
コイカツで作ったキャラをLoRAにするぞ

楽をするためなら何でもする!
こんにちわ、のうめんです。
弊アカウントの看板娘「野梅」は、初出はかつてVtuber用に開発された「Vカツ」で作られ、今ではVカツのカスタム前のコイカツに先祖返りしたものになっている。そしてそのコイカツの開発元であるイリュージョンも2023年8月に惜しまれつつも一切のソフトの開発・販売が終了となってしまった。
2024年をもって6周年を迎え、コイカツのスクリーンショットを元に生成AIのLoRA化を果たしてタペストリーやジグソーパズル他、AIイラスト集を出したところである。

これでも十分再現性は高いのだが、なにぶんコイカツの味がかなり強い状態になっている。
近い将来、イラストレーターさんが自分の画風を学習させた公式LoRAを所有するようになると予想して、その画風LoRAのノリを良く反映するようなキャラLoRAの制作をやっていきたい。
これまで培ってきた各種ツール、そしてネット上に公開されている情報を駆使してとにかく楽をするぞ。
まずは先人を参考にする
今回参考にしたのはこちらのエマノンさんの手法。
というか8割はそのまま。
まず、コイカツ上での様々なキャラクターのスクリーンショットを使って、コイカツLoRAを作る。このコイカツLoRAを使用してモデル化を行い、モデル単体でコイカツ風の出力を出来るようにする。さらにこのモデルを使用して目的のコイカツキャラクターLoRAを作るというもの。
考え方を整理する
イラストには以下の要素があると仮定する。

この内、「キャラ」だけを特徴として抽出できれば、モデルデータや他LoRAから持ち込まれた他の要素とミックスされて柔軟なポーズ付けや様々な画風表現に対応できるのではないかというもの。
LoRAの学習素材としてコイカツのスクリーンショットとして、その被写体キャラクターを多様化させ、服装やポーズ、画角、背景、画風を叩き込んで学習ファイル踏み台LoRAを作る。

LoRAは基本的に差分を特徴として拾うものなので、モデルデータと学習画像が近ければ近いほど作成するLoRAへの影響が少ないと仮定すれば、ポーズや服装はLoRAを適用した生成時にプロンプトを素直に受け入れやすくなってくれるはずだということ(だと思う)
上で作った踏み台LoRAをモデルにマージし、このモデルを学習用モデルとしてキャラクタの特徴分だけを残したLoRAを作成する流れ。

ここで重要になってくるのが以下のポイントである。
元モデルにおけるポーズや構図の出力の確認と、ジェネリックコイカツ画風の再現度
コイカツにおける多数のキャラや構図、ポーズのスクリーンショット
構図などは元モデルで色々と出力を試してみれば済むが、問題はスクリーンショットの方だ。エマノンさんもおっしゃっているがとんでもない数になる。例えば髪色6種、体型6種、髪型6種だけでも6x6x6で216キャラ、これに構図100種、ポーズ3種とするとスクリーンショット648000枚とかになる。
髪色、体型、髪型を全部違うものにして6キャラに抑えれば1800枚。
ポーズをとにかく固定化して1種にすれば12キャラにしても1200枚。
できるだけ頑張りたくないのでなにか作戦を考えなくてはいけない。
基にするモデルを調査する
今回使用するのはAnyLoRA。キャラクターLoRA制作用のベースモデルとしてとても優秀だそうだ。あまりよくしらんけど。
野梅LoRAの用途としてはアニメよりイラスト系のほうが需要が大きそうなので、AnyLoRAよりも新しいAnyLoRA Anime Mixは不適と判断した。
さて、このAnyLoRAでどんなポーズや構図が出力できるのかを調査することにする。ただし頑張らない範囲で。
ポーズを調べる
とはいっても、ポーズのプロンプトなどはよくわからないしコイカツで再現するのにあまりに複雑なのは避けたい。できればぼったち、もしくはTポーズやAポーズが望ましい。
ちなみに学習時の比較用出力に使われるのでControlNetのOpenposeなどは使えない(はず)
というわけでさっそくぼったちが出るかを試してみよう。

出たわ。
OK…これだけでいいわ。
構図を調べる
これもやっぱりどんな構図が効くかはわからないし、そもそもとして構図用のプロンプトもよくわかってない。いつもはせいぜいfrom sideとupper bodyもしくはfull bodyぐらいしか使ってない。
というわけで、プロンプトジェネレーターの選択肢を拝借してAnyLoRAでどれだけ適用できるのかを調べてみることにする。


とりあえず2つほど出してみたAnyLoRAの所感は以下の通り。
closeup shot, medium shotはほぼ同じ
intense closeup shot, extreme closeup shot, headshot, eye closeup shot, macro shotはほぼ同じ
half body photo, medium shotはほぼ同じ
half body photo, macro shot, long shotは化けやすい
extreme long shotはほぼ解釈できない
cowboy shotはカウボーイが混ざる
from front, front viewはほぼ同じ
from behind, back shotはほぼ同じ
from side, side viewはほぼ同じ
upside-downはなぜかパンツを見せてくる
こうなると使えそうなのは以下だろう。
full body shot
upper body
intense closeup shot
closeup shot
wide shot
from front
from behind
from side


では次に、カメラ位置の調査を行うこととする。とりあえず、プロンプトジェネレーターのカメラ位置のタブにあるfrom above, from below, low angle shot, birds-eye view, high angle shot, overhead shot, aerial view, ground-level shot, dutch angle shot, dynamic angleを全部試してみる

ざっくり見ていくと以下のような感じだ。
low angle shot, ground-level shot, dutch angle shotはあまり解釈できない
from above, birds-eye view, high angle shot, overhead shot, aerial viewはほぼ同じ
構図固定としてはdynamic angleはやっぱり使えない
するとfrom above, from belowだけで問題なさそうだ。
試してみる。

どうしてもガッチガチの指定というわけには行かないけど、だいぶ方向性は良くなってきた。
顔面と望遠をもうちょっと的確に拾いたいところではある。
まとめ
頭中心にはintense closeup shot, portraitを合わせ技にすることにした。
from frontでやや左、正面、やや右の3方向
from front, from aboveでやや左、正面、やや右の3方向
from front, from belowでやや左、正面、やや右の3方向
from behindでやや左、正面、やや右の3方向
from behind, from aboveでやや左、正面、やや右の3方向
from behind, from belowでやや左、正面、やや右の3方向
from sideで左右とやや前後の6方向
from side, from aboveで左右の2方向
from side, from belowで左右の2方向
合計28枚とする

次にへそから上のupper body
これも
from frontでやや左、正面、やや右の3方向
from front, from aboveでやや左、正面、やや右の3方向
from front, from belowでやや左、正面、やや右の3方向
from behindでやや左、正面、やや右の3方向
from behind, from aboveでやや左、正面、やや右の3方向
from behind, from belowでやや左、正面、やや右の3方向
from sideで左右の2方向
from side, from aboveで左右の2方向
from side, from belowで左右の2方向
合計24枚とする

膝上プロンプトとしてcloseup shotを使用。
これも
from frontでやや左、正面、やや右の3方向
from front, from aboveでやや左、正面、やや右の3方向
from front, from belowでやや左、正面、やや右の3方向
from behindでやや左、正面、やや右の3方向
from behind, from aboveでやや左、正面、やや右の3方向
from behind, from belowでやや左、正面、やや右の3方向
from sideで左右の2方向
from side, from aboveで左右の2方向
from side, from belowで左右の2方向
合計24枚とする

あまり安定しない…
全身プロンプトとしてfull body
これも
from frontでやや左、正面、やや右の3方向
from front, from aboveでやや左、正面、やや右の3方向
from front, from belowでやや左、正面、やや右の3方向
from behindでやや左、正面、やや右の3方向
from behind, from aboveでやや左、正面、やや右の3方向
from behind, from belowでやや左、正面、やや右の3方向
from sideで左右の2方向
from side, from aboveで左右の2方向
from side, from belowで左右の2方向
合計24枚とする

遠景プロンプトとしてwide shotを予定していたがこれも安定しないのでスキップ
取得するスクリーンショットと対応プロンプトの一覧
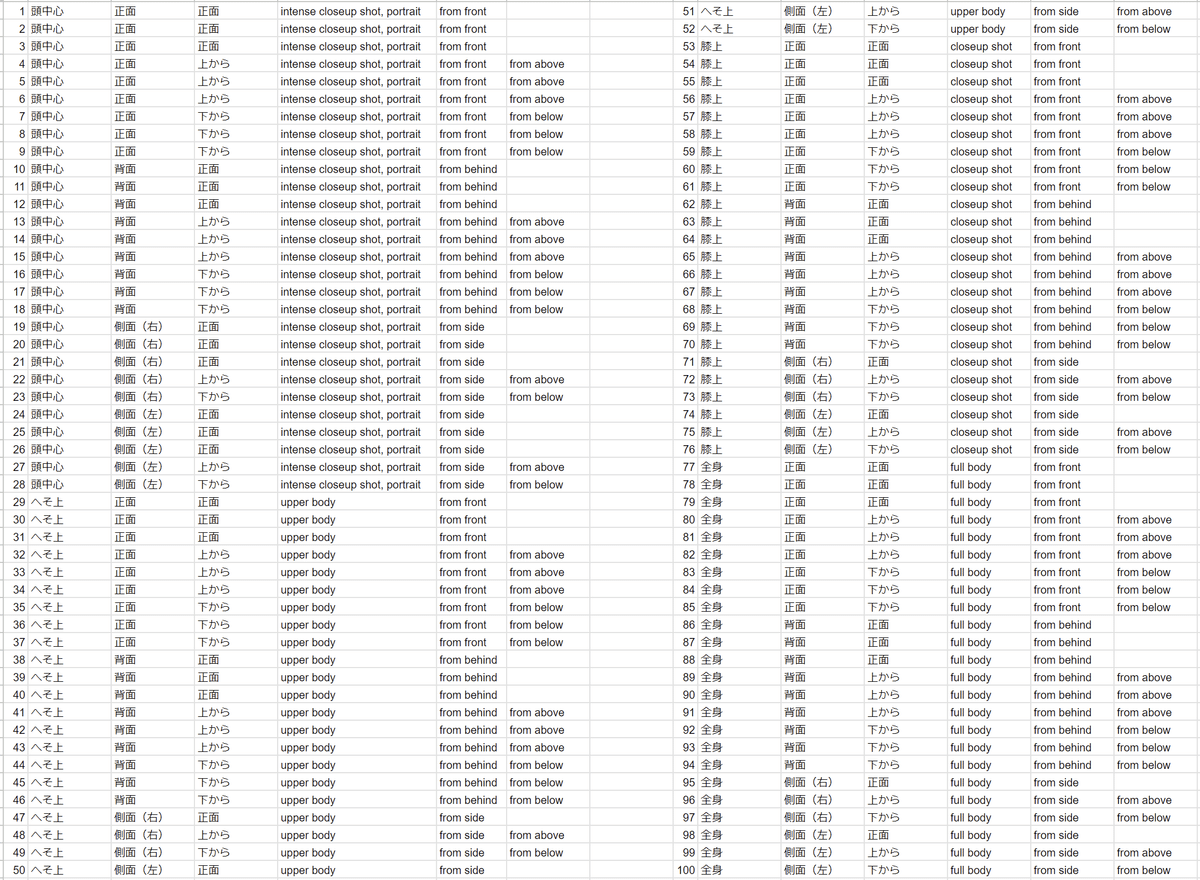
以上、頭中心、へそ上、膝上、全身の4種に方向を組み合わせた合計100枚でスクリーンショットを撮ることにする。
一覧にある通りプロンプトに対応する画像番号は以下とした。
頭中心:1~28
へそ上:29~52
膝上:53~76
全身:77~100
正面:1~9、29~37、53~61、77~85
背面:10~18、38~46、62~70、86~94
側面:19~28、47~52、71~76、95~100
上から:4~6、13~15、22、27、32~34、41~43、48、51、56~58、65~67、72、75、80~82、89~91、96、99
下から:7~9、16~18、23、28、35~37、44~46、49、52、59~61、68~70、73、76、83~85、92~94、97、100
コイカツでのスクリーンショット取得
さて、1キャラあたり100枚のスクリーンショットをどう撮るか…これにはスクリーンショット機能を使わずに、タイムラインアニメーション動画を活用する。どちらかといえばキャプチャーだ。
必要なものとしてはコイカツ(スタジオ)、タイムラインアニメーションMOD、ノードコンストレイントMOD、OBS、動画編集ソフトとなる。
スタジオのコンフィグ
可能な限り余計な要素入れたくないので、次の設定を行う。
白背景
被写界深度なし(奥のものがボケるエフェクト)
ブルームなし(照らされている部分が明るく輝くエフェクト)
ビネットなし(画面の四方が暗くなるエフェクト)
影は多分なんでも良い
キャラクターは次のものに固定する
全裸
アクセサリーなし
視線固定
無表情
Aポーズっぽいなにか
カメラの問題
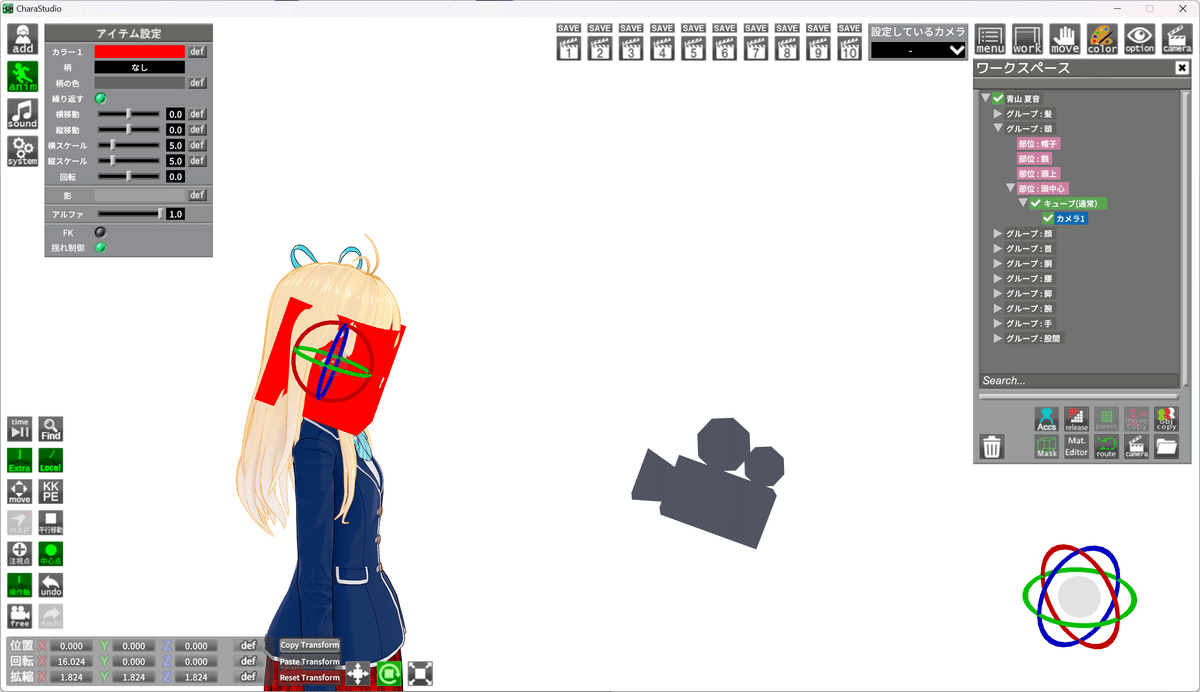
カメラの問題については以下の2枚のスクリーンショットを見れば分かる通り、カメラ位置や回転をキーフレームとして保存したとしても、キャラクターの座標基準が足元にあるため、身長の差によって簡単にズレてしまう。

これを解決するためにはカメラの基準点を頭中心にする。

キャラを切り替えてもカメラの位置が頭に追従する
さらに工夫をこらす。
このままカメラを回転させるとカメラの座標を基準として回転してしまう。

これを防ぐために、さらにもう一段適当なオブジェクトを挟み込み、カメラの回転中心座標としての役割を担当させる。そのオブジェクトのさらに子要素としてカメラを設定し、被写体からの距離は、オブジェクトとカメラの相対距離にする。
すると、キーフレームとしては中間オブジェクトの回転のみ保存すれば、キャラの身長差に対応しつつあらゆる角度からの画角を保存することが出来ることになる。
カメラの基準点を頭中心にするには、頭中心とカメラを親子関係にする。
上の画像の例ではキャラクターのボーンツリーで親子関係を持たせているが、今回は1つのオブジェクトが複数の親を渡る都合上、ノードコンストレイントMODを使うことにする。ノードコンストレイントMODは標準のワークスペースでの親子関係とは違うところで親子関係を構築するもの。タイムラインでのON/OFFに対応しているので、同じ子要素に対して複数の親を設定しておき、タイムライン上で親子関係を切り替えることでカメラの切り替えをせずに済ませるということになる。
タイムラインの設定
タイムラインは秒間30フレームでTimeを1、Scaleを30にするとタイムラインのグリッドが1フレームずつになる。
このグリッドに合わせてキューブの回転を正面9方向、後頭部9方向、側頭部左右20方向で28キーを登録した状態が以下の状態。
あとで正方形にトリミングするのでそのつもりでカメラに収める。

さらに、ノードコンストレイントの親子関係の切り替えとカメラの位置(キューブを基準としたカメラの位置関係)をキーフレームに入れたものが下のもの。

キューブ回転・・・カメラの向き
カメラ位置・・・・カメラの画角範囲
ノードコンストレイント対象切り替え・・・画角の中心位置
こんな感じの制御をタイムライン1つで行っていると考えてほしい。
キューブもカメラも共通なので、キューブの回転キーフレームをコピペすれば、複数画角も一発で対応できる。楽ちん。

こんな感じでキーフレームを組んだので、これで1キャラあたり3秒半で100フレーム取得できるはず。しかし、自分の機材の都合かわからないが、コイカツ側の再生フレームとOBSのフレームが微妙にずれることがあるので、再生速度を半分にした。タイムラインウィンドウの左下にあるTimeScaleを0.5にすれば速度が半分になるので7秒で200枚のスクショが撮れることになる。
カメラの動きを録画してみたので参考にどうぞ。
準備ができたので、OBSで録画しながらキャラクターを差し替えてタイムラインアニメーションを繰り返す。
次に大量のキャラクターだが、これはコイカツデフォキャラ35体を対象にした。
各種アクセサリーやメガネなどはすべて外した状態でタイムラインを再生、キャラクターを切り替える。
PremiereProでフレーム書き出す方法
説明用サンプルで説明する
OBSで撮影した動画のうち、キャラクターごとにタイムラインで再生されている先頭位置と終了位置を割り出して前後カットしたら、シーケンスを512x512サイズにする。

「書き出し」→「メディア」を選び、出力プリセットの中から「JPEGシーケンス」を選んで書き出す。

すると、指定したフォルダにすべてのフレームが書き出される。

コイカツで秒間30フレームを1/2倍再生したものを、OBSで30FPS録画しているので、理屈の上では同じ画像が2枚ずつあるはずなのだが、ごくたまにタイミングが合わない時があり、同じ画像が3枚続いて次のもの1枚しかなかったりするので、ここでチェックをする。
1列の画像が偶数になるようにエクスプローラーの横幅を調整すれば、かなり楽ができる。2段4段6段…でちょこちょこ消していけば、繰り上がってくるファイルも左端から始まるはずなので何も考えなくて良い。


次にファイルに連番を付ける。とはいってもリネームソフトなんかいらない。まず一番最後のファイルをクリックし、一番最初のファイルをShift押しながらクリック、そしてF2を押し適当な文字を入力。すると全ファイルに同名+()付きの連番を振ってくれる。

(本番は全裸)(JCB頑張れ)
それぞれ対応する番号は次のようになっているはずなので一応確認する。
いよいよ本番データ7600枚の撮影
OBSで録画しながらコイカツシーン上でタイムラインを再生してはキャラクターの入れ替えを繰り返した。そして、PremierProで録画データのうち必要な部分のみを切り出して繋げる。
本番ではXL学習を見越して512x512で作ったシーケンスを一旦ネストして1024x1024に拡大した。

スクリーンショットが全面映っているが、シーケンスに戻るとトリミングされた状態になっている
JPEGシーケンスで書き出したものがこちら。
コイカツ、コイカツSSデフォキャラ35体についでに撮影した野梅とデフォカスタム2体を追加した38体分100フレームx2重の7600枚の画像が出来た。

あとはこの選択部分のようにコマ飛びしている部分を補完するように画像数を半分にすれば完成だ。

そのための2フレーム撮影である
撮れて無いよりマシ(たぶん)
これはどうしても目視と手作業になるが、本来は1枚1枚コイカツスタジオでスクリーンショットを撮り正方形にトリミングする作業になることを考えると、やっぱりタイムラインを動画で撮ってシーケンスにする方法を取って良かった。かなり楽ができた。
というわけでなんとか38キャラ分3800枚まで手処理。
ただ、フレーム飛びして撮れていないのが15枚ほどあった。これらは削除作業の中で見つけ次第、撮れていない画像を残してメモを書き入れ、枚数だけは100枚きっちり揃えたうえでリネームまで施してから、マニュアルで追い撮影をすることにした。

割と大変だった

あとで改めてコイカツスタジオに戻って撮影する
キャプショニング
段階としてまずはデフォキャラ35体でLoRAを作成する。目指すところは「どうやって出力しても全裸白背景ぼったちガール」が出てくるLoRAである。
つまり全裸と白背景と立ちポーズは覚えさせる必要がある。
LoRAのキャプションは最初に「トリガーキーワード(今回は1girl)」を書き入れるため、この時点では具体的には以下の内容となる。
1girl(こいつにキーワードを集約させる)
カメラ情報(画角、向き、煽り/俯瞰)
キャラ特徴(髪色、髪型、ぺえ)
以上。
つまり、白背景(white background, simple background)や全裸(nude, nekid)、ポーズ(standing, arms at sidesなど)は記入しない。これは最終的なキャラクター学習時に確実に白背景全裸ぼったちを出したいからである。
キャプションファイル3500個を準備する
とりあえず、基本となる以下のプロンプトを入れたテキストファイルを適当なフォルダに用意する。
1girl, 画角, 向き, 煽り, キャラ情報ファイルが出来たら、Ctrl+A→C→Vで「フォルダ内のファイル全選択、コピー、貼り付け」を12回行う。すると4096個同じものが出来たはずなので、296個消して合計3800個にする。

あとは画像のときと同じように100個ずつリネームすれば、画像と同じファイル名のtxtファイルになりこれがこのままキャプション用ファイルとなるので、学習に使うフォルダに画像と一緒に格納しておく。自分の場合は38キャラ中35キャラが今回の学習対象なので7000ファイルのフォルダになった。

VS Codeを使って3500ファイルを簡単編集
VS Codeで格納したフォルダを指定。
VS Codeでは次の画像のように検索置換時に対象ファイル名を正規表現で指定することができるので、さっきテキストファイルに入れた「画角」などを一気に必要なプロンプトに置き換えていくことができる。
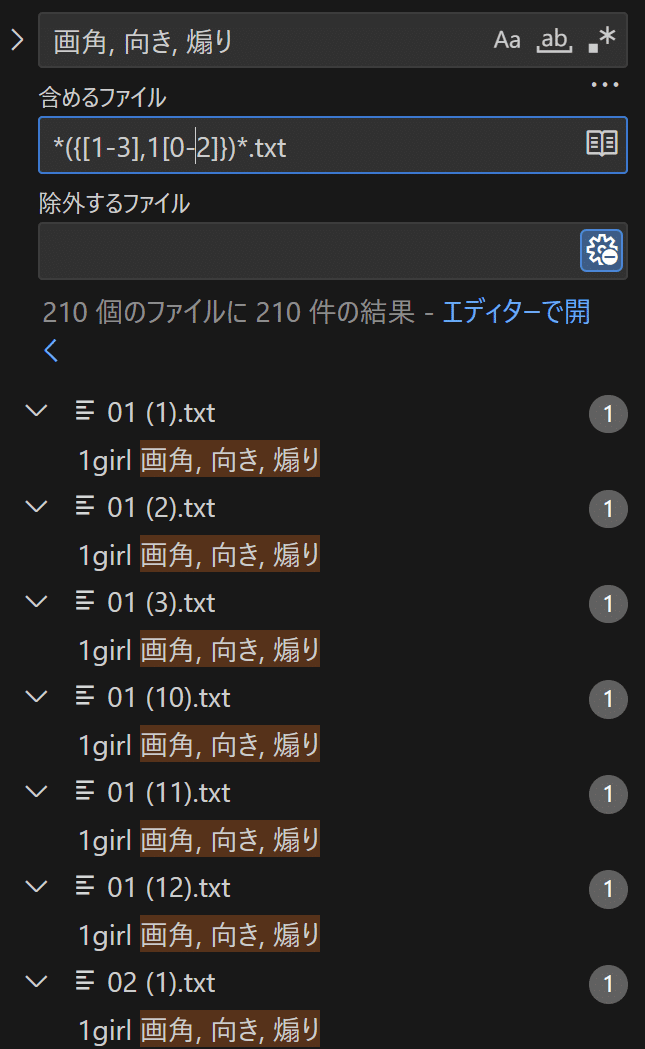
例えば、35キャラテキストファイルの(1)~(28).txtを対象に、「画角」を「intense closeup shot, portrait」に置換する場合は次のように書く。1キャラあたり28枚なのでx35で980ファイルが対象のはず。

ちなみに、GoogleIMEを使っているなら「28*35=」と打ち込むだけで計算結果を変換候補部分に出してくれるぞ。簡単だね。

検索置換の一覧は次の通り。
頭中心:1~28
検索:画角
置換:intense closeup shot, portrait
含めるファイル:*({[1-9],1[0-9],2[0-8]})*.txtへそ上:29~52
検索:画角
置換:upper body
含めるファイル:*({29,3[0-9],4[0-9],5[0-2]})*.txt膝上:53~76
検索:画角
置換:closeup shot
含めるファイル:*({5[3-9],6[0-9],7[0-6]})*.txt全身:77~100
検索:画角
置換:full body
含めるファイル:*({7[7-9],8[0-9],9[0-9],100})*.txt正面:1~9、29~37、53~61、77~85
検索:向き
置換:from front
含めるファイル:*({[1-9],29,3[0-7],5[3-9],6[0-1],7[7-9],8[0-5]})*.txt背面:10~18、38~46、62~70、86~94
検索:向き
置換:from behind
含めるファイル:*({1[0-8],3[8-9],4[0-6],6[2-9],70,8[6-9],9[0-4]})*.txt側面:19~28、47~52、71~76、95~100
検索:向き
置換:from side
含めるファイル:*({19,2[0-8],4[7-9],5[0-2],7[1-6],9[5-9],100})*.txt上から:4~6、13~15、22、27、32~34、41~43、48、51、56~58、65~67、72、75、80~82、89~91、96、99
検索:煽り
置換:from above
含めるファイル:*({[4-6],1[3-5],22,27,3[2-4],4[1-3],48,51,5[6-8],6[5-7],72,75,8[0-2],89,9[0-1],96,99})*.txt下から:7~9、16~18、23、28、35~37、44~46、49、52、59~61、68~70、73、76、83~85、92~94、97、100
検索:煽り
置換:from below
含めるファイル:*({[7-9],1[6-8],23,28,3[5-7],4[4-6],49,52,59,6[0-1],6[8-9],70,73,76,8[3-5],9[2-4],97,100})*.txt煽り方向未指定:1~3、10~12、19~21、24~26、29~31、38~40、47、50、53~55、62~64、71、74、77~79、86~88、95、98
検索:, 煽り(カンマ+スペースも対象)
置換:(空白)
含めるファイル:(空白)
(上からと下からの変換がすべて完了していることが前提)
あとはキャラクターごとに髪色、髪型、ぺえのサイズなんかを入れていく。
キャラクターの特徴はStableDeffusionのTaggerを使って抽出すると楽。

キャラによっては前髪や髪の結びなども出てくるのでこれも使う
ぺえの情報はupper body以上の画角のみに入れる
01 (1).txt~01 (100).txtを指定するには次のようにする。これで各キャラクターごとの100ファイルに一気に髪色その他諸々を検索置換できる。
*01 ({[1-9],1[0-9],2[0-9],3[0-9],4[0-9],5[0-9],6[0-9],7[0-9],8[0-9],9[0-9],100})*.txtすべての置換作業が終わると、例えば18 (56).txtは次のようになっている。
1girl, closeup shot, from front, from above, short hair, purple hair, purple eyes, hair between eyes, gradient hair, small breastsこれで3500件のキャプショニングは完了。せいぜい30分。これを35キャラ分手作業でやってたら危なかった。死んでいたかもしれない。
LoRAとモデルの制作
まずは踏み台LoRA制作から
LoRAはkohya ss GUIを利用する。
値関係はとりあえず先行者のものをベースとして、今回は非XLで作る。っていうかXLで作ろうとしたらエラーが起きた。
欲張ってエポック数20、バッチサイズ4にしたら、3500枚もあったせいかステップ数84500とかになってしまってPCが延々と唸っている。ちなみに今日は6月7日。日中気温は25度。もはや初夏の陽気の中いかがお過ごしでしょうか。

PC落ちて完走できませんでした。
改めて、Grok氏のkohya ss GUI用の画風学習用プリセットStyleLoraLearning1をお借りしてLoRA制作を進めることとする。
なお画像は512x512にリサイズした。
プリセットのおかげか画像サイズの影響かはわからないが、全体ステップ数の割にはサクサクと学習が進んでくれている。現時点で1時間半で17500ステップ。最初の学習はなんだったんだちくしょう。

ステップ数自体は前回の半分とは言え…
さて、この踏み台LoRAも何度も四苦八苦する羽目になった。
具体的には白背景を出そうとすると白髪のキャラがどうしても出てくるのだ。その状態で本チャンキャラデータを作っても白髮になって出てくるようになってしまった。

最終的に、髪の色素が薄い5キャラを削除し30キャラ3000枚で学習することにした。
踏み台LoRAとモデルのマージ
LoRA制作では他のLoRAを使うことが出来ないので、事前にモデルにマージをしておいてモデル単体だけで出力ができるようにする。
今回はエクステンションのSupermargeを利用することにした。
導入方法はromptnAIさんを参考にした。https://romptn.com/article/19894romptnAI
LoRAとのマージはelnaさんの記事を参考にした。
さてマージするモデルだが、予定ではここでもAnyLoRAを使う予定だったが、白背景がなかなか安定して出ないためHimawariMixV11を使った。

絵の破綻のなさを重視してちょうどいいところを探す
プロンプトが「1girl」の1つだけでここまで出せるモデルができたので、とりあえずこのモデルを「deKK」と名付けた。
これをLoRA制作時のモデルに指定する。
正則化をする(出来なかったので飛ばして良い)
残念ながら正則化について詳しく解説しているサイトは見つからなかったので手探りでいくことにする。
とりあえずとしあきを頼ることとする。
LoRAの教師画像と同様にキャプションファイルをまとめたフォルダを指定するということでいいのだろうか。
エマノンさんによると、
そしてここが大事なポイントなのだが、手順1で使用した画風の学習素材を正則化画像として使用する。num_repeatsは1でよい。
モデルに対して強く学習させた画像群なので、正則化画像として非常に適しており、この正則化画像を使用することでLoRA使用時の不要な画風への影響を大きく抑えられる。
…とのことなので、踏み台LoRAの教師画像に使った3500枚を全部突っ込むことにする。
正則化画像は、キャプションファイルの効果としてプロンプトの内容を詳しく説明し、教師画像からその要素を抜くためのものだそうだ。
なので、踏み台LoRAを作ったときのキャプションに加えて、教師画像で覚えさせたくない共通要素を更に盛り込む。

細字が踏み台LoRAのときのキャプションで、太字が追加部分。
教師画像のキャプショニング
正則化画像の追加部分については、教師画像側のキャプションにも含めた。

一方で細字部分については、先頭にはトリガーワードを追記したほかは、踏み台のときと同じように各番号に基づいた画角や向きを記入している。
また、Ebycow氏によると、「各{繰り返し回数}は「学習用画像の繰り返し回数×学習用画像の枚数≧正則化画像の繰り返し回数×正則化画像の枚数」となるように設定すること」ということなので、教師画像100枚に対して正則化画像3500枚なので35回のリピート数となる。すっげ。
正則化画像を含めたフォルダ構成は次のようにした。
├ noume(トレーニング時に教師画像として指定するフォルダ)
│ ├ 35_noume(「リピート回数」_「トリガーワード」)
│ │ ├ 各画像100枚
│ │ ├ 各キャプションファイル100個
└ reg(トレーニング時に正則化画像として指定するフォルダ)
└ 1_noume(「リピート回数」_「トリガーワード」)
├ 各画像3500枚
└ 各キャプションファイル3500個結果はこちら。

一番上がLoRA強度1で下に行くに連れ0.1ずつ減少。
明らかに正則化画像に食われた。
食われたと言っている要因としては、これの前にテストした正則化画像を使わなかった簡易版LoRAで見事にコイカツ風味が消えてマスピ顔が貫通したからだ。

正則化は諦めた ゲッゲッゲ
kohya氏も単一キャラのLoRAなら正則化いらんいうとるらしいしね(元ファイル欠損のため1次ソースの確認はできず)
正則化を諦めて、いよいよ本番LoRA制作
教師画像のキャプショニングも終えたらいよいよ本番LoRAの制作に移る。
またしても、Grok氏のkohya ss GUI用の画風学習用プリセットをお借りする。今度はcharaAndcosLoraLearningを使用。
学習モデルは30人のデフォキャラ画像3000枚をファインチューンしたLoRAとHimawariMixを合成したオリジナルモデル「deKK」。
それ以外はプリセットをベースにdimを64にしたぐらい。
その結果が以下である。


かなりの精度でLoRA無適用に近いもの(一番右下)からほぼと言っていいほど背景もポーズも破綻しないように出来上がった。さすがに強度が強いと線がざわつくし、モデルのコイカツらしさを妥協したせいか、どうしてもコイカツっぽさが出てきてはしまうが、それでもかなり抑えられていると思う。

ちなみにキャラとして「成立した」とする最低ラインは、猫耳内の耳毛の色、髪の毛のグラデーション、クロスヘアピン、オレンジから紺色に変化する瞳の色、左かき上げ姫カットが再現されているかどうかとしている。

本来はローマウントの猫耳も条件に入れたい
出力テスト
今回は7エポック目を拾って完成とした。
ここで作例をひとつまみ。モデルはHimawariMixV11。






あらゆる角度からの学習を行ったおかげか、前面側面背面、煽りも俯瞰もとてもよく再現できていると思われる。
以前コイカツスクショからダイレクトに学習したLoRAと比較したのが以下。

noume-000007:今回制作したとにかくコイカツ味を消したV3(予定)
(文字化けしてるけど)野梅V2:LoRA学習用にコイカツスタジオで白背景+様々なポーズで撮りまくった画像で学習したもの。極端にコイカツ再現度が高く、色味もほぼ完璧に出力される。
(文字化けしてるけど)野梅:それまで撮っていたコイカツのシーンデータを流用した初代LoRA(V1)。コイカツシーン上で設定されているポストエフェクトまでも反映し、イラスト風の雰囲気が強いモデル。お手軽。
一番右はLoRA適用なし。これをベースにどれだけ野梅のキャラ要素のみを入れられるかを今回のテーマにしている。
こうしてみると、V1、V2に共通するコイカツらしさはV3(予定)ではかなり消え、LoRAなしのポージングや構図が貫通しやすくなっているのがわかる。キャラクターとしての特徴は残しつつマスピ画風が乗っかってきた印象に仕上がった。
他のLoRAのノリ具合の確認
次は、他のスタイル系LoRAのノリを確認してみる。
以下はAnime Lineart / Manga-like Style LoRAを入れてみたところ。

ほぼ完璧に色情報が抜けたのは最新版だけ
おまけ
おまけとして、今回100枚のスクショを撮ってあったデフォルトキャラクターのカスタム仕様をLoRA化したので、その結果をお知らせしたい。
コイカツデフォキャラ モジモジ担当飯田佐奈カスタム

好みの都合でメカクレショートをメガネセミロングにした。
やめてくれ殺さないでくれ…っ!
特徴としては瞳の真ん中まで下がる前髪と困り眉、ぺえは並。

Premiereでフレーム単位で切り出して教師画像を用意したところ
出来あがったLoRAでテストショットしたのがこちら。



再現度バカ高くて笑ってる。
ただ細かいこと言うと、髪を変なふうに学習してしまっているため、横髪の後半付近で謎のブロックがくっついてくるところをなんとかしたい。

コイカツデフォキャラ のじゃ担当坪田音々カスタム

髪型をいわゆるお嬢様結びであるロングハーフアップにサイドロックを追加。ポニー部は大増量。
眉を細くしたりそれ以外も細かく調整している。
眉は髪貫通だが再現されるかどうか・・・。
もう一つ、上にも書いた白背景問題があった時にこのデフォのじゃの坪田音々は教師画像から除外している。これがどう作用するか…。

これで作ったLoRAで出力した例がこちら。



よく出来ているように見えるが、紫がかった髪と瞳の再現は出来ていない。横髪も中途半端。前髪は完璧なのにな。
また、ハーフアップとポニーテールの組み合わせに問題があるようで、これらが同時に反映されにくいみたい。ただのポニーテールになることがほとんど。
再現度は10点満点中4点かなぁ。かわいいはかわいいけど。
というわけで
無事、自分の画風LoRAを持っているイラストレーターに向けたV3が完成したので、これをBoothにアップしました。自分の画風LoRAとセットにして適用することで、野梅のイラスト制作に大きく寄与することになるかと思います。
タイムラインを記録したコイカツシーンデータやコイカツ学習用モデル「dekk」のシェアについては相談してほしい。(容量デカいから)
自キャラを持っている人があらゆるイラストレーターに対してリーチできるようになってくれればいいなと思う。
なんやかんやいわれとります生成AIだけど、描く側も描かれる側もよきイラストライフになることを願ってます。