
sd webui train toolを改造!

目的
Stable Diffusionを用いてmanga109の画像データを学習し、漫画風の画像を生成できるようにしようと考えている。そのための追加学習の方式としてsd webui-train toolを使用しているが、画像の事前処理において画像を正方形に切り出す際に、画像の中心から正方形領域を切り出しているため、変な画像(身体の一部であったり、何の画像か区別のつかない画像)が抽出されてしまう問題があった。そこで今回はtrain toolのコードを書き換えて理想的な処理を施せるようにしたい。
仕様


現状では上記のように画像の中心が切り取られてしまうためキャラクタの全身像を残して学習することができないという問題がある。そこで下記の図のように、加工元の画像の長辺を一辺とする正方形の上に画像が乗っているようなものにする。

コード分析
元のコードを分析する。下記にtrain-toolのコードのうち画像のクロップに関わる部分を示す。
def center_crop(image: Image, w: int, h: int):
iw, ih = image.size
if ih / h < iw / w:
sw = w * ih / h
box = (iw - sw) / 2, 0, iw - (iw - sw) / 2, ih
else:
sh = h * iw / w
box = 0, (ih - sh) / 2, iw, ih - (ih - sh) / 2
return image.resize((w, h), Image.Resampling.LANCZOS, box)まず、center_cropについて、この関数はimage, w(おそらくwidth), h(おそらくhights)の3つを引数に取る関数で、それぞれImage, int, int型ということらしい。Image型とは一体?とりあえず画像を引数にするんだろう。PILをインポートしているので、どこかで画像形式、型を独自に定義しているのかもしれない。
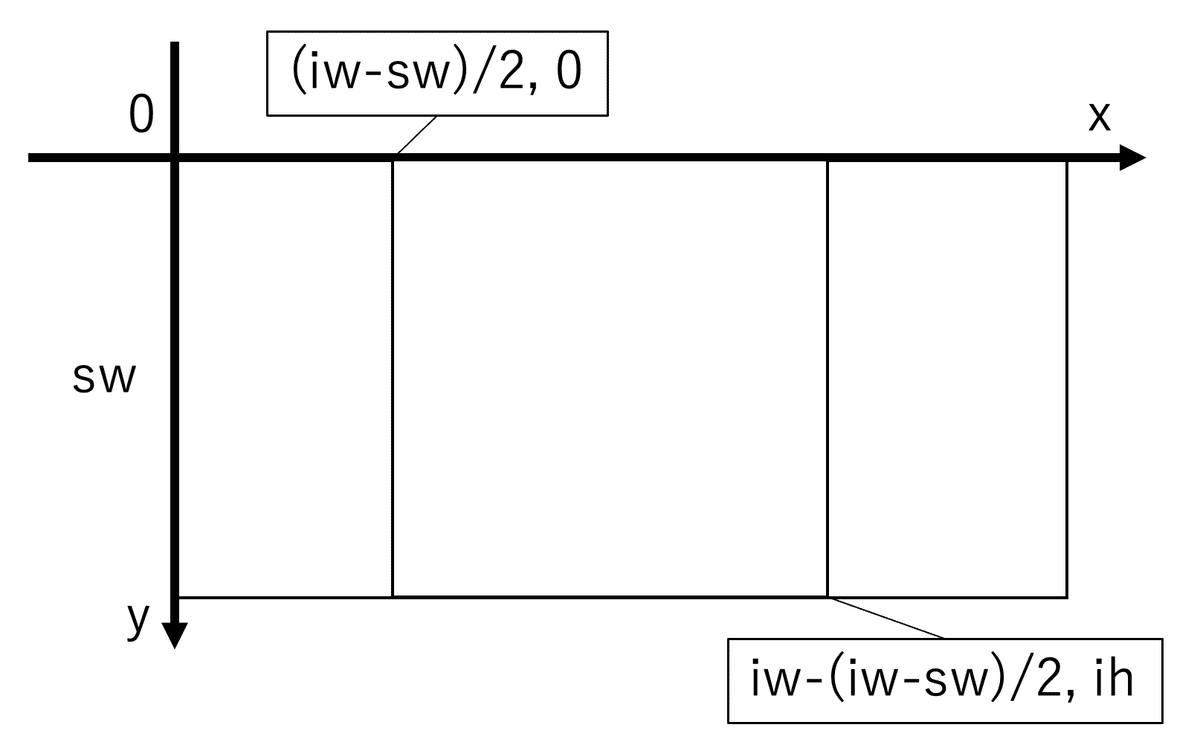
さておき、次はiw, ihに画像のサイズを取得している。次にih/hとiw/wを比較している。デフォルトではw = h = 512のはずなので、iwとihを比較しているのと同じ。すなわち縦長か横長かを調べている。
iw, すなわち横の方が長い場合、sw=ih(縦の長さ)となる。よって以下の画像のように、横長の画像内で最大の四角形を取ることができる。縦長の場合も同様。
最終的な画像サイズの調節はresizeメソッドを用いている。Imageクラスのresizeメソッドの構文は以下の通り
Image.resize(size, resample=None, box=None reducing_gap=None)size:リサイズ後の大きさ(幅、高さ)
resample:リサイズ時の保管方法。LANCZOSは一番良いらしいけども。
box 画像を拡大、縮小する領域を(左、上、右、下)の座標で指定
reducing_gapに関してはよくわからなかった。ともかく上記の3つの引数が重要になる。補完については画像の高解像度化についての記事で考えるのでひとまず置いておき、上記の「仕様」で述べたような処理をするにはどうしたらいいか検証していく。
実装
resizeメソッドにマイナスの値を入力することができれば上記の部分をちょっと書き換えれば理想的な操作をできそうである。
from PIL import Image
def crop(image: Image, w: int, h: int):
iw, ih = image.size
if ih / h < iw / w:
sw = w * ih / h
box = 0, -(iw - sw) / 2, iw, iw + (iw - sw) / 2
else:
sh = h * iw / w
box = -(ih - sh) / 2, 0 , iw + (ih - sh) / 2, ih
print(box)
return image.resize((w, h), Image.Resampling.LANCZOS, box)
image = Image.open('test.jpg')
result = crop(image, 512, 512)
result.save('result.jpg')上記のコードを実装したが、エラーが生じた。
ValueError: box offset can't be negativeboxの座標が負の値になるとエラーになるらしい。ガーン。
調べていくと、どうもpasteメソッドを使って行う方法があるらしい。それを参考にしつつ完成したコードは以下のようになった。
from PIL import Image
def expand2square(image:Image, w: int, h: int):
background_color = (255, 255, 255)
iw, ih = image.size
if iw == ih:
result = Image.new(image.mode, (iw, iw), background_color)
result.paste(image, (0, (iw - ih) // 2))
return result
elif iw > ih:
result = Image.new(image.mode, (iw, iw), background_color)
result.paste(image, (0, (iw - ih) // 2))
return result
else:
result = Image.new(image.mode, (ih, ih), background_color)
result.paste(image, ((ih - iw) // 2, 0))
return result
image = Image.open('test05.jpg')
result = expand2square(image, 512, 512)
result.save('whiteresult05.jpg')背景色はbackground_colorのRGBで指定する。(255, 255, 255)で白色に指定しておく。
Image.new(image.mode, (iw, ih), background_color)
新規画像の作成で正方形の白色画像を生成する。引数は3つ。image.modeでは入力された画像の形式(モノクロなど)を取得して入力、生成する正方形のサイズ、色を入力して生成する。
pasteは、生成した白い正方形の左上の座標を基準として、貼り付けたい画像の左上の座標を指定する。

懸念としては、元の原稿データの形式がモノクロであった場合、背景色のRGB指定でエラーが出ないのかということがある。
まとめ
PILモジュールを用いて期待する仕様通りの画像を生成する方法が明らかになった。次回はモノクロの画像の高解像度化についてまとめていきたい。