
【Python】EDINETから有価証券報告書のPDFを一括取得する

EDINETは、
金融庁が提供するオンラインシステムで、
上場企業等の有価証券報告書などを取得することが可能です。
この記事では、
PythonとEDINETのAPIを使って
複数の有価証券報告書のPDFファイルを
一括取得する方法をご紹介します。
以下に掲げる方、必見です!
上場企業等で有価証券報告書の作成に携わっている方
有価証券報告書や株式市場の分析をしている方
自然言語処理に関心のある方
1. APIの利用準備
EDINETのAPIを利用するには、
1. EDINET APIのアカウントを作成する
2. EDINETから発行されるAPIキーを取得する
必要があります。
詳細な手続きはこちらのPDFファイルのP6〜P19に記載がありますが、
PDFをダウンロードしなくても、以下で簡単に説明していきます。
アカウントの作成
まず、EDINET APIのアカウントを作成します。
次のURLにアクセスし、「今すぐサインアップ」をクリックします。
あとは、画面の指示に従います。
https://api.edinet-fsa.go.jp/api/auth/index.aspx?mode=1
APIキーの発行
アカウント作成で多要素認証が終わると、
APIキー発行画面に変わります。
連絡先を入力し、「連絡先登録」をクリックすると、APIキーが表示されます。

これでめでたく、EDINET APIが使えるようになりました。
2. GoogleコラボのシークレットにAPIキーを登録
この記事では、Googleコラボを使って実装していきます。
Googleコラボで、安全にAPIキーを使用するために、
GoogleコラボのシークレットにEDINET APIキーを登録しておきます。
シークレットへの登録方法はこちらをご覧ください。
超簡単に登録できます!
Googleコラボ上で、EDINET APIを使えるようにします。
シークレットにEDINET_APY_KEYという名前で登録した前提です。
# EDINETAPIのトークンを取得する
from google.colab import userdata
edinet_api_key = userdata.get('EDINET_API_KEY')3. docID(書類管理番号)の取得
EDINETはひとつひとつの文書を
一意のdocID(書類管理番号)で管理しています。
有価証券報告書を取得するためには、
まず、その有価証券報告書に紐づくdocIDの取得が必要になってきます。
docIDを取得するためのクラスの定義
クラスの中身は次のようになります。
# 1 コンストラクタ・日付リストの作成
クラスの引数として、取得したい書類の提出日をスタート日とエンド日で指定します。
docIDは書類の提出日で管理されています。
# 2 レポートリストの作成
指定した期間中において提出された有価証券報告書の情報をリストで取得します。
formCode :030000が有価証券報告書を示します
# 3 データフレームの作成と保存
提出者の業種情報を取得するため、EDINETから最新のEdinetCodelistをDLします。
先ほどのレポートリストとmergeして、データフレーム化します。
import requests
import datetime
import pandas as pd
import time
import zipfile
import warnings
from tqdm.notebook import tqdm
import io
# 警告を特定のものに限定する
warnings.filterwarnings('ignore', category=DeprecationWarning)
class GetDocid:
# 1 コンストラクタ・日付リストの作成
def __init__(self, start_date, end_date):
self.start_date = start_date
self.end_date = end_date
self.day_list = self.create_day_list()
def create_day_list(self):
day_list = []
period = (self.end_date - self.start_date).days
for d in range(period + 1):
day = self.start_date + datetime.timedelta(days=d)
day_list.append(day)
return day_list
# 2 レポートリストの作成
def create_report_list(self):
report_list = []
for day in self.day_list:
url = "https://api.edinet-fsa.go.jp/api/v2/documents.json"
params = {"date": day, "type": 2, "Subscription-Key": edinet_api_key}
try:
res = requests.get(url, params=params)
res.raise_for_status()
json_data = res.json()
time.sleep(3) # APIのレート制限に従って調整
except requests.RequestException as e:
print(f"Request failed: {e}")
continue
for result in json_data.get("results", []):
if result["ordinanceCode"] == "010" and result["formCode"] == "030000":
report_list.append({
'会社名': result["filerName"],
'書類名': result["docDescription"],
'docID': result["docID"],
'証券コード': result["secCode"],
'EDINETコード': result["edinetCode"],
'決算期': result["periodEnd"],
'提出日': day
})
return report_list
# 3 データフレームの作成と保存
def create_docid_df(self, base_dir):
# ファイルパスを動的に設定
zip_path = "/content/Edinetcode.zip"
extract_dir = "/content/Edinetcode"
df_info_path = f"{extract_dir}/EdinetcodeDlInfo.csv"
output_path = f"{base_dir}/csv/edinet_df.csv"
#edinetcodelistを取得する
!wget https://disclosure2dl.edinet-fsa.go.jp/searchdocument/codelist/Edinetcode.zip
# zipファイルのダウンロードと展開
try:
with zipfile.ZipFile(zip_path) as zip_f:
zip_f.extractall("Edinetcode")
except zipfile.BadZipFile:
print("Failed to unzip file")
return None
df_info = pd.read_csv(df_info_path, encoding="cp932", skiprows=[0])
df_report = pd.DataFrame(self.create_report_list())
df_info = df_info[["EDINETコード", "提出者業種"]]
merged_df = pd.merge(df_report, df_info, how="inner", on="EDINETコード")
merged_df.to_csv(output_path,index=False)
return merged_df
クラス変数の指定
クラス変数を指定した上で、クラスメソッドを実行していきます。
ここでは2024年3月1日〜3月15日に提出された有価証券報告書を取得していきます。
# 書類提出期間の指定
start_date = datetime.date(2024, 3,1)
end_date = datetime.date(2024,3,15)
# データ保存のためのディレクトリの指定
base_dir = "/content/drive/MyDrive/directory/"クラスのインスタンス化
gd = GetDocid(start_date,end_date)クラスメソッドの実行〜docIDのデータフレーム取得
%%time
edinet_df = gd.create_docid_df(base_dir)データ取得結果
以下のようなデータフレームが取得できれば成功です

docid_listの作成
次の工程のために、docid_listを作成します。
docid_list = edinet_df["docID"].tolist()4. PDFファイルの一括取得
さきほどのdocIDに紐づけられる有価証券報告書のPDFファイルを一括取得していきます。
PDFファイルを一括取得すためのクラスの定義
paramsのtype2がPDFファイルを指します。
class GetPDFFromEdinet:
def __init__(self,docid_list):
self.docid_list = docid_list
def get_pdf_file(self):
for docid in tqdm(self.docid_list):
# 書類取得APIのエンドポイント
url = "https://api.edinet-fsa.go.jp/api/v2/documents/" + docid
print(url)
time.sleep(5)
#書類取得APIのパラメータ
params ={"type":2,"Subscription-Key":edinet_api_key}
res = requests.get(url,params=params, verify=False)
filename = docid + ".pdf"
#ファイルへの出力
print(res.status_code)
if res.status_code == 200:
with open(filename, 'wb') as f:
for chunk in res.iter_content(chunk_size=1024):
f.write(chunk)クラスのインスタンス化
docid_listを引数として渡します。
gpf = GetPDFFromEdinet(docid_list)クラスメソッドの実行
gpf.get_pdf_file()PDFファイルの取得
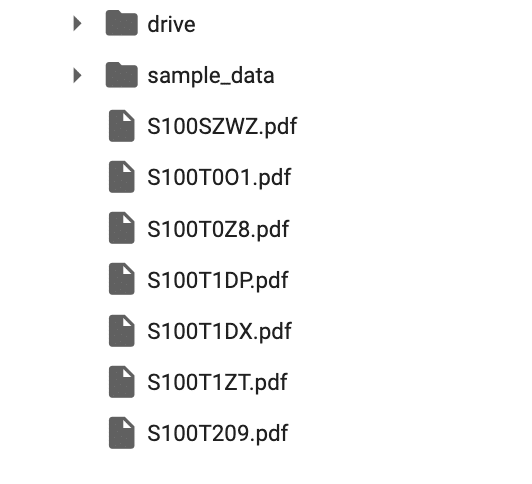
Googleコラボのcontentディレクトリ直下にPDFファイルが格納されます
【おまけ】有報PDFを閲覧できるURLを生成
有報のPDFは、ダウンロードしなくても、EDINET上で直接閲覧することができます。
このURLは、docIDで作られていますので、docIDさえわかればEDINETのURLを簡単に生成することができます。

いいなと思ったら応援しよう!
