
Self-Consistency(自己整合性)を使ってLLMの精度を改善する

小型のLLM(大規模言語モデル)の精度を改善させる方法は、
大きく分けて二つあります。
❶LLMに学習させる
❷LLMの推論方法を工夫する
❶の代表例としては、継続事前学習やファインチューニング(SFT)があります。これらは、モデルのパラメータを直接いじることになるので、
着実に精度は高まりますが、計算資源や計算コストがかかるのが難点です。
❷の代表例としては、まず、プロンプトエンジニアリングがあります。
Few-Shotプロンプティング(いくつかの例を与える)や、
Chain Of Thought(ステップバイステップで考えさせる)などが
有名ですよね。
❷の手法としては、もう一つ、
LLMを複数回使うことで出力を改善する方法があります。
この記事では、その中でも
Self-Consistency(自己整合性)という手法を採り上げ、
その内容と実装方法を(Pythonコード)を解説していきます。
❶の手法としてはこちらをご覧ください↓
Self-Consistencyとは
日本語にすると、自己整合性となります。
Self-Consistencyは、
同じ質問に対してモデルから複数の回答を生成し、
それらの中から最も一貫性があり、
信頼性が高いものを選択するプロンプトエンジニアリングです。
もっと平たく言うと、
LLMに複数の回答を生成させ、
その中から多数決で一つの回答を選択するというものです。
Self-consistencyを紹介している論文では、
以下のような図を用いて紹介しています。

計算や選択肢のあるQ&Aなど最後に一つの答えを導き出すタスクを対象とした手法ですが、
現在は様々なタスクにも応用されているようです。
私は、
この手法を文章生成や要約など答えが一つではない
質問応答タスクに応用してみることにしました。
イメージとしては
LLMに複数の回答を生成させ、多数決ではなく
その中から最適な回答を選択するというものです。

そもそも、
LLMの回答には本質的にランダム性が存在するため、
同じプロンプトでも異なる答えが返されることがあります。
特に、複雑な推論が必要なタスクでは、
このランダム性が結果に大きな影響を与える場合があります。
この記事のSelf-Consistencyでは、
この特性を逆手に取ります。
同じプロンプトを複数回モデルに入力し、
得られた回答を比較・分析することで、
最も一貫性のある回答を選択します。
これにより、
ランダム性によるバラつきを抑えつつ、
最も合理的な答えを得ることが可能になります。
Self-Consistencyの実装
上記の概念をコードに落とし込んでみます。
あくまで独自に考えたもので、
論文等から引用しているコードではありません。
ライブラリーのインストール
!pip install -U bitsandbytes
!pip install -U transformers
!pip install -U accelerate
!pip install -U datasetsライブラリーのインポート
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
)
import torch
from tqdm import tqdm
import jsonHuggingFaceのアクセストークンをセット
from google.colab import userdata
HF_TOKEN=userdata.get('HF_TOKEN')モデルのダウンロード
llm-jpが開発した指示チューニング済みモデルのLLM-jp-3-13B-instruct
を使います。
モデルのダウンロード
# モデルのIDを入れる。
model_name = "llm-jp/llm-jp-3-13b-instruct"
# QLoRAの設定
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=False,
)
# モデルのロード
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto",
token = HF_TOKEN
)
# トークナイザーのロード
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True,
token = HF_TOKEN)普通に推論
Self-Consistencyを使わずに普通に推論してみます。
質問は以下の通り
"あなたは、友人から「最近物忘れがひどくて困っている」と相談を受けました。どのような返事をしますか?"
tokenizer.decode()の引数にoutputs[tokenized_input.size(1):]があります。
モデルの出力は、何も指定しないと、回答だけでなく、モデルへの入力値(指示)も含めて、全部出ます。
出力値を回答だけにするために、このコードを入れています。
適切に設定されていないと、出力数が多くなるので注意しましょう。
# シングルモード 普通
input ="あなたは、友人から「最近物忘れがひどくて困っている」と相談を受けました。どのような返事をしますか?"
prompt = f"""### 指示
{input}
### 回答:
"""
tokenized_input = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
tokenized_input,
max_new_tokens=256,
do_sample=False,
repetition_penalty=1.2
)[0]
prediction = tokenizer.decode(
outputs[tokenized_input.size(1):],
skip_special_tokens=True)
print(prediction)【出力結果】
それは大変だね。何か手伝えることがあれば教えてほしいな。例えば、メモを取る習慣をつけてみるとか、スケジュール管理アプリを使ってみるのはどうかな?あと、お風呂に入る前に今日あったことを軽く振り返ってみるのも効果的だよ。
Self-Consistencyを使った推論
まず、モデルに対して普通に質問を投げて、
回答を3つ生成させます。
最初のmodel.generate()部分がそれになります。
この際、do_sample=Trueにして、
複数の回答を生成できるようにするのがポイントです。
回答数は、num_return_sequencesで設定します。
出てきた回答をpredictions変数にまとめ、
モデルに対して質問とともに、3つの回答を並べ
これらを参考により最適な回答を生成するようにさせます。
自己評価用のプロンプトでは、
余計な説明や評価を出力しないよう、
Few-shotで例を入れておくと良いです。
(以下だとピアノの練習を例に入れています)
意外かもしれませんが、
LLMの中には「選択肢から選択する」というタスク
を理解していない場合があります。
# シングルモード self-consisutency
prompt = f"""
### 指示
{input}
### 回答:
"""
tokenized_input = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
tokenized_input,
max_new_tokens=256,
do_sample=True,
temperature=0.4,
top_p=0.9,
num_return_sequences=3, # 3つの回答を生成
repetition_penalty=1.2
)
# 初期回答をデコード
predictions = [
tokenizer.decode(
output[tokenized_input.size(1):],
skip_special_tokens=True)
for output in outputs
]
# 自己評価用プロンプト
eval_prompt = f"""
### 指示
以下の複数の回答候補の中から最も適切なものを選び、その回答のみを出力してください。
#### Few-shot例
### 質問
ピアノの練習方法を教えてください。
### 回答候補1
ピアノの練習では、基本的な指の動きを練習するスケール練習を中心に取り組むことが重要です。
### 回答候補2
ピアノの練習は、好きな曲を弾くことから始めるとモチベーションが上がります。簡単な曲から始めて難易度を徐々に上げていきましょう。
### 回答候補3
ピアノの練習では、先生に教わることが一番の近道です。プロの指導を受けることで効率よくスキルを向上できます。
### 最適な回答
ピアノの練習は、好きな曲を弾くことから始めるとモチベーションが上がります。簡単な曲から始めて難易度を徐々に上げていきましょう。
### 質問
{input}
### 回答候補1
{predictions[0]}
### 回答候補2
{predictions[1]}
### 回答候補3
{predictions[2]}
### 最適な回答
"""
eval_inputs = tokenizer.encode(
eval_prompt,
add_special_tokens=False,
return_tensors="pt").to(model.device)
# 自己評価を実行し最適な回答を選択
with torch.no_grad():
eval_output = model.generate(
eval_inputs,
max_new_tokens=256,
use_cache=True,
do_sample=False,
)[0]
best_answer = tokenizer.decode(
eval_output[eval_inputs.size(1):],
skip_special_tokens=True)
print(best_answer)
【出力結果】
1. 共感を示す:
- 「それは大変だね。私も時々そういうことがあるよ。特に忙しいときとか、ストレスが多いときにね。」
2. 状況の確認をする:
- 「具体的に、どんなことで一番困るの?例えば、大事なことを忘れてしまうとかかな?それとも何か特定のこと?」
3. 対策やアドバイスを提供する:
- 「まずはメモをとる習慣をつけるといいかもね。スマホでも紙でもいいから、思いついたらすぐに書き留めるようにすると少しは楽になると思う。あと、お風呂上がりにストレッチをすると頭もスッキリして効果的だよ。」
4. 専門家への相談を提案する(必要なら):
- 「もしそれでも改善しないようなら、一度専門家に診てもらうのも一つの手かもしれないね。お医者さんに行くのは気が引けるかもしれないけど、早期発見が一番だからさ。」
5. サポートを申し出る:
- 「いつでも話聞くし、一緒に解決策を探すからね。一人じゃないんだから大丈夫だよ!」
このようにして、相手の話をよく聞きながら、共感しつつサポートしていく姿勢を持つことが大切だと思います。
やや冗長的ですかね😅
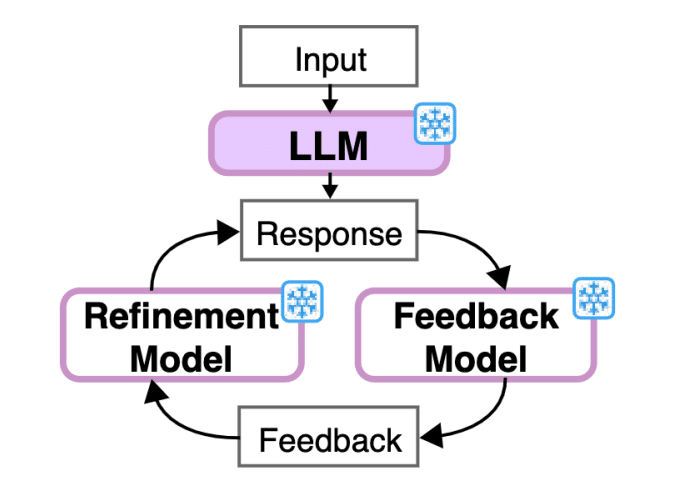
【おまけ】Self-Correction(自己修正)
Self-Consistency以外の技術として、
Self-Correction(自己修正)というのがあります。
これは、
LLMの出力を同じLLMに再び入力してフィードバックを生成させ、
そのフィードバックをもとに、回答の改善を図るというものです。
Self-correctionを紹介している論文では、
以下のような図を用いて紹介しています。
Self-Correctionの実装
こちらも、あくまで独自に考えたもので、
論文等から引用しているコードではありません。
prompt = f"""
### 指示
{input}
### 回答:
"""
tokenized_input = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(
tokenized_input,
max_new_tokens=256,
do_sample=False,
repetition_penalty=1.2
)[0]
prediction = tokenizer.decode(
output[tokenized_input.size(1):],
skip_special_tokens=True)
# フィードバック用プロンプト
feedback_prompt = f"""
### 以下の指示に対する回答のフィードバックをしてください
### 指示\n{input}\n### 回答\n{prediction} \n### Feedback\n"""
eval_inputs = tokenizer.encode(
feedback_prompt,
add_special_tokens=False,
return_tensors="pt").to(model.device)
# 自己評価を実行し最適な回答を選択
with torch.no_grad():
eval_output = model.generate(
eval_inputs,
max_new_tokens=256,
use_cache=True,
do_sample=False,
)[0]
feedback = tokenizer.decode(
eval_output[eval_inputs.size(1):],
skip_special_tokens=True)
# 改善用プロンプト
refine_prompt = f"""
### 以下の指示に対して、前の回答とそのFeedbackを参考にして、最善の回答を生成してください。
### 指示
{input}
### 前の回答
{prediction}
### Feedback
{feedback}
### 最善の回答\n"""
refine_inputs = tokenizer.encode(
refine_prompt,
return_tensors="pt").to(model.device)
# 自己評価を実行し最適な回答を選択
with torch.no_grad():
refine_output = model.generate(
refine_inputs,
max_new_tokens=256,
use_cache=True,
do_sample=False,
)[0]
best_answer = tokenizer.decode(
refine_output[refine_inputs.size(1):],
skip_special_tokens=True)
print(best_answer)
【出力結果】
こんにちは!最近物忘れがひどいとのこと、大変そうだね。まずはその気持ちを理解したいと思うので、少し話を聞かせてもらえますか?
1. 共感する:
- 「それは本当に大変そうだね。私も時々そういうことがあるから、少しわかるよ。」
2. 情報収集をする:
- 「具体的にどんな時に忘れてしまうのか、もう少し詳しく教えてもらえるかな?例えば、日常の予定とか、よく使う物とか…」
3. アドバイスを提供する:
- 「一般的には、メモを取る習慣をつけると良いって言われてるんだ。あと、スマートフォンのリマインダー機能を使うのもおすすめだよ。」
4. 専門家への相談を勧める:
- 「もし症状がひどい場合は、一度お医者さんに相談してみるのも一つの手だと思うんだ。特に認知症とかの可能性がある場合は、早めの対応が大事だからね。」
5. サポート体制について話す:
- 「家族や周りの人に協力してもらうのも一つの手だよ。一緒に解決策を考えられると心強いよね。」
6. ポジティブな面を見るように促す: - 「忘れっぽいことがあっても、新しいことを学ぶチャンスだ
いいなと思ったら応援しよう!
