
AITuberKitでRealtime APIが使えるようになりました

こんにちは、ニケです。
皆さん、Realtime APIは使っていますでしょうか?
10月2日のOpenAI DevDayで発表されたので、もうすぐ1ヶ月が経とうとしていますね。早い。
というわけで今回はこのRealtime APIを、私が開発しているAIキャラとチャットができるOSS『AITuberKit』に組み込んだので、その使い方について説明していきたいと思います。
Realtime APIの特徴や惜しいところについても解説しているのでお楽しみに。
AITuberKitのRealtime API組み込みできたーーー
— ニケちゃん@AIキャラ開発 (@tegnike) October 6, 2024
割と現実的な速さになったかなあと思います
ちなみに声の違和感が拭えなかったため今回はアバターサンプルAさんにお越しいただきました pic.twitter.com/jJTmIhQtML
⚠ AITuberKit v2.6.0 時点での記事です。

Realtime APIとは
詳細についてはRealtime APIのリリース直後に解説した下記の記事を読んでみてください。
少しだけRealtime APIの何がすごいのかについて説明します。
従来のAIチャットボットでは、主に下記のような流れで処理が進んでいました。
ユーザーが音声で話しかける
音声を文字起こししてテキストにする
テキストをAIに渡してテキストで回答を得る
テキストを音声に変換して再生する
Realtime APIでは、音声での読み込みと音声での返答が可能です。
つまり、
ユーザーが音声で話しかける
音声をAIに渡して音声で回答を得る
このようにテキストの仲介がなくなるため、ユーザーの質問からAIの返答までの遅延を少なくすることが可能になります。
また、音声をそのままAIに渡すことにより、抑揚などのニュアンスを理解した回答を得ることもでき、その出力された回答自体にも感情表現を乗せることが可能です。
※ ちなみに音声だけでなく、Realtime APIは従来通りのテキストベースでやり取りすることも可能です。
AITuberKit とは
私が開発しているブラウザアプリのOSSです。
数コマンドで環境が構築でき、すぐにAIキャラとチャットすることができます。
日々開発を進めていまして、目についた機能を片っ端から取り込んでいます。
今回はRealtime APIが面白そうだったのでそれを実装してみた、という話です。
使い方
基本的な使い方は上記の記事を参考にしてください。
すでにAIキャラと会話できている前提で話を進めます。
⚠ 以下はOpenAIのAPIキーがある前提で話を進めるので、まだ取得していない方は用意しておいてください。クレジットが先払いであることもお忘れなく。
設定
右上の歯車アイコンから設定画面を開きます。

すると上記のような画面が表示されるので、AIサービスで『OpenAI』を選択してください。Azure OpenAI でも可能ですが、ここでは説明を省きます。
次に、その下の『OpenAI APIキー』にご自身で用意したAPIキーを設定します。
ここまでできたら準備完了です。
その下の『リアルタイムAPIモード』をONにして設定画面を閉じてください。
⚠ 設定画面を閉じたら左上に接続状況が表示されます。
「成功」と表示されていても、その下に「試みています」や「閉じられました」など、二重で通知が来ることがあります。
この場合接続がうまく行っていないので、APIキーが正しく設定されているかを確認してください。

会話する
それでは早速会話してみましょう。
Realtime APIを使用する場合は、テキスト入力はできず音声入力のみができる仕様になっています。
以下の2つの方法で会話を始めてください。
Alt (or option) キーを押している間、音声入力を受け付けします。話し終わったらキーを離すことでRealtime APIにリクエストを送信します。
マイクボタンを1度クリックします。クリックしたら再度クリックするまで音声入力を受け付けします。話し終わったら再度ボタンをクリックすることでRealtime APIにリクエストを送信します。
問題がなければ1秒足らずで回答が返ってくるはずです。

左上の設定ボタンの横にある「会話ログ」ボタンを押すと会話履歴を表示できます。
オプション
いくつかオプションがあるので、注意点とともに説明します。

送信タイプ
送信タイプでは、Realtime APIに送信するデータ形式をテキストか音声から選択できます。
Realtime APIの売りは最初にも説明した通り、Speech to Speech、つまり音声データリクエストから音声データレスポンスを生成することで応答する速度を早くするということですが、実のところ音声認識の精度があまり良くありません。
例えば、日本語で話しているのにもかかわらず別の言語で返してきたり、話したことと全然違った内容の回答をしてくることも少なくありません。
後述するシステムプロンプトを書き換えることである程度は制御できますが、それでもしっかりした口調でハキハキと喋ることを徹底しないと精度は期待できないでしょう。
そのため、送信タイプでは「テキスト」または「音声」のどちらで送るかを選択できるようになっています。
「音声」を選択した場合は音声データを送信しますが、「テキスト」ではブラウザで一度文字起こししたデータを送信します。
話しかけると下のチャット欄にほぼリアルタイムで喋った文字が表示されていると思いますが、このテキストがそのまま送られるということですね。
これはブラウザのWeb Speech APIという機能を利用して文字起こししています。

あらかじめ言語を指定しているので日本語から外れることはまずありません(設定画面で言語を英語にすると文字起こしも英語になります)。
基本的にはこちらの「テキスト」を選ぶほうが良いでしょう。
文字起こしする動作が入るため、若干遅いですが精度はこちらのほうが高いはずです。
Realtime API特有の多言語対応を試したい場合は「音声」を選択してみてください。
ボイスタイプ
ボイスタイプでは下記のモデルが選択できます。
OpenAI と Azure OpenAI で選択できるモデルが異なる点に注意してください。
OpenAI
‘alloy’, ‘coral’, ‘echo’, ‘verse’, ‘ballad’, ‘ash’, ‘shimmer’, and ‘sage’.
新旧計8種類のボイスを日本語で聴き比べしてみたのでご査収ください
— ニケちゃん@AIキャラ開発 (@tegnike) October 30, 2024
個人的にはsageちゃんが好みです https://t.co/YFrQxR20JD pic.twitter.com/OqC2eiVUC1
Azure OpenAI
‘amuch’, ‘dan’, ‘elan’, ‘marilyn’, ‘breeze’, ‘cove’, ‘ember’, ‘jupiter’, ‘alloy’, ‘echo’, and ‘shimmer’.
なぜかAssetが異なるAzureの新旧計11種類のボイスも比較しました
— ニケちゃん@AIキャラ開発 (@tegnike) October 30, 2024
男性ボイスが充実している上にクオリティ高いです pic.twitter.com/SGQk3ITF5U
なお、ボイスタイプを変更した場合は、その下のボタンの『リアルタイムAPI設定を更新』を押す必要があります(もしくは画面のリセット)。
これはRealtime APIの仕様で、1つのセッション(会話の単位)では1つのボイスタイプしか利用できないためです。
また、設定を更新すると会話歴もリセットされてしまうのでその点に注意してください。
キャラクター設定
次にキャラクター設定です。
AIにあらかじめどのような役割を与えるかという、いわゆるシステムプロンプトですね。
⚠ 『リアルタイムAPI設定を更新』と『キャラクター設定』の間に『オーディオモード』というのがありますが、これは今回使用しないので無視してください。
特に制限もないので自由に設定してもらって大丈夫ですが、
性別
言語
の指定はしておいたほうが自然に会話できると思います。
なお、ボイスタイプと同様、こちらを会話の途中で更新した場合は『リアルタイムAPI設定を更新』を押す必要があります。
関数実行
実はRealtime APIでは関数実行(Function Calling)が使用できます。
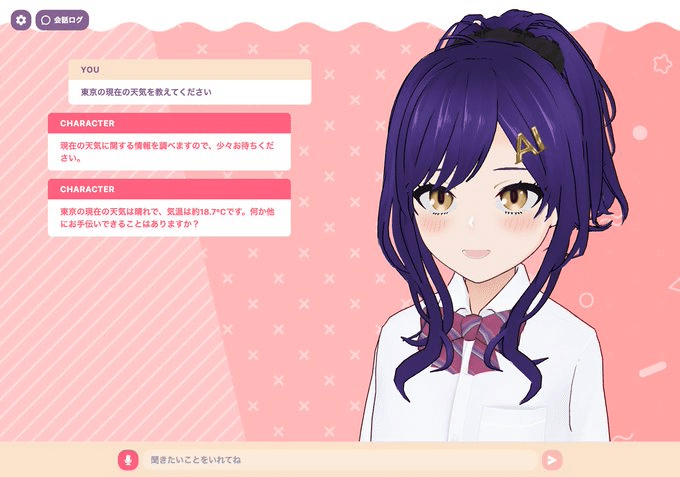
試しにサンプルツールとして私が設定した get_current_weather を利用してみましょう。
AIキャラに「〇〇の現在の天気を教えて」と聞いてみてください。
すると、現在の天気情報が返ってくるはずです。
⚠ 簡単に用意したサンプルなので「現在」の天気しか取得できない点に注意。
独自のツールも追加できるので手順を説明します。
1. ツールを定義する
下記のファイルにツールを定義してください。
いわゆるOpenAIのFunction Callingの定義方法と同じなので、慣れている方にとっては見慣れたものかと思います。
既存の get_current_weather を参考にしてください。
src/components/realtimeAPITools.json
[
{
"type": "function",
"name": "get_current_weather",
"description": "Retrieves the current weather for a given timezone, latitude, longitude coordinate pair. Specify a label for the location.",
"parameters": {
"type": "object",
"properties": {
"latitude": {
"type": "number",
"description": "Latitude"
},
"longitude": {
"type": "number",
"description": "Longitude"
},
"timezone": {
"type": "string",
"description": "Timezone"
},
"location": {
"type": "string",
"description": "Name of the location"
}
},
"required": ["timezone", "latitude", "longitude", "location"]
}
}
]2. 関数を作成する
次に、実際の関数を作成します。
こちらも get_current_weather を参考に作成してみてください。
src/components/realtimeAPITools.tsx
class RealtimeAPITools {
async get_current_weather(
latitude: number,
longitude: number,
timezone: string,
location: string
): Promise<string> {
console.log(
`Getting weather for ${location} (${latitude}, ${longitude}), timezone: ${timezone}`
)
// Open-Meteo APIにリクエストを送信
const url = `https://api.open-meteo.com/v1/forecast?latitude=${latitude}&longitude=${longitude}&hourly=temperature_2m,weathercode&timezone=${encodeURIComponent(timezone)}`
const response = await fetch(url)
const data = await response.json()
console.log(data)
// 最初の値を取得
const temperature = data.hourly.temperature_2m[0]
const weathercode = data.hourly.weathercode[0]
// 天気コードを天気状況に変換
const weatherStatus = this.getWeatherStatus(weathercode)
return `天気情報: ${location}の現在の気温は${temperature}°C、天気は${weatherStatus}です。`
}
// 天気コードを天気状況に変換するヘルパー関数
private getWeatherStatus(code: number): string {
// 天気コードに応じて適切な天気状況を返す
if (code === 0) return '快晴'
if ([1, 2, 3].includes(code)) return '晴れ'
if (code >= 51 && code <= 55) return '霧雨'
if (code >= 61 && code <= 65) return '雨'
if (code === 80) return 'にわか雨'
// その他の天気コードに対応
if (code === 45) return '霧'
if (code >= 71 && code <= 75) return '雪'
return '不明'
}
// Add other functions here
}
const realtimeAPITools = new RealtimeAPITools()
export default realtimeAPIToolsこの2つのファイルを更新したら、念の為サーバーを再起動(npm run dev)してください。
チャットの内容に合わせて関数が適切に実行されるか確認してみましょう。
TIPS: 会話の間を埋める
関数の定義によっては結果が返ってくるまでに時間がかかってしまうこともあるでしょう。
その場合、話しかけたのにAIが無言で待機し続ける、という状況が発生してしまいます。
これを解決するために、関数実行前に一言「少々お待ちください」と言ってもらえると良いかも知れません。
まだ完全に検証したわけではないですが、以下の文章をツール定義の description の最後に加えるだけで、そのような回答を返してくれるという事象を発見しました。
Please respond to the user before calling the tool.
同じように、設定の『キャラクター設定』の方に下記の文言を入れることでも言ってくれるという事象を確認しています。
ツールを使用する場合は、必要に応じてユーザを待たせる旨を伝えてください。
100%確実に言ってくれるわけではないようですが、このように色々試してみるのは良いかも知れません。
注意事項
高額です
Realtime APIは他のモデルと比較してもかなり高額です。
https://openai.com/api/pricing
セッション毎に会話が自動的に保存されるので、同じ画面のまま話し続けると雪だるま式にトークンが増えてどんどん1ターン当たりの費用が高くなってしまいます。
最近プロンプトキャッシュの機能が追加されて少しはマシになったようですが、それでもまだ安いとは言えないでしょう。
利用するたびにブラウザをリロードすることをオススメします。
⚠ いちおう会話の1つ1つのやり取りを削除する方法もあるようですが、AITuberKitのシステムでは未実装です。ご了承ください。
オプション変更時のリセットを忘れずに
上述しましたが、いくつかのオプションは『リアルタイムAPI設定を更新』を実行しないと反映されません。
変更したのに変わってないっぽい?と思ったら、このボタンを押すか、画面をリロードしてください。
リセットが必要なオプション
OpenAI APIキー
(Azureの場合)Azure Endpoint
ボイスタイプ
キャラクター設定(システムプロンプト)
セッション毎に会話歴がリセットされます
Realtime APIでは、セッション毎に会話歴が保存されます。
つまり、セッションを帰ると会話歴が削除されるということです。
これは上記の『リアルタイムAPI設定を更新』も対象で、今まで話した会話がすべてリセットされてしまいます。
公式のRealtime APIの説明を読むと、新しいセッションに過去の会話歴を持たせるには、その会話歴をテキストとして改めて新しいセッションに一つずつ送信して保存させていくしかないようです。
https://platform.openai.com/docs/api-reference/realtime-server-events/response-audio-delta
現在のAITuberKitのシステムではそのような機能は実装していないので、注意してください。
Realtime APIの課題
Speech to SpeechですぐにAI対話ボットを作れるRealtime APIですが、現状課題も多いです。
私がいろいろ試した上で感じた惜しい点を共有したいと思います。
音声認識精度が低い
上でも何度か説明しましたが、これが一番問題として大きいです。
日本語の場合、しっかり発音しないと誤認することが多い印象です。
あらかじめ使う人が決まっていて、はっきり喋ることを周知できていればよいですが、不特定多数の人が使うような用途では現状難しいでしょう。
テキストと音声が異なる場合がある
Realtime APIでは、テキストデータと音声データがストリームで返却させることが可能です。
画面に文字を表示したいなどに便利ですが、たまにこれらのデータに不整合があるときがあります。
例えば、一部の文章の表現が異なる、一文丸々読み飛す、などの現象を確認しています。
音声データが返ってくることの欠点
これはそもそもの話になってしまいますが、音声データが返ってくること自体に拡張性がなくやや使いづらいです。
私はAIキャラに喋らせる時に、分節毎に感情パラメータを付与させるという方法をよく取ります。例えば下記のような感じです。
[neutral]こんにちは。[happy]元気だった?
[happy]この服、可愛いでしょ?
[happy]最近、このショップの服にはまってるんだ!
通常の場合はこの感情パラメータの部分は発音前に事前処理して分離させ、その後ろのテキストだけをTTSサービスに渡して発音させる、という実装をします。
Realtime APIでは、音声をそのまま返してしまうので、neutral の部分も発音してしまう問題が発生します。
他にも「この部分は読ませたくないんだけどな」という要件に応えることも難しいです。
まだβ版ということもあり、正直なところ実用にはもう一歩、という感想です。
今後のアップデートに期待します。
追記!
逆瀬川さんにご指摘いただいたのですが、確かに顔文字で指定したらRealtime APIでも解決できそうです。
新たな知見に感謝🙌
ちなみに感情はタグは難しいですが、顔文字をつけるように指示するとテキストでだけ扱える感情情報が手に入る (発話しない) ので簡易的な解決になったりします👍
— 逆瀬川 (@gyakuse) November 6, 2024
宣伝
AITuberKitについてもっと知りたい!もっとこんな機能が欲しい!という方がいたらぜひDiscordサーバーに参加してください!
日々開発進捗もつぶやいていたりするのでX(Twitter)もフォローしてもらえると嬉しいです🙇♀
いいなと思ったら応援しよう!
