html
4. 各々のデータを合体する
感情分析結果のデータと株価のデータを合わせます。
# 株価データ解析前のテストデータ準備
# データの読み込み
df = pd.read_csv('Nikkei_Heikin.csv',index_col=0, parse_dates=True)
df.index.name="date"
df.to_csv("./eur_time.csv")
df = pd.read_csv("./eur_time.csv" , index_col="date")
# dfとdf_tweetsの二つのテーブルを結合し、NaNを消去。
df_tweets = pd.read_csv('./df_tweets.csv', index_col='date')
table = df_tweets.join(df, how='right').dropna()
# table.csvとして出力
table.to_csv("./table.csv")
#下の表を表示
print(table)
5. 訓練データと検証データに分割
上記で合わせたデータ (table.csv) から、
訓練データと検証データに分割していきます。
※ 訓練(train)データ:8割
検証(test)データ:2割にしました。
CSV出力(保存)までのコードです。
#訓練データと検証データに仕分け
table = pd.read_csv("./table.csv",index_col='date')
X = table.values[:, 0]
y = table.values[:, 1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, shuffle=False)
X_train_std = (X_train - X_train.mean()) / X_train.std()
X_test_std = (X_test - X_train.mean()) / X_train.std()
# 訓練データをdf_trainというテーブルを作成、indexを日付、カラム名をpn値、Close(終値)にしてdf_train.csvという名前で保存
df_train = pd.DataFrame(
{'pn': X_train_std,
'Close': y_train},
columns=['pn', 'Close'],
index=table.index[:len(X_train_std)])
df_train.to_csv('./df_train.csv')
# 検証データも訓練データと同様に df_testというテーブルを作成、df_test.csvという名前で保存
df_test = pd.DataFrame(
{'pn': X_test_std,
'Close': y_test},
columns=['pn', 'Close'],
index=table.index[len(X_train_std):])
df_test.to_csv('./df_test.csv')6. 特徴量の作成を行う
訓練データより 前日からの変動と、
特徴量として、直近3日間ごとの
PN値と株価の変化を算出します。
まずは、1日ごとのPN値と
株価の差分値を取得します。
# 訓練データのPN値と株価の変化の表示
rates_fd = open('./df_train.csv', 'r')
rates_fd.readline() #1行ごとにファイル終端まで全て読み込む
next(rates_fd) # 先頭の行を飛ばす
# 日付を格納
exchange_dates = []
# 1日ごとのpn値の差分を格納する準備
pn_rates = []
pn_rates_diff = []
# 1日ごとの株価の差分を格納する準備
exchange_rates = []
exchange_rates_diff = []
prev_pn = df_train['pn'][0]
prev_exch = df_train['Close'][0]
# 訓練データの数だけPN値・株価の変化を算出
for line in rates_fd:
splited = line.split(",")
time = splited[0] # table.csv 1列目 日付
pn_val = float(splited[1]) # table.csv 2列目 PN値
exch_val = float(splited[2]) # table.csv 3列目 Close(終値)
exchange_dates.append(time) # 日付
pn_rates.append(pn_val) # PN値
pn_rates_diff.append(pn_val - prev_pn) # PN値の変化
exchange_rates.append(exch_val) # 株価
exchange_rates_diff.append(exch_val - prev_exch) # 株価の変化
prev_pn = pn_val #次の差分を算出するため、古いPN値を更新
prev_exch = exch_val #次の差分を算出するため、古い株価を更新
rates_fd.close()
次に、3日間ごとのPN値と
株価の変化データの取得し、
株価の上下ラベルの作成をします。
#3日間ごとのPN値と株価の変化データを取得
INPUT_LEN = 3
data_len = len(pn_rates_diff)
# 説明変数を格納する準備
tr_input_mat = []
# 目的変数を格納する準備
tr_angle_mat = []
# 直近3日間なので、INPUT_LENから開始
for i in range(INPUT_LEN, data_len):
tmp_arr = []
# i日目の直近3日間の株価とネガポジの変化を格納
for j in range(INPUT_LEN):
tmp_arr.append(exchange_rates_diff[i-INPUT_LEN+j])
tmp_arr.append(pn_rates_diff[i-INPUT_LEN+j])
tr_input_mat.append(tmp_arr)
# i日目の株価の上下(プラスなら1、マイナスなら0)を格納
if exchange_rates_diff[i] >= 0:
tr_angle_mat.append(1)
else:
tr_angle_mat.append(0)
# numpy配列に変換して結果を代入
train_feature_arr = np.array(tr_input_mat)
train_label_arr = np.array(tr_angle_mat)_angle_mat)これを検証(test)データにも行っていきます。
(訓練データと同様なのでコード表記のみ)
# 検証データのPN値と株価の変化の表示
rates_fd = open('./df_test.csv', 'r')
rates_fd.readline()
next(rates_fd)
# 日付を格納
exchange_dates = []
# 1日ごとのpn値の差分を格納する準備
pn_rates = []
pn_rates_diff = []
# 1日ごとの株価の差分を格納する準備
exchange_rates = []
exchange_rates_diff = []
prev_pn = df_test['pn'][0]
prev_exch = df_test['Close'][0]
# 訓練データの数だけPN値・株価の変化を算出
for line in rates_fd:
splited = line.split(",")
time = splited[0] # table.csvの1列目日付
pn_val = float(splited[1]) # table.csvの2列目PN値
exch_val = float(splited[2]) # table.csvの3列目Close(終値)
exchange_dates.append(time) # 日付
pn_rates.append(pn_val)
pn_rates_diff.append(pn_val - prev_pn) # PN値の変化
exchange_rates.append(exch_val)
exchange_rates_diff.append(exch_val - prev_exch) # 株価の変化
prev_pn = pn_val
prev_exch = exch_val
rates_fd.close()
INPUT_LEN = 3
data_len = len(pn_rates_diff)
test_input_mat = []
test_angle_mat = []
for i in range(INPUT_LEN, data_len):
test_arr = []
for j in range(INPUT_LEN):
test_arr.append(exchange_rates_diff[i - INPUT_LEN + j])
test_arr.append(pn_rates_diff[i - INPUT_LEN + j])
test_input_mat.append(test_arr) # i日目の直近3日間の株価とネガポジの変化
if exchange_rates_diff[i] >= 0: # i日目の為替の上下、プラスなら1、マイナスなら0
test_angle_mat.append(1)
else:
test_angle_mat.append(0)
test_feature_arr = np.array(test_input_mat)
test_label_arr = np.array(test_angle_mat)7. 予測モデルを構築し、予測精度を計測する
やっと、これで機械学習できる準備が全部整いました。
(機械学習させるまで準備がたくさん必要)
訓練データで学習を行い、検証データでモデルの予想精度を確認します。
予想精度を確認するモデルは下記のとおりです。
・ロジスティック回帰
・ランダムフォレスト
・SVM
#機械学習と予測結果の表示
# train_feature_arr, train_label_arr,test_feature_arr, test_label_arrを特徴量にして、予測モデル(ロジスティック回帰、SVM、ランダムフォレスト)を構築し予測精度を計測してください。
mod1 = LogisticRegression()
mod2 = RandomForestClassifier(n_estimators=200, max_depth=8, random_state=0)
mod3 = SVC()
mod1.fit(train_feature_arr, train_label_arr)
print("--Method:", mod1.__class__.__name__, "--")
print("Cross validatin scores:{}".format(mod1.score(test_feature_arr, test_label_arr)))
mod2.fit(train_feature_arr, train_label_arr)
print("--Method:", mod2.__class__.__name__, "--")
print("Cross validatin scores:{}".format(mod2.score(test_feature_arr, test_label_arr)))
mod3.fit(train_feature_arr, train_label_arr)
print("--Method:", mod3.__class__.__name__, "--")
print("Cross validatin scores:{}".format(mod3.score(test_feature_arr, test_label_arr)))
# 予測
# predに検証データでの予測値を代入。
pred_1 =mod1.predict(test_feature_arr)
pred_2 =mod2.predict(test_feature_arr)
pred_3 =mod3.predict(test_feature_arr)結果、下記の通りとなりました。

SVMの結果は数値的に比較的(と言ってもかろうじて0.7)高めでした。
グラフで表記
# グラフを可視化。予測値は赤色でプロット。
fig, (axL, axC, axR) = plt.subplots(ncols=3, figsize=(24, 4))
axL.plot(test_label_arr)
axL.plot(pred_1,color="r")
axC.plot(test_label_arr)
axC.plot(pred_2,color="r")
axR.plot(test_label_arr)
axR.plot(pred_3,color="r")
plt.show()
左から ロジスティック回帰、ランダムフォレスト、SVMの順です。
グラフの見方は
前日からマイナスなら0、プラスなら1を示します。
ライン:赤は予測結果、青は実際の上下を示します。
確かにグラフを見てみると
一番右、SVMグラフは重なり部分が多いですね。
特に後半はほぼ一緒です。
他の2つのグラフは
青と赤のラインの統一性はなく、
一番右(ロジスティック回帰)は
青と赤のラインが重なりがかなり少ないです。
今回の予測ではどうやら
SVMの予測値が適正かと判断します。
ただし、このままでの結果を
そのまま使うというのは危険です。
(0.7という数値からも判断できます)
「更に機械学習させて
予測精度を上げる必要がある」
という結果になりました。
振り返り
初心者ながらも
こんな形で予測ができたことは驚きました。
(結果はもっと低い値かと思っていました)
更に精度が上がる内容(どのくらい上がるのか)
プログラミングできるようになるために
更に私自身、プログラミング学習が必要と感じました。