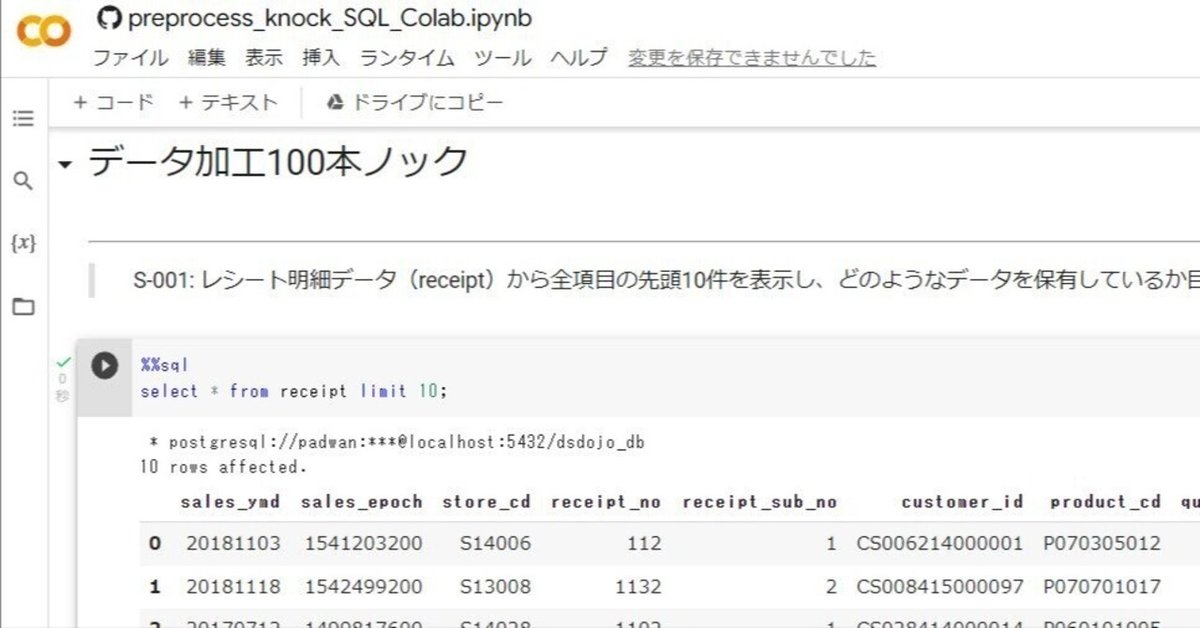
データサイエンス100本ノックをGoogle Colaboratoryで実践【SQL編・Python編】

はじめに
一般社団法人データサイエンティスト協会からデータサイエンス初学者の学習用として「 データサイエンス100本ノック(構造化データ加工編)」が公開されています。
これを手軽に実践できるように、Google Colaboratoryで実行可能なNotebookを作成しました。
オリジナル版ではDocker環境を構築する必要がありますが、Google Colaboratoryを利用することで、ブラウザのみで演習を行うことができます。
文字入力に支障がなければ、タブレットなどでも実行できます。
言語はSQL編、Python編を作成しています。R編は筆者がRを使用していないために作成していません。
使い方
【注意】
Google Colaboratoryを利用するためにはGoogleアカウントが必要です。
NoteBookはGitHub上に置いているため、GitHubへのアクセスが制限されている場合には利用できません。
1.初回実行時
1-1. 以下のリンクをクリックする
1-2. ファイル上部の「Open in Colab」をクリックする
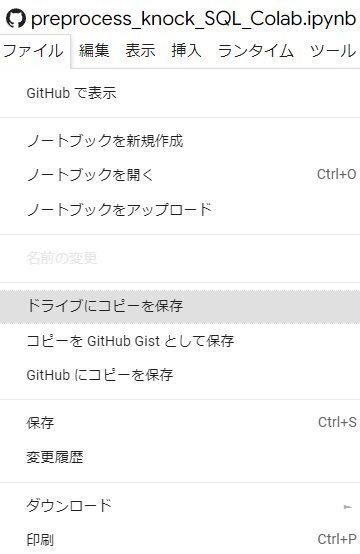
1-3. NoteBookを自身のGoogleアカウントのGoogleドライブに保存する
メニューの「ファイル」→「ドライブにコピーを保存」を選択すると、「マイドライブ」フォルダーの下の「Colab Notebooks」フォルダーにコピーされる。
コピーしなくても実行できますが、解答したNoteBookを保存できません。
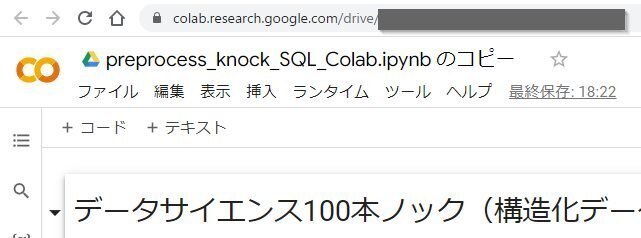
1-4. 新しいタブが開き、Googleドライブに保存されたNoteBookが表示される。
NoteBookの名前をクリックすると変更できます。
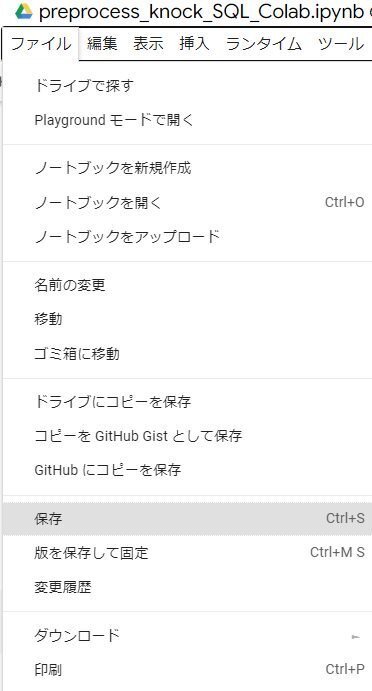
1-5.「#環境構築用セル」と書かれているセルを実行する
最初にセルを事項するときに以下の警告が表示されますが、「このまま実行」をクリックします。
また、環境構築のために1分程度の時間が必要です。

1-6. 演習を始める
1-7. 結果を保存する
メニューの「ファイル」→「保存」をクリックする。
1-8. 演習を終了する
ブラウザのタブを閉じればよい。(NoteBookは事前に保存しておくこと)
2.再開時
2-1. Googleドライブに保存したNoteBookを開く
NoteBookは「マイドライブ」フォルダーの下の「Colab Notebooks」フォルダーに保存されている。
ダブルクリックするとGoogle Colaboratoryで開く。
2-2. 「#環境構築用セル」と書かれているセルを実行する
再開時には環境が消えているために、再度実行する必要があります。
2-3. 演習を再開する
2-4. 演習を終了する
ブラウザのタブを閉じればよい。(NoteBookは事前に保存しておくこと)
出力結果の表示方法(インタラクティブ・テーブル)
インタラクティブ・テーブルの機能を使うことで、出力結果の並び替え、フィルタリング(条件で表示行を絞り込み)、ページネーション(ページに分割して表示)、ファイル出力(CSV)などができるようになります。
例えば、行数、列数が多い出力結果の確認などで利用できます。
出力の表示に以下のアイコンが表示されますので、それをクリックするとインタラクティブ・テーブルの表示に切り替わります。
インタラクティブ・テーブルはGoogle Colaboratoryの機能で、pandasのデータフレームに対する機能です。このNoteBookでは結果をpandasのデータフレームに出力しているために、利用できます。
インタラクティブ・テーブルの使い方については以下のページを参考にしてください。
https://atmarkit.itmedia.co.jp/ait/articles/2205/16/news029.html
参考情報
データベースのER図は以下の場所にあります。https://github.com/rootassist/100knocks-preprocess-inSQLandPython-withColab/raw/master/docker/doc/100knocks_ER.pdf
演習の解答編は以下の場所にあります。
Python解答編ipynb:
https://github.com/rootassist/100knocks-preprocess-inSQLandPython-withColab/blob/master/ans_knock_Python_Colab.ipynb
技術的な補足事項
Colaboratoryでの環境構築に関する技術的な補足です。
演習には必要ありませんので、不要ならば読み飛ばして構いません。
PostgreSQLのバージョンは13
SQL編で使用するPostgreSQLのバージョンはオリジナルと同じ13です。Google Colaboratoryでインストールできるのは10ですが、grantでpg_read_server_files、pg_write_server_filesを指定出来ないため、リポジトリに追加した上でインストールしています。
作業用フォルダは/tmp下
インポート用のcsvファイルは一旦「/tmp/data/100knock-preprocess」の下にコピーしてからインポートしています。
また問題番号94,95,96,99番では、ファイルを/tmp/dataに出力します。
SQL編では出力先についても問題文を修正しています。またPythonの場合はカレントディレクトリを/tmpとしています。
pandasのread_csvにおけるdtype指定
念のため指定していますが、データの内容から不要かもしれません。
型については、オリジナルに基づきデータベースのフィールドの型に合わせてあります。
なお、geocode.csvの1行目の項目名latitudeについては、初期バージョンにおいて項目名とその前のカンマの間にスペースがあったためにread_csvで失敗していましたが、issue#38でご対応いただいております。
オリジナル
一般社団法人データサイエンティスト協会スキル定義委員
データサイエンス100本ノック(構造化データ加工編)
2022.7.24現在
謝辞
すばらしい研修課題をご提供されておられる、一般社団法人データサイエンティスト協会スキル定義委員の皆さまに感謝いたします。