
レーベンシュタイン距離について分かりやすく解説します

Google検索で、検索ワードを間違えて入力し、Googleから「こちらのワードで代わりに検索しますか?」と言われたことありませんか。

検索ワードの間違いを自動で修正して、
正しい(と思われる)ワードを返してくれるなんて凄くないですか。
これ、レーベンシュタイン距離を使って実現されています。
この記事では、ビジネスでの応用例も多い、レーベンシュタイン距離について解説していきます。
また、レーベンシュタイン距離はPythonを使えば簡単に実装できます。
後半ではその実装方法もご紹介していきます。
📌レーベンシュタイン距離とは
簡単に言うと、ある文字列Aと別の文字列Bを比較した時に、二つの言葉がどの程度異なっているかを示す尺度です。
もう少し具体的に言うと、文字列Aを文字列Bに変えるために、文字の置換・削除・挿入を何回行う必要があるか?を計算し、その回数がレーベンシュタイン距離となります。
日本語では編集距離とも言います。
この呼び名の方が、しっくりくるかもしれません。
実際に例を使って見てみましょう。
orangeとgrapeの二つの文字列のレーベンシュタイン距離を考えます。
orangeをgrapeに変えるためには、何回、文字の編集を行う必要があるでしょうか?
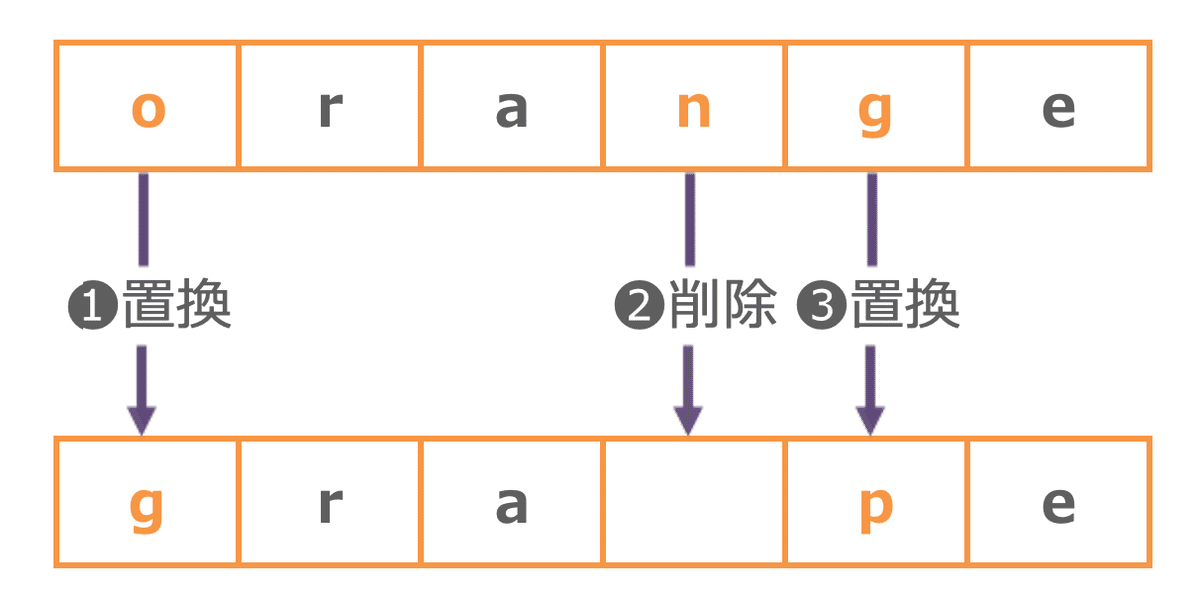
置換→削除→置換の計3回ですね。
orangeとgrapeのレーベンシュタイン距離は3ということになります。
文字の類似度は、レーベンシュタイン距離が小さいほど似ていて、大きいほど似ていないということになります。
📍標準化について
レーベンシュタイン距離は比較する文字数が多いほど、大きくなりやすいので注意が必要です。
例えば、二つの文字列を比較して、レーベンシュタイン距離が2だったとしても、比較する文字列が5文字だったときと、10文字だった時では意味合いがことなります。
そこで、距離を文字列の長さで割り返すことが一般的です。これを標準化とよびます。
レーベンシュタイン距離が2で、文字列が5文字だったときは0.4、文字列が10文字だったときは0.2となり、10文字の方が似ていると判断できます。
🖋️ビジネスでの活用例
レーベンシュタイン距離を使えば、単語や文章の誤りを見つけ、自動で修正する(あるいは正しいと思われる候補を表示してくれる)ことが可能です。
まだまだ、人間が手入力をしなければならない業務が多い中、その入力ミスのチェックを自動で行えるうえに、正しい用語に修正してくれれば、業務の効率化が進みますね。
🐥Pythonによる実装方法
Pythonには、レーベンシュタイン距離や類似度を1行で計算できるライブラリーがあるので、簡単に実装できます。
実装例として二つのデータフレームを用意します。
df1から見て、df2の単語の中で最も類似度が高い単語を抽出するとともに、その類似度とレーベンシュタイン距離を算出したいと思います。

GoogleColaboratoryで実装します。
ライブラリーのインストール
!pip install Levenshteinライブラリーのインポート
import pandas as pd
import numpy as np
from Levenshtein import ratio, distanceデータフレームを用意
df1 = pd.DataFrame({"word":["appli","banana","lennon","grap","おざなり"]})
df2 = pd.DataFrame({"target":["grape", "apple", "banana", "lemon","なおざり"]})類似度とレーベンシュタイン距離を計算する関数を作成し実行
def find_closest_word_and_similarity(word, correct_words):
if correct_words.size > 0:
# 各単語とのLevenshtein類似度を計算
similarities = [ratio(word, correct_word) for correct_word in correct_words]
# 最大類似度の単語とその類似度を返す
return
correct_words[np.argmax(similarities)],
np.max(similarities),
distance(word, correct_words[np.argmax(similarities)])
else:
return None, 0, len(word)
# 'closest_word', 'similarity'と'incorrect_count'を一度に計算
df1['closest_word'], df1['similarity'], df1['distance'] =
zip(*df1['word'].apply(lambda x: find_closest_word_and_similarity(x, df2['target'].values)))
df1
ちゃんと計算できていますね。
😊さいごに
文字列のような非構造化データは、これまで扱いにくかったところがありましたが、自然言語処理技術の発展や、Pythonライブラリーのおかげで、ずいぶん扱いやすくなりました。
このような自然言語処理系の技術は、ビジネスにどんどん取り入れていきたいものです。
いいなと思ったら応援しよう!
