
爆速なStyle-Bert-VITS2サーバーを立ててAIキャラとチャットする

こんにちは、ニケです。
皆さん、Style-Bert-VITS2は使っていますでしょうか?
Style-Bert-VITS2と言えば、高品質で生成が早い合成音声技術(TTS: Text to Speech)として有名ですね。
かくいう私も自作モデルを用意してAIキャラとお話するのに使用していたりします。
とにかく声が自然で可愛い。
うおおおおおおお!!
— ニケちゃん@AIキャラ開発 (@tegnike) November 6, 2024
爆速(gemini-1.5-flash)x 爆速(SBV2 on GPUサーバー)の最強キャラ対話環境完成っだああああ!!! https://t.co/F67HhQ29v9 pic.twitter.com/kWtldMsS8K
Style-Bert-VITS2を使用するにはローカルで環境を構築するか、サーバーにデプロイする方法があります。
取り敢えず試してみたいという方はローカルで立ち上げてみましょう。
上記のGithubリポジトリのREADMEを読み進めていけば難しくないと思います。
作者のlitaginさんの記事を参考にするのもよいでしょう。
ちなみにStyle-Bert-VITS2はWindowsでもMacでも利用可能ですが、MacではCPU推論しかできず、若干遅さを感じます。
私のメインPCはMacですが、なんとかStyle-Bert-VITS2の速度を向上させようと色々試してたら、想像よりも高速なレスポンスを取得する方法が見つかりました。
というわけで今回はその方法についてここで共有したいと思います。
⚠ 本記事ではモデルの作成に関しては触れません。

本記事について
私が今から紹介する方法は下記のにょすさんの記事をかなり参考にさせていただいています。
こちらの記事ほど詳細に解説はしないので気になる方はぜひ読んでみてください。
上記の記事と異なる点は、サーバレスアーキテクチャを採用せずにGPUサーバーとしてレンタルしていることです。
サーバーレスを使用しない理由ですが、私が試した限りでは満足できるほど十分な速度が得られなかったためです。
起動直後のみ遅いと思っていたのですが、それ以降も思ったより早くなく(1秒回答は稀、~5秒くらいかかることが多い)、今回の手法を試してみたという経緯があります。
なお、サーバーレスでないため時間単位の課金が発生する点に注意してください。
利用するサービスの準備
今回の方法ではRunPodというレンタルサーバーサービスを利用します。
サインアップしたあと、RunPodは前払い制になっているのでクレジットを購入しておきましょう。
とりあえず試すだけなら$10も必要ないと思います。
また、今回はサーバーをレンタルするということもあり、切り忘れたらクレジットがなくなるまで利用料がかかるので、保険という意味でも最初は少額だけ入れておくのが良いでしょう。
また、DokcerHubを利用してDockerイメージをプルするので、そちらの登録も済ませておいてください。
後ほどこのとき登録したユーザ名を使用します。
音声合成までの手順
事前準備
まず、以下のGithubリポジトリをクローンしてください。
次のコマンドを実行しましょう。
必要に応じてPythonの実行環境は変更してください。
最後のコマンドでは必要なモデルとデフォルトTTSモデルをダウンロードしています。
git clone https://github.com/tegnike/Style-Bert-VITS2-API.git
cd Style-Bert-VITS2
python initialize.pyここまではStyle-Bert-VITS2のREADMEにも載っている初期化の手順です。
ローカルでサーバーを立ち上げる場合は、次にFastAPIサーバーを立てる必要があります。
この記事ではこちらに関しては説明しないので、ローカルで試してみたい方はREADMEを参考にやってみるのも良いでしょう。
今回の手法ではこのFastAPIサーバーをRunPodのGPUサーバーに立てます。
次に ./deploy.sh を準備します。
とは言っても特に難しくはありません。
これはDockerイメージをビルドして、DockerHubにプッシュするシェルスクリプトです。
すでにリポジトリにあるので開きます。
#!/bin/bash
USER="xxxx"
APP_NAME="runpod-style-bert-vits2-api"
VERSION=1.0.0
# VERSIONを目視で確認するのでy/Nで確認
echo "バージョンは ${VERSION} でよろしいですか?"
read -p "y/N: " yn
case "$yn" in [yY]*) ;; *) echo "中止します" ; exit ;; esac
# buildコマンド
sudo DOCKER_BUILDKIT=1 docker build --progress=plain . -f Dockerfile.runpod -t $USER/$APP_NAME:$VERSION
# pushコマンド
sudo docker push $USER/$APP_NAME:$VERSION
変更箇所は2点です。
2行目のUSERの部分に先ほど登録したDockerHubの名称に変更してください。
4行目のバージョンを適宜変更してください。最初は 1.0.0 のままで良いですが、次回以降同じ番号を使用すると上書きされてしまうので、念の為プッシュするたびに更新させていくと良いでしょう。
Dockerイメージのビルド&デプロイ
準備ができたら早速デプロイしましょう。
./deploy.shこのコマンドを実行することでDockerイメージがビルドされ、そのイメージがDockerHubにプッシュされます。
通信環境にもよりますが、数分〜10分前後くらいで完了すると思います。
DockerHub のプロフィール画面にデプロイしたイメージがあることを確認します。
なお、後ほどDockerHubのCredential情報を登録してから利用するため、このイメージをPrivateに設定することも可能です。イメージの設定画面から変更可能です。
RunPodでテンプレートを作成する
RunPodにログインします。
まずはサーバーをデプロイするためのテンプレートを作成しましょう。
作成しておくと、これ以降サーバーをデプロイする時にこのテンプレートを参照すれば良いだけになるのでかなり楽です。
左のサイドバーから Templates を選択し、New Template をクリックします。
下記のように設定してください。

Template Name: 識別子です。後ほど使用するのでわかりやすい名前にしてください。
Container Image: 先ほどプッシュしたイメージを選択します。おそらく『DockerHub名/runpod-style-bert-vits2-api:1.0.0』のようになるはずです。
Container Registry Credentials: DockerHub
Container Disk: 10GB
Volume Mount Path: /workspace
Export HTTP Ports: 5000
Save Template を押して保存しましょう。
RunPodでサーバーをデプロイする
まずはDockerHubと連携するための設定をします。
左のSettingsから、Container Registry Authを開きましょう。

Add Credentials ボタンをクリックし、必要な情報を記入します。

Credential Name: 識別子なので適当な名称で大丈夫です
Username: DockerHubのユーザ名
Password: DockerHubのパスワード
次に、左のサイドバーから Pods を選択し、Deploy ボタンをクリックします。
様々なモデルが表示されますが、私が検証した限りでは最安値の『RTX 2000 Ada』で十分高速でした。
特に要望がなければこちらを選択すれば間違いないと思います。
ちなみに費用は $0.28/時間、一ヶ月常時稼働で $180 です。
個人用途ならそもそも常時稼働させることは無いでしょうし、サービスとして使うなら高額というほどではないと思います。

下にスクロールし、使用するテンプレートと使用する価格帯を選択します。
テンプレートは先程登録したものを選択しましょう。
価格ですが、とりあえず今動かすだけなら『On-Demand』を選択すればよいです。

では、最後にその下にある Deploy ボタンを押してデプロイを始めてください。
改めてPodsの画面を開くとDockerHubからイメージをダウンロードしている様子が見れます。数分かかるのでしばらく待ちましょう。
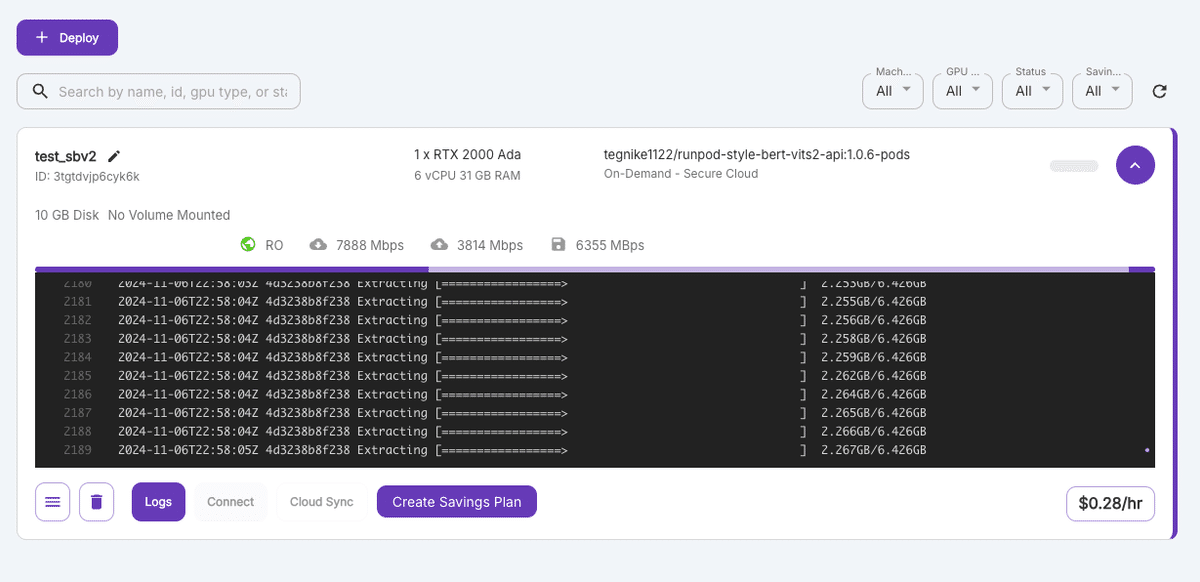
完了したら下記のような画面になります。

Style-Bert-VITS2を試す
それでは早速、Style-Bert-VITS2による音声合成を試してみましょう。
左下にある Connect ボタンを押すと下記の画面が開きます。

Connect to HTTP Service [Port 5000] をクリックするとブラウザが表示されると思います。
この画面が表示されたら成功です。
ちょっと紛らわしいですがこれでサーバーはちゃんと立ち上がっています。

ブラウザのURLを見ると下記のようになっていると思うので、
https://xxxxxxxxxxxx-5000.proxy.runpod.net/
最後に docs を付け加えて再度開いてください。
https://xxxxxxxxxxxx-5000.proxy.runpod.net/docs
Style-Bert-VITS2 のドキュメントページが表示されました。
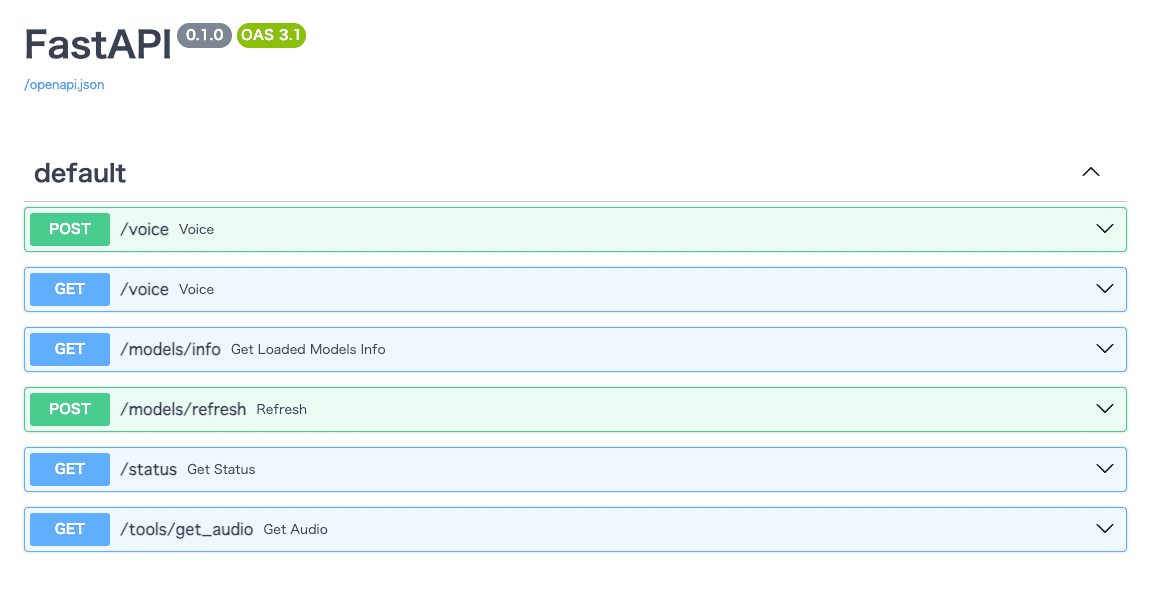
少し試してみます。
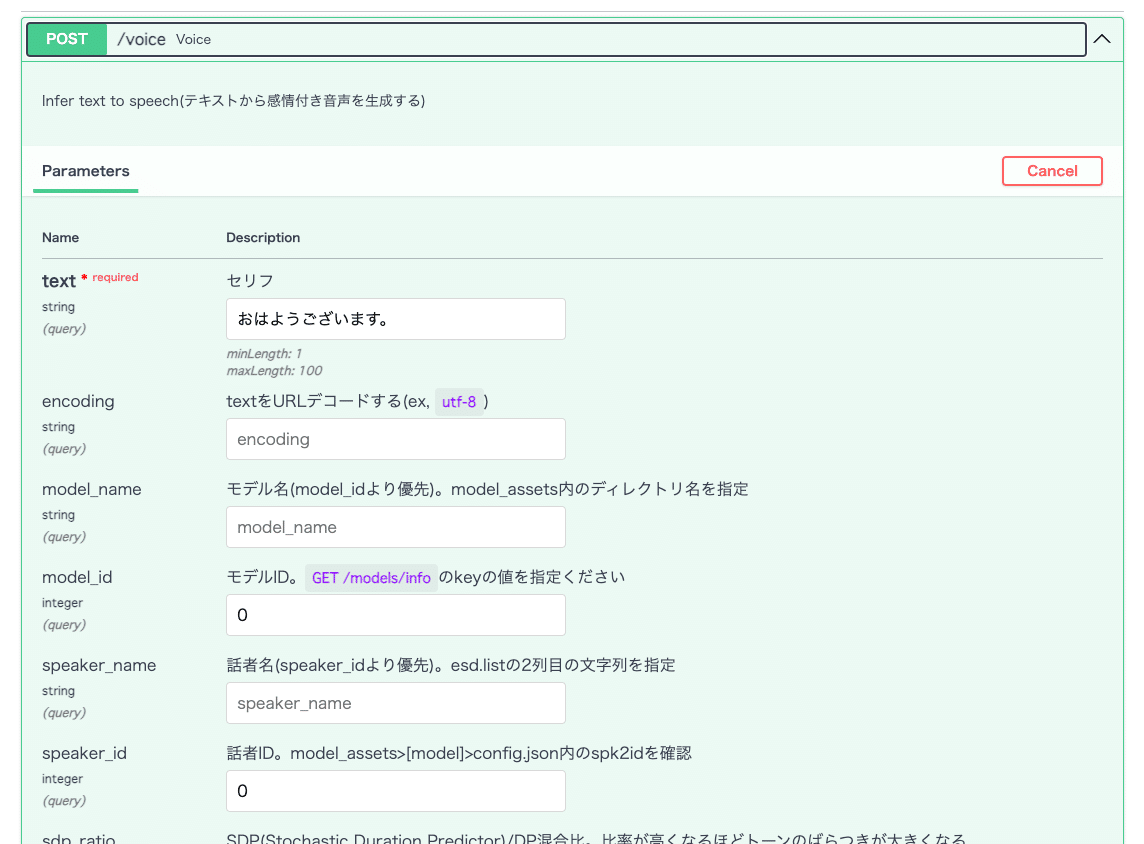
一番上の POST /voice を開き、右側の Try it out を押してから text に適当な文字を入れます。
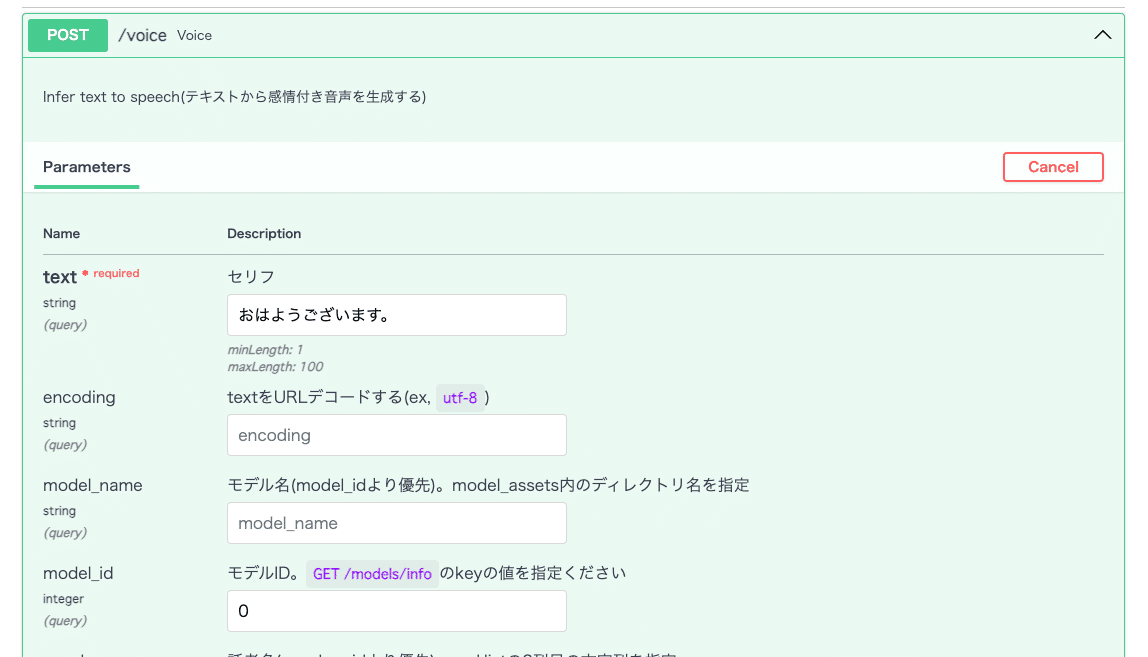
下にスクロールして Execute をクリックすると合成音声が始まるはずです。
すぐに下記のように音声再生ボタンが表示されると思うのでクリックしてみます。
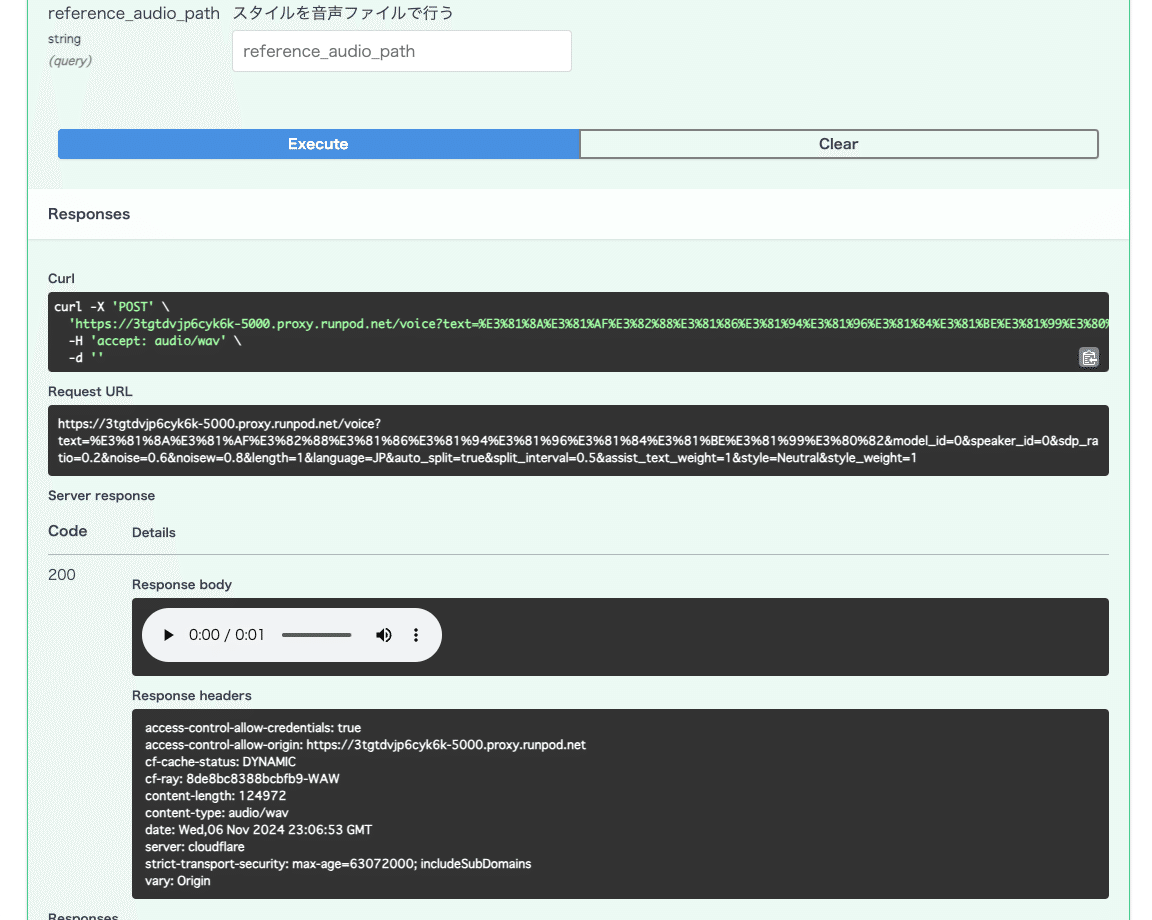
先程入力したテキストが再生されるはずです。
⚠ 使用したあとは必ずPodsを削除するのを忘れないでください。使用時間に応じて課金が発生するので、忘れると購入したクレジットをすべて使い切ってしまう可能性があります。
削除は左下のゴミ箱ボタンからできます。
また使用する場合はPodsのデプロイから再度行ってください。
TIPS: 独自のモデルを設定したい場合
ご自身で生成されたモデルがある方は次の手順で追加してください。
1.モデルファイルをフォルダごと /model_assets に追加する

2.上記の手順の Dockerイメージのビルド&デプロイ を再度実行する
なお、2回目以降のときは念の為 deploy.sh ファイルのバージョンの部分を変更しておくことをオススメします。
3.RunPodでサーバーをデプロイする
バージョンを変更した場合はTemplatesのバージョンも変更するのを忘れずに。
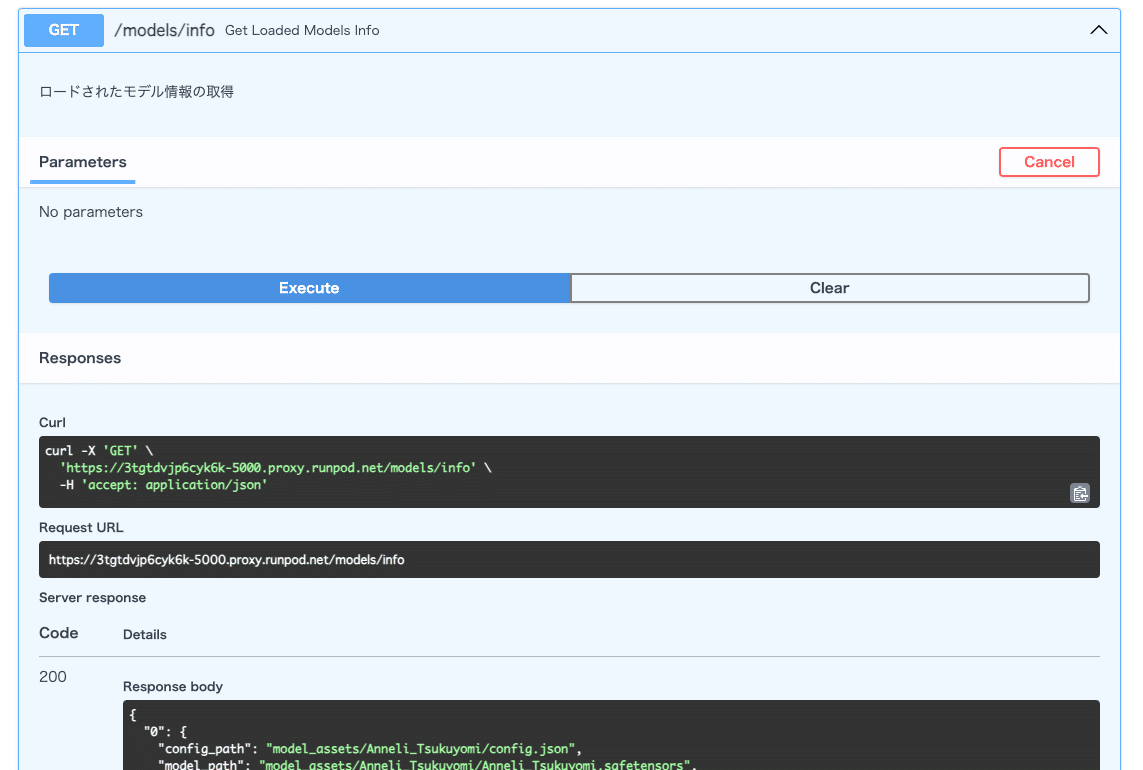
4.Docsで番号を確認する
追加したモデルは番号が割り振られるのでそれを確認します。
/models/info エンドポイントを Execute すると追加したモデルが何番かわかります。
5.音声を再生する
番号を控えたら、先程の /voice で speaker_id の部分を変更します。
この状態で Execute したら追加したモデルで音声が合成されるはずです。
AIキャラと対話してみる
Style-Bert-VITS2をサーバーに立てるという目的はこれで完了しましたが、せっかくなのでこちらを使用してAIキャラと対話してみましょう。
今回は私が開発しているOSSのAITuberKitを使用します。
事前準備
使用方法に関してはこちらを参考にしてください。
会話開始!の辺りまで読んでもらえると何となく概要がつかめると思います。
なお、AIサービスに関してはお好きなものを選択いただければよいですが、せっかくStyle-Bert-VITS2の高速レスポンスを試したいので、LLMモデルについてもできるだけ早いものを選択したほうがより感動できるでしょう。
オススメは下記です。
OpenAI: gpt-4o-mini
Anthropic: claude-3.5-haiku-20241022
Google: gemini-1.5-flash-latest
Style-Bert-VITS2を設定する
では次にStyle-Bert-VITS2を設定します。
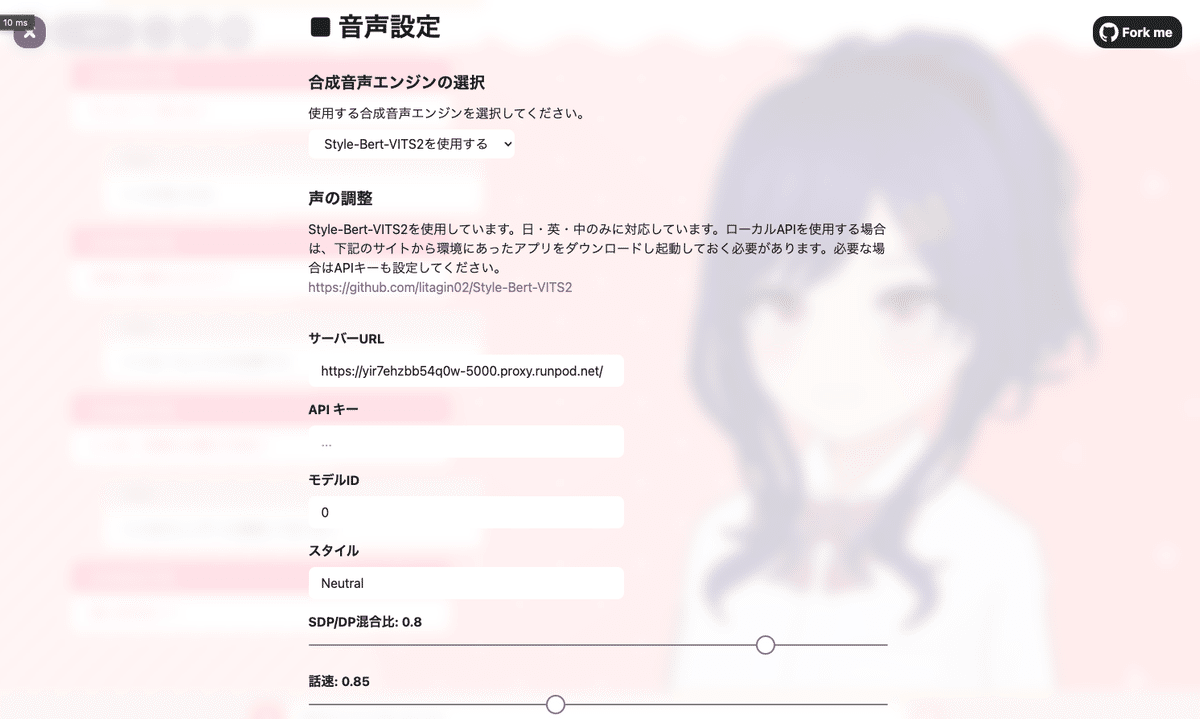
合成音声エンジンの選択で「Style-Bert-VITS2を使用する」を選びます。
サーバーURLには、先程 真っ暗な画面に {"detail":"Not Found"} のみが表示されたと思いますが、そのときのURLを入力します。
下記のような感じになると思います。
https://xxxxxxxxxxxx-5000.proxy.runpod.net/
APIキーの部分は空欄のままで良いです。
モデルIDはお好みのものを指定してください。
その他は一旦そのままで良いです。
会話開始!!
ではこの状態で設定画面を閉じ、下のチャット欄から話しかけてみましょう。
1ターン目の回答は少し遅いかも知れませんが、2ターン目以降はおよそ1秒前後で発話が始まると思います(選択したLLMモデルに依存します)。
うおおおおおおお!!
— ニケちゃん@AIキャラ開発 (@tegnike) November 6, 2024
爆速(gemini-1.5-flash)x 爆速(SBV2 on GPUサーバー)の最強キャラ対話環境完成っだああああ!!! https://t.co/F67HhQ29v9 pic.twitter.com/kWtldMsS8K
宣伝
今回使用したAIキャラと簡単にチャットできるAITuberKitについて、もっと知りたい!もっとこんな機能が欲しい!という方がいたらぜひDiscordサーバーに参加してみてください🙇♀
日々開発進捗もつぶやいていたりするのでX(Twitter)もフォローしてもらえると嬉しいです🙌
いいなと思ったら応援しよう!
