
AIに知ってるゲームの操作と実況をすべて任せてみる

⚠ この記事は展示会後の24/11/17(日)に加筆修正してます。
こんにちは、ニケです。
皆さん、24/11/16(土)に開かれる『生成AIなんでも展示会』には参加されましたでしょうか?
生成AIなんでも展示会は、生成AI系個人開発者のデモ会です(個人である点がポイント)。
生成AI系の開発者が集まり、制作物・実験結果などをブースで展示することで、技術を通じて交流を深めることが目的とのこと。
2024年の4月に第一回が開催されたときに私も参加したのですが、かなりの人数の来訪者がいて、どのブースも盛り上がっていたのを覚えています。
ちなみに今回のVol.2では、私もASAさんと共同で展示会に出展していました。
ASAさん
ニケちゃんさんといっしょに参戦します。
— ASA(あさ) (@haruka_AITuber) October 12, 2024
よろしくお願いします。 https://t.co/Ow9MByBMx4
当日の様子
こういう展示をしていました
— ニケちゃん@AIキャラ開発 (@tegnike) November 16, 2024
ほぼずっと喋ってたので割と人は来てくれてたと思います
見ていただいた皆々様方ありがとうございました!!🙌#生成AIなんでも展示会 pic.twitter.com/hsgJAs0coc
というわけで今回は我々が展示した『AI自動ゲームプレイ&実況』について解説させていただこうと思います。

⚠ 今回のプロダクトについてだけ読みたい場合は、『今回展示するプロダクト』まで読み飛ばしてもらっても大丈夫です。
作成経緯
実は今回展示するのは去年作成していたプロダクトの最新版です。
2023年当時、マインクラフトをAIで操作するというのが少し話題になっていました。
これに興味を引かれ、マインクラフトでも他のゲームでも、自動化してAIがそれをプレイして配信したら面白いのではないか?と考え始めます。
たまたま同じような話題を呟いていたASAさんと意気投合し、AI x ゲームについての情報共有Discordサーバーを立ちあげたのが本プロダクト作成のきっかけです。
ちなみに同サーバーにはすでぃーさん(https://x.com/sudy_super)も参加しており、今回のプロダクトを含め様々な助言をいただています。
選択するゲームの条件
先ほども紹介した通り、当時はマインクラフトをAIで操作する、というのが流行っていました。
Voyager や Minedojo というライブラリが有名です。
最初はとにかくAIにゲームをやらせてみたのを配信したいと考えていたので、早速このVoyagerを試してみました。
とはいえいざ試してみると思ったように動かないし、待ち時間もかなり多いし、API費用は高いし…(当時の値段で$30/時間くらい)、などの理由ですぐに計画が頓挫したのを覚えています。
ということで別のゲームを試そうと考えたのですが、Voyagerのように特定のゲームに特化したライブラリはそうそう見つかりません。
いっそのこと機械学習で1からやってみるのも良いのでは?とも考えましたが、所詮素人の我々にはハードルが高く、別の方法を模索することになります。
そこで選択したのがSwtichの『ポケモンスタジアム2』です。
ゲーム選択の条件ですが、テキストベース かつ ターン制、そして誰もが知っているゲームであることが必須であると考えていました。
⚠1 ちなみにSwitchのようなコンソールのゲーム画面をPCに映すのは、キャプチャーボードというアイテムを使えば可能です。
⚠2 また、SwitchをPCから操作する技術はこちらを参考にしています。詳しくは触れないので気になる方はこちらを参照してください。
条件1: テキストベース
AIにゲームをさせるとなると、PC経由でAPIやコマンドを介して操作するというが最初思い浮かぶと思います。
実際Voyagerなどはマインクラフトをコマンドで操作しています。
とはいえこの方法だとゲームのAPIやコマンドに精通しなければいけず、学習コストがかかります。
システムが完成したとしてもできるのは1つのゲームだけです。
せっかくやるなら色々なゲームに対応できる方が良いと考えた結果、OCR技術を採用することにしました。
OCR(Optical Character Recognition)とは、紙や画像に印刷された文字や手書き文字を機械で読み取り、テキストデータに変換する技術です。
つまり、ゲーム画面をスクショして、それを文字起こしし、AIに状況を把握させてから操作させればどんなゲームでも対応できるのでは?という考えです。
各ゲームの画面情報(その画面でどのようなボタンを押せばよいかなど)は必要ですが、これならいろいろなゲームに応用できそうです。
OCRに着目したのは、当時はまだマルチモーダルモデル(AIに画像を渡せるモデル)がなかったというのも理由の一つです。
条件2: ターン制
ゲームには様々なジャンルがありますが、アクションゲームなどはAIにやらせるにはハードルが高いです。
どうしてもAIのレスポンスに時間がかかってしまい、即時的に意思決定が反映されないのでコンマ何秒が求められるゲームには向いていません。
こちらが選択するまで次に話が進まない、ステップバイステップで展開していくようなゲームがベストだと言えるでしょう。
これならスクリーンショットも容易です。
条件3: 誰でも知ってる
これに関しては特にゲームをさせる上で必須の条件ではありません。
とはいえ、今後配信などで公開していくということも踏まえると、できるだけ有名なゲームであったほうが視聴者も理解しやすく、拡散もされやすいため、重要な理由の一つだと思います。
このプロダクトでそこそこ伸びたポストもあるので、結果的にポケモンスタジアム2を選んだのは間違いではなかったと思っています。
なお、今回のプロダクトではポケモンスタジアム2を最初のサンプルとして選択しましたが、これらの条件にあってさえいればどのようなゲームもプレイができるようなシステムになるように焦点を当てて制作しています。
過去のプロダクトとその課題
最初にプロダクトを公開したのが2023年8月です。
処理機構はおおよそ下記のようになっています。

キャプチャーボードを使用してゲーム画面をPCに表示
OBS APIを使用してゲーム画面をスクリーンショット
スクショからOCR(GCP Vsion API)を利用してテキスト抽出
テキストと過去ログなどをAIに渡して操作指示を受け取る
受け取った指示を元にマイコンチップを使用してゲームに操作指示
基本的にはこの手順がベースで、今回展示する最新版も大まかな流れは同じです。
ちなみにOBSを使用しているのは、拡張機能を利用すると比較的スクリーンショットの自動化が簡単に行えるためで、絶対にこれが必要というわけではありません。
この時点での課題はいくつかあります。
課題1: 遅い
とにかく1ターンの処理が遅いです。
まずOCRがそこまで高速ではありません。
文字を起こす処理だけで10秒以上かかっていました。
また、当時利用していたAIモデルはOpenAIのGPT-4ですが、こちらも速いとは言えません。
結局、画面のキャプチャから操作指示まで、合計で1ターン30秒〜1分くらいかかっていました。
課題2: 準備が多い
次に準備が多すぎる点です。
OCRを使用した処理では画面にどのような文字があるかを読み取る処理とは別に、実はどの画面かを判定させる処理も実行させていました。
例えば、戦闘準備画面では「たたかう」「ポケモン」「にげる」の選択肢がありますが、この選択肢をAIに与えるためにはこの画面が戦闘準備画面だということを伝える必要があります。

ではこれをどうやっているかと言うと、先頭準備画面にはこの文字がこの位置に在って、ボタンはこの位置、そしてそのボタンを押したら〇〇画面に遷移する、みたいな情報をあらかじめDBに保存しておく必要があります。考えられる画面全てです。
OCRでは認識したテキストが画面のどの座標に存在していたかを正確に返してくれるので、そのOCRが認識した情報と上記のあらかじめ用意していた画面情報DBと過去のログを突き合わせて現在の画面を特定する、という手法を取っていました。
なぜこうしていたかと言うと、速度と精度を向上させるためです。
先程の課題でも説明しましたが、当時のgpt-4は遅い上に費用も高く、実現性を考えるならあまり積極的に利用したいツールではありませんでした。
その上gpt-4に完全に任せるよりもこのように画面を特定させたほうが精度が出たので、当時はこのような一見面倒くさい手法を取らざるを得ませんでした。
課題3: 精度が悪い
これでも精度は完璧ではありません。
OCRの認識も完璧ではないので、OCRによる画面選択がミスるとAIはもちろん適切なボタンを選べず、次の画面に進めないという不具合が発生します。
また、画面はあっているのにgpt-4が適切な結果を返してくれずエラーでやり直し、という問題も頻発していました。
もちろんシステムの欠点も少なくなかったですが、それ以前に自分たちでは解決できない問題も多かったです。
というわけで、この時点でのプロダクトは1ターン1ターンちゃんと適切な操作をしてくれるか、緊張しながら見ていたのを覚えています。
その後システムを改良し、少し安定性が増したプロダクトを2023年11月に『AI x Game Character Meetup』という展示会に紹介させていただきました。
処理機構自体はそこまで変わっていませんが、AIが判断した結果をあたかも自分で考えたかのように発言させる機構を取り入れ、AIが実況するという処理も加えています。
処理の安定性は向上したものの、1ターンの時間(約30秒〜1分)は先程説明した仕様上、ツールの速度に依存するのであまり変わっていません。
システムの作成が一段落し、開発者がそれぞれ別の案件で忙しくなってしまったということもあり、ここで開発は一旦ストップしていました。
今回展示するプロダクト
前回の展示会から1年が経過しました。
AIの性能も以前とは比べものにならないほど進化しています。特に画像を認識できるマルチモーダルモデルの登場は大きいです。
ということで今回1年ぶりにASAさんと連絡を取り、このシステムをリライトすることに決定しました。
今回のシステムは処理を2つに分離し、プレイ部分をASAさん、実況部分を私が担当しています。
ゲームプレイシステム
去年実装した処理の改造版です。

キャプチャーボードを使用してゲーム画面をPCに表示
OBS APIを使用してゲーム画面をスクリーンショット
スクショとゲーム情報をマルチモーダルAIで処理して状況の分析
分析結果とログから次の操作を決定し、ログとしてDBに保存
マイコンチップを使用して決定した操作をゲームに指示
大きな変更点はOCRを廃止し、マルチモーダルモデルを搭載したことです。
これにより画面の特定が用意になり、以前ほどの事前準備は不要になりました。
モデルもgpt-4からgpt-4oへと変更し、安定性が増しています。
ちなみに2024年11月現在ではOpenAIの他にも、AnthropicのClaudeやGoogleのGeiminiなど、様々なAIサービスが登場していますが、今回検証した結果ではgpt-4oが速度・精度共に一番良かったです。
ゲーム実況システム
去年の実況システムは、AIが判断した意思決定をAIで発話用に書き直して発言させているだけでした。
特に大きな工夫はなく、一方向にAIキャラに発話させているだけです。
今回は一方通行でなく、実況システムからもプレイシステムに影響を与えられるようにしています。

実況側の登場システムは主に2つあります。
実況する画面を映すシステム(紫部分)、プレイシステムと連携してセリフ生成するシステム(グレー部分)です。
これらをWebSocketで結合しています。
実況の基本的な処理は下記です。
先ほどのプレイシステムが保存したログをポーリングで一定間隔で取得する
最新のログがあった場合に、状況にあったセリフをAIで生成する
セリフをWebSocketで実況する画面を映すシステムに送信する
受け取ったセリフをStyle-Bert-VITS2で音声合成する
受け取ったセリフを画面に表示し、合成した音声を流す
これであたかもAIが実況しているかのようなシステムの完成です。
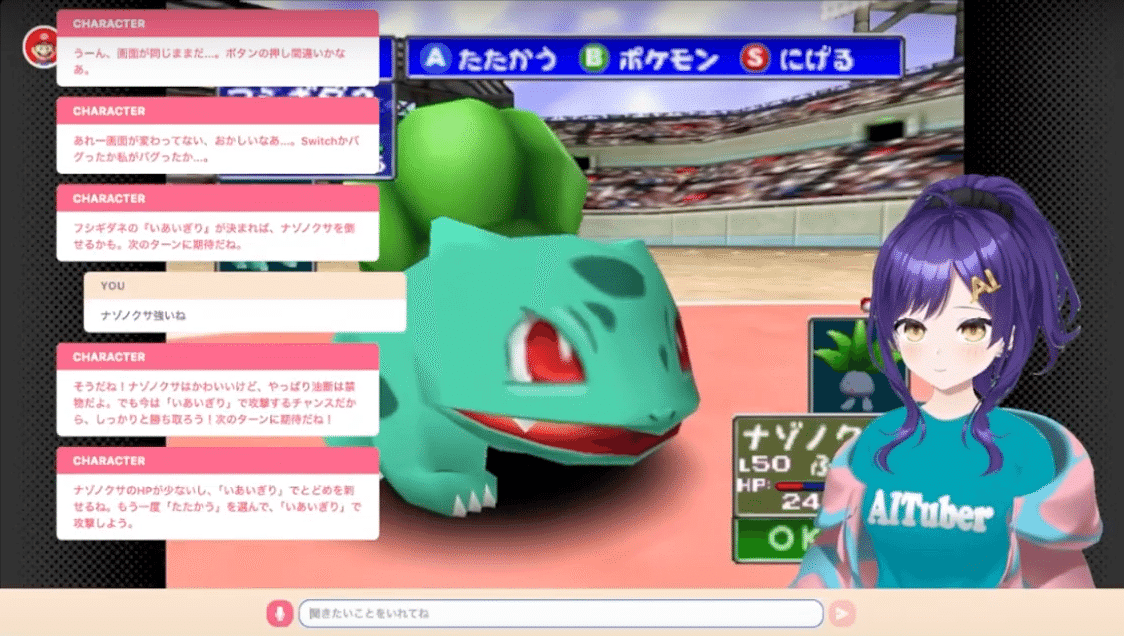
AIキャラを表示するシステムには私が開発しているOSSのAITuberKitを使用しています。
興味がある方はこちらもぜひ見てください。
今回はさらにチャット機能も搭載しています。
チャット機能で話した内容はプレイシステムにも反映されます。
視聴者がAIキャラに向かって発言する
文字起こしされたテキストがセリフ生成するシステムに送信される
ログと合わせて適切なセリフを生成する
視聴者の発言がゲームに対するアドバイスだと判定された場合に、プレイシステムに実況データとして保存される
生成されたセリフを実況する画面を映すシステムに送り返し、発話させる
この4番目の処理ですが、具体的に例えば視聴者が「ポケモンはあまり交代しないほうが良いよ」などと発言すると、そのデータがDBに保存され、プレイ側でそのアドバイスの内容を汲み取ってゲームの判断を下すようになります。
前プロダクトと比べてどうなったか
では、今回のプロダクトは前回の課題を克服できたのでしょうか?
結論ですが、やや改善はできたものの思ったよりは…といったところです。
まず一番ネックだった『遅い』問題について。
正直言うと速度はほとんど上がっていません。このシステムでも1ターンおよそ30秒かかります。
最も時間がかかっているのはマルチモーダルの部分で、およそ20秒弱かかっています。
この原因は渡すトークン数が膨大なことです。前回のシステムではOCR後に画面を特定する処理をしてからAIに画面指示を判断してもらっていたのですが、今回のプロダクトではスクショ画面と共にすべての画面情報をテキストで送っています。
そのため、AIの処理にかなり時間がかかってしまっています。
渡す情報を減らしたり、モデルも色々変えて検討してはみたのですが、そうすると今度は画面の判定精度が落ちるなど別の問題が発生していました。
⚠ 今回は実況システムも適切に組み込まれているので、このターン毎の待ち時間に適当なことを喋らせて間をつなぐ、ということも可能です。
今回の展示会では、待ち時間には視聴者とチャットさせることを優先させたかったのでそのような機能は実装していません。
今後配信するとなったときに、ここらへんの機能は充実させたいと思っています。
次に『準備が多い』問題について。
こちらに関しては、大分軽減されました。
特にマルチモーダルを使用することで画面の特定が容易になったため、画面ごとに渡す情報が少なくなったのは大きいです。
とはいえ最低限の情報はどうしても必要なので全く知らないゲームを一からプレイできる、というわけではありません。
最後に『精度』の問題について。
こちらに関してはおよそ上手くいっており、前回のプロダクトのように途中でバグって止まる、ということはほぼなくなりました。
それでもまだ、画面の認識をミスってループに入り、次に進まなくなってしまう不具合などは発生するため、完全に安定しているシステムとは依然言えないでしょう。
また、上述のようにモデル依存なところもあり、安価で高速なモデルを使用すると一気に破綻するという脆弱性も残っています。
現在の仕様ではおよそ1時間に$5~10かかるため、継続性を考慮するならできるだけ安価なモデルに置換しても動くシステムを構築したいと思っています。
終わりに
去年11月に展示会終了後、お互い忙しくてこのシステムを放置していたのですが、今回改めて展示会出展という名目で再びASAさんと共同で開発できる機会ができて良かったです。
当時からこのシステムには夢があると思っていたので、今回はここで開発を止めず、ぜひ今後も継続して改良できていいけたらと思っています。
処理の高速化や別のゲームへの簡単な切り替えなどが実現できたら、YoutubeでAITuberとして発信していくのも良いかも知れません。
今後の開発についてはTwitterで報告していく可能性があるので、ぜひフォローしていただけると嬉しいです。
ニケ: https://x.com/tegnike
ASA:https://x.com/haruka_AITuber
いいなと思ったら応援しよう!
